Is there anything equivalent to a Last() Function
-
This is just a theoretical question so I don't have any actual DDL to share but hopefully the example I describe below is adequate enough to convey what it is I'm asking.
Is there anything equivalent to a Last(@SearchValue,@PrimaryKey) Function that can be used when other traditional aggregations like MIN() and MAX() are being used where @SearchValue is the item you want to return and @primarykey-2 is what you use to do that? Within a set of data where I've got a query using traditional aggregate functions to return MIN, Max, etc but with one of the items I need to return not the Max() value but the last value where @primarykey-2 (lets assume its a whole number that increments by 1 for each row and starts with the value 1) is used to determine what the LAST row is within the data set.
EXAMPLE: So if I have a 3 column table like this:
PrimaryKey, SearchValue, OtherNumericValue
And the rows look like this:
1, 20.50, 100
2, 50.25, 500
3, 40.55, 300
I could use MAX(OtherNumericValue) to get the value 300 but I don't want the Max() for SearchValue which would be 50.25 I want to get the LAST value which would be 40.55.
Kindest Regards,
Just say No to Facebook! -
There's the LAST_VALUE function. In order to return the "last value" (when the set is ordered by: OVER (ORDER BY ...)) across the entire window of rows (in this case there's no PARTITION BY so it's the entire table) it needs RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING. Something like this
drop table if exists #tTest;
go
CREATE TABLE #tTest(
PrimaryKey int primary key NOT NULL,
SearchValue decimal(14,2) not null,
OtherNumericValue int not null);
INSERT INTO #tTest VALUES
(1, 20.5, 100),
(2, 50.25, 500),
(3, 40.55, 300);
select *, last_value(SearchValue)
over (order by PrimaryKey
range between
unbounded preceding and
unbounded following) [Last Value]
from #tTest;PrimaryKeySearchValueOtherNumericValueLast Value
120.5010040.55
250.2550040.55
340.5530040.55Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
Steve - The problem is if I try to use that in the same query as traditional aggregate like Min and MAX it throws a fit because PrimaryKey is not in a GROUP BY or used in an aggregate. I need within the same query to be able to get MAX(OtehrNumericValue) but the Last_Value for SearchValue. I hope that makes sense
SOME BACKGROUND:
I'm being tasked with coming up with a way (a query for a report) that will return traditional Aggregate values on some columns using MAX() but the Last_Value on others because columns like SearchValue should always be the last value in the data (when the data is ordered by a date column) . I don't have anything yet because I realized when the criteria was given to me by the executives for a report they want that I had no way to get the Last Value. Your response of Last_Value() was great until I tired to then mix it (using our theoretical example) with MAX().
I don't have the source table yet because I've not built it because I'm not sure how to construct it. It will be populated with data from an outside source and that data will include columns in which the value can go up or down with each day/date and so for it I need to get the Last_Value where as some others it will be the MAX() that needs to be returned. While this theoretical example does not represent what i will eventually be working with it perfectly represents in a more simplified example of whats needed.
Thoughts? I know this can't be something new that's never come up in the SQL world before.
Thanks
Kindest Regards,
Just say No to Facebook! -
Yes the LAST_VALUE function is a windowing function. One way to summarize would be to use a common table expression.
with lv_cte(PrimaryKey, SearchValue, OtherNumericValue, LastValue) as (
select *, last_value(SearchValue)
over (order by PrimaryKey
range between
unbounded preceding and
unbounded following)
from #tTest)
select max(SearchValue) max_sv, max(LastValue) max_lv
from lv_cte;max_svmax_lv
50.2540.55Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
-
To get the equivalent of a last_value - you have to be able to define the order that determines first/last. If you can do that - then a simple CROSS APPLY with a TOP 1 and the appropriate ORDER BY will get you the results. To get the last value - use descending order - to get first value use ascending order.
You may need to repeat all of the tables in the outer query - it depends on what defines your first/last values for that column.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
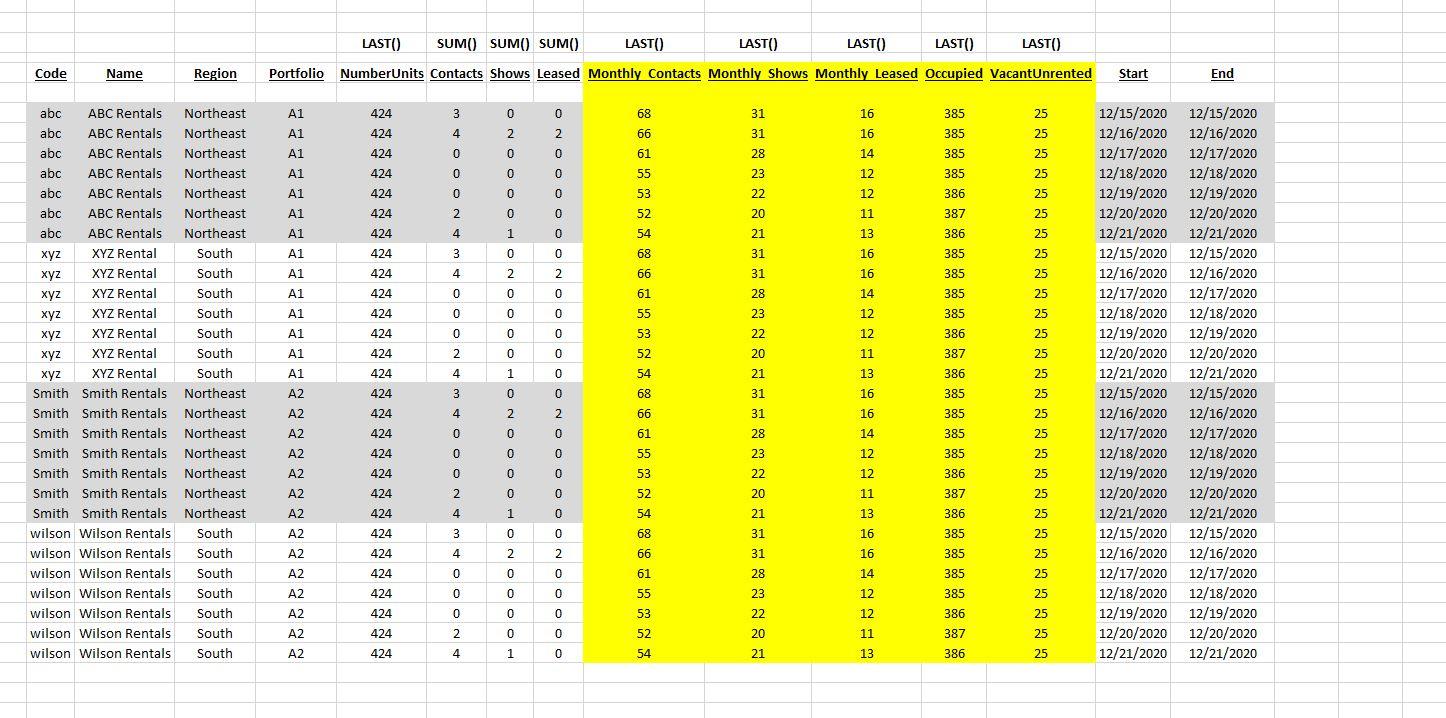
Jeff - We're still in the mock-up stages of this so I don't have any actual DDL to share but I did make a mock-up in Excel of what the table that stores this data would look like and made notes on how each item would be handled. I also did a mock-up of how the report that uses this data would look so you can see how that data is then used.
I don't think what you are proposing will work because of other requirements but I'd love to be wrong. In the below image there are 4 entities (Rental places - think storage units) and each has 7 rows of sample date, 1 row per data for 2020/12/15 thru 2020/12/21. I've used light grey background shading to more easily show the 4 entities rows of data. This is just dummy data to have something to work with. The Start and End dates are not pulled in with the data they are just criteria to determine what rows will be pulled in.
When the user runs the report they will select how to group and sort the data by; either Region or Portfolio. In this example there are 4 entities with 7 days so we have 28 rows that would then be shown in the report as 4 rows (1 per property) . The Reporting Software will handle the grouping/aggregation of the totals from each entity so the SQL Query just needs to get to the report software 1 row per entity with the correct totals and Last Value in the case of those items (highlighted in yellow) that are running totals that can go up or down and so we need the Last Value from each.
The End date would be used to determine the ordering (we'd need the value from the row with the highest date value per entity) . With the Reporting Software handling the grouping and sorting I can set the SQL Query to use whatever order by is necessary. My concern is can that technique your describing still work when we have to get the Last() on some items but Sum() /Min()/Max() on others when we have more then 1 entity?
Based on this do you still think your idea with using Cross Apply and top 1 would work? If yes can you point me to an example using it which I have no doubt you've already done one for in the past ion this site.

Kindest Regards,
Just say No to Facebook! -
Since you have this mocked up data - you can use that same data to build out a temp table with the associated data. Once you have that and posted it here we can work on providing examples.
And yes - CROSS APPLY can be used to return the last value, first value, min, max, sum, avg - or any other combination needed. You would just have multiple cross applies - one for last value and one for sum.
As you will be totaling that up in a report, that is where it should be done - but, it could also be done in a query using GROUPING SETS. Again, examples can be provided if you can provide the data in your mock up.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
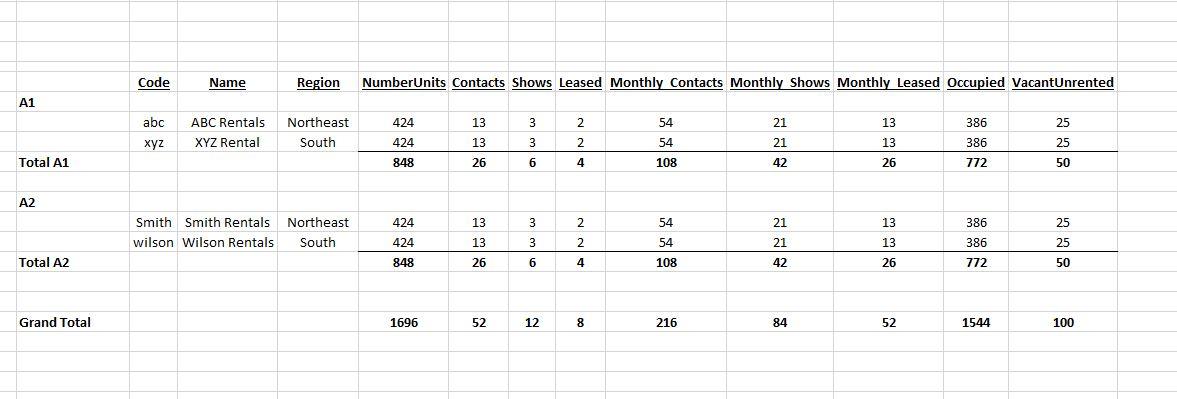
I put this together - based on the data you have we can get the results you are looking for with this:
Declare @mockTable Table (
Code varchar(20)
, [Name] varchar(30)
, Region varchar(30)
, Portfolio char(2)
, NumberOfUnits int
, Contacts int
, Shows int
, Leased int
, MonthlyContacts int
, MonthlyShows int
, MonthlyLeased int
, Occupied int
, VacantUnrented int
, StartDate date
, EndDate date
);
Insert Into @mockTable
Values ('abc', 'ABC Rentals', 'Northeast', 'A1', 424, 3, 0, 0, 68, 31, 16, 385, 25, '2020-12-15', '2020-12-15')
, ('abc', 'ABC Rentals', 'Northeast', 'A1', 424, 4, 2, 2, 66, 31, 16, 385, 25, '2020-12-16', '2020-12-16')
, ('abc', 'ABC Rentals', 'Northeast', 'A1', 424, 0, 0, 0, 61, 28, 14, 385, 25, '2020-12-17', '2020-12-17')
, ('abc', 'ABC Rentals', 'Northeast', 'A1', 424, 0, 0, 0, 55, 23, 12, 385, 25, '2020-12-18', '2020-12-18')
, ('abc', 'ABC Rentals', 'Northeast', 'A1', 424, 0, 0, 0, 53, 22, 12, 386, 25, '2020-12-19', '2020-12-19')
, ('abc', 'ABC Rentals', 'Northeast', 'A1', 424, 2, 0, 0, 52, 20, 11, 387, 25, '2020-12-20', '2020-12-20')
, ('abc', 'ABC Rentals', 'Northeast', 'A1', 424, 4, 1, 0, 54, 21, 13, 386, 25, '2020-12-21', '2020-12-21')
, ('xyz', 'XYZ Rentals', 'South', 'A1', 424, 3, 0, 0, 68, 31, 16, 385, 25, '2020-12-15', '2020-12-15')
, ('xyz', 'XYZ Rentals', 'South', 'A1', 424, 4, 2, 2, 66, 31, 16, 385, 25, '2020-12-16', '2020-12-16')
, ('xyz', 'XYZ Rentals', 'South', 'A1', 424, 0, 0, 0, 61, 28, 14, 385, 25, '2020-12-17', '2020-12-17')
, ('xyz', 'XYZ Rentals', 'South', 'A1', 424, 0, 0, 0, 55, 23, 12, 385, 25, '2020-12-18', '2020-12-18')
, ('xyz', 'XYZ Rentals', 'South', 'A1', 424, 0, 0, 0, 53, 22, 12, 386, 25, '2020-12-19', '2020-12-19')
, ('xyz', 'XYZ Rentals', 'South', 'A1', 424, 2, 0, 0, 52, 20, 11, 387, 25, '2020-12-20', '2020-12-20')
, ('xyz', 'XYZ Rentals', 'South', 'A1', 424, 4, 1, 0, 54, 21, 13, 386, 25, '2020-12-21', '2020-12-21')
, ('Smith', 'Smith Rentals', 'Northeast', 'A2', 424, 3, 0, 0, 68, 31, 16, 385, 25, '2020-12-15', '2020-12-15')
, ('Smith', 'Smith Rentals', 'Northeast', 'A2', 424, 4, 2, 2, 66, 31, 16, 385, 25, '2020-12-16', '2020-12-16')
, ('Smith', 'Smith Rentals', 'Northeast', 'A2', 424, 0, 0, 0, 61, 28, 14, 385, 25, '2020-12-17', '2020-12-17')
, ('Smith', 'Smith Rentals', 'Northeast', 'A2', 424, 0, 0, 0, 55, 23, 12, 385, 25, '2020-12-18', '2020-12-18')
, ('Smith', 'Smith Rentals', 'Northeast', 'A2', 424, 0, 0, 0, 53, 22, 12, 386, 25, '2020-12-19', '2020-12-19')
, ('Smith', 'Smith Rentals', 'Northeast', 'A2', 424, 2, 0, 0, 52, 20, 11, 387, 25, '2020-12-20', '2020-12-20')
, ('Smith', 'Smith Rentals', 'Northeast', 'A2', 424, 4, 1, 0, 54, 21, 13, 386, 25, '2020-12-21', '2020-12-21')
, ('Wilson', 'Wilson Rentals', 'South', 'A2', 424, 3, 0, 0, 68, 31, 16, 385, 25, '2020-12-15', '2020-12-15')
, ('Wilson', 'Wilson Rentals', 'South', 'A2', 424, 4, 2, 2, 66, 31, 16, 385, 25, '2020-12-16', '2020-12-16')
, ('Wilson', 'Wilson Rentals', 'South', 'A2', 424, 0, 0, 0, 61, 28, 14, 385, 25, '2020-12-17', '2020-12-17')
, ('Wilson', 'Wilson Rentals', 'South', 'A2', 424, 0, 0, 0, 55, 23, 12, 385, 25, '2020-12-18', '2020-12-18')
, ('Wilson', 'Wilson Rentals', 'South', 'A2', 424, 0, 0, 0, 53, 22, 12, 386, 25, '2020-12-19', '2020-12-19')
, ('Wilson', 'Wilson Rentals', 'South', 'A2', 424, 2, 0, 0, 52, 20, 11, 387, 25, '2020-12-20', '2020-12-20')
, ('Wilson', 'Wilson Rentals', 'South', 'A2', 424, 4, 1, 0, 54, 21, 13, 386, 25, '2020-12-21', '2020-12-21')
;
With baseUnits
As (
Select Distinct
mt.Code
, mt.Name
, mt.Region
, mt.Portfolio
From @mockTable mt
)
Select bu.Code
, bu.Name
, bu.Region
, bu.Portfolio
, NumberOfUnits = sum(u.NumberOfUnits)
, Contacts = sum(s.Contacts)
, Shows = sum(s.Shows)
, Leased = sum(s.Leased)
From baseUnits bu
Cross Apply (Select Top 1
lv.NumberOfUnits
From @mockTable lv
Where lv.Code = bu.Code
And lv.Name = bu.Name
And lv.Region = bu.Region
And lv.Portfolio = bu.Portfolio
Order By
lv.StartDate desc
) u
Cross Apply (Select Contacts = sum(lv.Contacts)
, Shows = sum(lv.Shows)
, Leased = sum(lv.Leased)
From @mockTable lv
Where lv.Code = bu.Code
And lv.Name = bu.Name
And lv.Region = bu.Region
And lv.Portfolio = bu.Portfolio
) s
Group By Grouping Sets (
()
, (bu.Portfolio)
, (bu.Code, bu.Name, bu.Region, bu.Portfolio)
);Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
CROSS APPLYrequires reading the same table twice. You can do this by only reading the table once. It involves concatenating the order fields and the value field together (possibly converting to BINARY or CHAR first), taking the MAX/MIN of that combined value, getting the substring that corresponds to the value field, and then converting back to it's initial data type. Something like the followingSELECT CAST(SUBSTRING(MAX(CAST(your_datetime_field as BINARY(5) + CAST(your_value_field AS BINARY(4)), 6, 4) AS INT)
J. Drew Allen
Business Intelligence Analyst
Philadelphia, PA - Steve Collins wrote:
There's the LAST_VALUE function. In order to return the "last value" (when the set is ordered by: OVER (ORDER BY ...)) across the entire window of rows (in this case there's no PARTITION BY so it's the entire table) it needs RANGE BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING. Something like this
drop table if exists #tTest;
go
CREATE TABLE #tTest(
PrimaryKey int primary key NOT NULL,
SearchValue decimal(14,2) not null,
OtherNumericValue int not null);
INSERT INTO #tTest VALUES
(1, 20.5, 100),
(2, 50.25, 500),
(3, 40.55, 300);
select *, last_value(SearchValue)
over (order by PrimaryKey
range between
unbounded preceding and
unbounded following) [Last Value]
from #tTest;PrimaryKeySearchValueOtherNumericValueLast Value
120.5010040.55
250.2550040.55
340.5530040.55You know that the
LAST_VALUE()is NEVER going to be before theCURRENT ROW, so it's completely unnecessary to specify the beginning of the window asUNBOUNDED PRECEDINGwhenCURRENT ROWwill work perfectly adequately.Drew
J. Drew Allen
Business Intelligence Analyst
Philadelphia, PA -
The thing above (which you posted) is actually "just" a CROSSTAB (which will have a GROUP BY) with a ROLLUP. With the help of the GROUPING() function, you can even tell it to do things like you did in the first column. It won't underline your data like it does in a spreadsheet but all the data and the sub-totals will be auto-magic.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
The thing above (which you posted) is actually "just" a CROSSTAB (which will have a GROUP BY) with a ROLLUP. With the help of the GROUPING() function, you can even tell it to do things like you did in the first column. It won't underline your data like it does in a spreadsheet but all the data and the sub-totals will be auto-magic.
Actually - this isn't a CROSS TAB because he isn't pivoting any data to other columns. There are 2 requirements - the first requirement is to get the SUM for 3 different columns - and get the latest row for the other columns (last_value). The problem is that you cannot perform a SUM over a windowed function (last_value) - and the desired goal is to SUM the last_value for each partition.
If we don't bother with returning all the totals - then we can just do this:
Select mt.Code
, mt.Name
, mt.Region
, mt.Portfolio
, NumberOfUnits = max(u.NumberOfUnits)
, Contacts = sum(mt.Contacts)
, Shows = sum(mt.Shows)
, Leased = sum(mt.Leased)
From @mockTable mt
Cross Apply (Select Top 1
lv.NumberOfUnits
From @mockTable lv
Where lv.Code = mt.Code
And lv.Name = mt.Name
And lv.Region = mt.Region
And lv.Portfolio = mt.Portfolio
Order By
lv.StartDate desc
) u
Group By
mt.Code
, mt.Name
, mt.Region
, mt.Portfolio;Then in the report the totals can be calculated as needed for any rollup and formatting.
The first solution I provided shows how to do this and get all the totals using GROUPING SETS - which isn't necessary since the data will feed a report that can then total as needed.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs -
Ah... you're correct. No pivots required for this problem so no Cross Tab (although the code is nearly identical... just missing a CASE in each sum for the non-CROSSTAB stuff). You can still use WITH ROLLUP (or the Grouping Sets you speak of) to get all of the sub-totals and grand total and, either way, you can use the Grouping() function to control what gets displayed and when for things like that first column.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
Ah... you're correct. No pivots required for this problem so no Cross Tab (although the code is nearly identical... just missing a CASE in each sum for the non-CROSSTAB stuff). You can still use WITH ROLLUP (or the Grouping Sets you speak of) to get all of the sub-totals and grand total and, either way, you can use the Grouping() function to control what gets displayed and when for things like that first column.
Yes - you can get the totals as outlined in his example using grouping...but that doesn't solve the problem of getting the last value for those specific columns. Another approach would be:
Select Top 1 With Ties
mt.Code
, mt.Name
, mt.Region
, mt.Portfolio
, mt.NumberOfUnits
, Contacts = sum(mt.Contacts) over(Partition By mt.Code, mt.Name, mt.Region, mt.Portfolio)
, Shows = sum(mt.Shows) over(Partition By mt.Code, mt.Name, mt.Region, mt.Portfolio)
, Leased = sum(mt.Leased) over(Partition By mt.Code, mt.Name, mt.Region, mt.Portfolio)
From @mockTable mt
Order By
row_number() over(Partition By mt.Code, mt.Name, mt.Region, mt.Portfolio Order By mt.StartDate desc);This also gets the raw data for the report...but I really don't know which one would be the most efficient and testing over the full set of data would be needed.
We could do the above in a CTE and then wrap that with a group by or grouping sets for the overall totals.
Jeffrey Williams
“We are all faced with a series of great opportunities brilliantly disguised as impossible situations.”― Charles R. Swindoll
How to post questions to get better answers faster
Managing Transaction Logs - drew.allen wrote:
You know that the
LAST_VALUE()is NEVER going to be before theCURRENT ROW, so it's completely unnecessary to specify the beginning of the window asUNBOUNDED PRECEDINGwhenCURRENT ROWwill work perfectly adequately.Drew
Well I disagree. The partition is correctly described in the code. Sufficiency is not the obviously preferred substitute for completeness. Also, it's frequently useful to recall SQL is an interpreted language.
Aus dem Paradies, das Cantor uns geschaffen, soll uns niemand vertreiben können
Viewing 15 posts - 1 through 15 (of 18 total)
You must be logged in to reply to this topic. Login to reply