Can anyone explain the design decision here?
-
If you do create a tally table, page compress it at 100 fillfactor. That will save significantly on the overhead of reading the table. And, since that table is static, it won't have any fragmentation issues.
I would point out that my code returns the same results for years. I've never had any performance issue generating 1000 tally rows or less with inline ctes. I prefer to name them "tallynnn" so the purpose of them is clear. I greatly prefer self-documenting code via meaningful names whenever possible.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
- Jeffrey Williams wrote:
@JeffModen - your solution and my solution are very close to the same. If we pass in 2022 as the starting year - both version return an empty set. If we pass in 2021 both version return a single row for 2021...
Try a phat-phingering of a 1, 2 or 3 digit year or a 4 digit year less than 1753 or even a negative number to see one of the differences.
Jeffrey Williams wrote:In my version, I include a checksum to wrap the row_number function - this is to prevent implicit conversions from int to bigint (the return value from row_number is a bigint) that could cause issues with the cardinality estimator.
Agreed and you definitely picked the right function to do so. I used to (long ago) include a conversion of the result of ROW_NUMBER() from BIGINT to INT for the very same reason. I have, however, not found a consistent difference when implicit conversions between INT and BIGINT occur insofar as performance and resource usage for when an inline cCTE is used nor when the cCTE is in the form of an fnTally function. That's not to say that there couldn't be a difference... I just haven't run into that particular problem in such cases yet and so avoided the extra clock cycle or two that CHECKSUM uses.
Just for others reading this, the trick with CHECKSUM that Jeffrey used is actually faster than an explicit CONVERT(INT,somevalue). I use that method for converting NEWID() to an INT to increase the performance when generating millions of row of random but constrained data for testing. Note that CHECKSUM does return an INT and can't be used for conversions that require BIGINT.
[/quote]
Jeffrey Williams wrote:As far as I can tell - the only portion of your check in the TOP statement that is needed is the check for years between 1753 and 9999. In my version we can address that the same way - or we can change to this and return a date data type: datefromparts(d.[Year], 1, 1).
I would absolutely agree with that evaluation from a logical standpoint and started out by not including the extra check. However, the extra check needs to be included because the range check doesn't check if you're going to come up with a negative value for the TOP. The other check does. Remove the extra check and then try a phat-phingered start year of 3000 and see.
Jeffrey Williams wrote:My version calculates the year in the 'tally' portion so it doesn't have to be re-calculated on output. In your version, you use DATEADD twice and an additional YEAR function.
That's true. I used a traditional form of having the "Tally" part be separated from the rest of the code and I'm counting on it acting as a "runtime constant" the first time it's calculated. I'd normally "DRY" out the code as you did but left it separate this time. The execution plans for both our code comes out right at 50% but you also know how I feel about that. I'll have to test and see if my guess is correct or not. I've seen it get "calculated twice" even when it's been dried out in a CTE unless a blocking-operator is present in the CTE.
As a bit of a sidebar, I keep forgetting about DATEFROMPARTs and need to start using it more often because it is a fair bit faster than using DATEADD especially at scale. Thanks you for the reminder there with your code.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:Jeffrey Williams wrote:
@JeffModen - your solution and my solution are very close to the same. If we pass in 2022 as the starting year - both version return an empty set. If we pass in 2021 both version return a single row for 2021...
Try a phat-phingering of a 1, 2 or 3 digit year or a 4 digit year less than 1753 or even a negative number to see one of the differences.
Jeffrey Williams wrote:In my version, I include a checksum to wrap the row_number function - this is to prevent implicit conversions from int to bigint (the return value from row_number is a bigint) that could cause issues with the cardinality estimator.
Agreed and you definitely picked the right function to do so. I used to (long ago) include a conversion of the result of ROW_NUMBER() from BIGINT to INT for the very same reason. I have, however, not found a consistent difference when implicit conversions between INT and BIGINT occur insofar as performance and resource usage for when an inline cCTE is used nor when the cCTE is in the form of an fnTally function. That's not to say that there couldn't be a difference... I just haven't run into that particular problem in such cases yet and so avoided the extra clock cycle or two that CHECKSUM uses.
Just for others reading this, the trick with CHECKSUM that Jeffrey used is actually faster than an explicit CONVERT(INT,somevalue). I use that method for converting NEWID() to an INT to increase the performance when generating millions of row of random but constrained data for testing. Note that CHECKSUM does return an INT and can't be used for conversions that require BIGINT.
Jeffrey Williams wrote:As far as I can tell - the only portion of your check in the TOP statement that is needed is the check for years between 1753 and 9999. In my version we can address that the same way - or we can change to this and return a date data type: datefromparts(d.[Year], 1, 1).
I would absolutely agree with that evaluation from a logical standpoint and started out by not including the extra check. However, the extra check needs to be included because the range check doesn't check if you're going to come up with a negative value for the TOP. The other check does. Remove the extra check and then try a phat-phingered start year of 3000 and see.
Jeffrey Williams wrote:My version calculates the year in the 'tally' portion so it doesn't have to be re-calculated on output. In your version, you use DATEADD twice and an additional YEAR function.
That's true. I used a traditional form of having the "Tally" part be separated from the rest of the code and I'm counting on it acting as a "runtime constant" the first time it's calculated. I'd normally "DRY" out the code as you did but left it separate this time. The execution plans for both our code comes out right at 50% but you also know how I feel about that. I'll have to test and see if my guess is correct or not. I've seen it get "calculated twice" even when it's been dried out in a CTE unless a blocking-operator is present in the CTE.
As a bit of a sidebar, I keep forgetting about DATEFROMPARTs and need to start using it more often because it is a fair bit faster than using DATEADD especially at scale. Thanks you for the reminder there with your code.
Getting back to "optimizations", I wondered if any of the optimizations mentioned would actually make a difference for these types of functions. Will "DRY" formulas improve performance? Will using Checksum as a quick conversion to INT help? Etc, etc.
So, here's some code I wrote to do some tests. Details are in the flower box.
/**********************************************************************************************************************
REF: https://www.sqlservercentral.com/forums/topic/can-anyone-explain-the-design-decision-here
The purpose of this code is to test the performance of several performance claims. Those claims are...
1. DRYing out code. In other words, is it more effective to do a single calculation within a cCTE or do nearly
identical calculations outside of the cCTE?
2. Is there an advantage to converting the output of the cCTE to an INT to prevent "Implicit Casts" from BIGINT to INT
if there's no direct usage of the generated sequence outside of the function?
3. Are there any advantages to using an INLINE numeric sequence generator (simto a Tally Functiomn) compare to using
an external fnTally function?
The tests in this code all generate every hour in the entire date range(72,291,696 total rows that the DATETIME
datatype can handle. The large number of rows was necessary in order to see any real differences in performance in the
code while using demonstrably repeatable, non-random data because all of the tests run very fast on today's machines.
Each test does a checkpoint, clears proc cache, and data cache at the begining of the run and then the test code
executes 5 times to see if there's any large resource usage on the compile associated with the first run and to
provide enough runs to discount any anomolies that may occur from other processes on the test box.
All but one of the tests use identical 10X base 10 CROSS JOINs as the numeric sequence generator. The different on
uses an fnTally iTVF based on 4X base 256 CROSS JOINs and can take an optional first parameter to start at either 0
or 1 with little difference in performamce.
The code does not have any built in measurments of performance. You need to use SQL Server Profiler or Extended events
to measure the Duration, CPU, Reads, Writes, and RowCounts to help minimize the impact of the "If you measure it, you
change it" syndrome.
Also note that when the '1753' shortcut is resolved to a DATETAME, it renders out as a date of 17530101 (yyyymmdd).
**********************************************************************************************************************/
--===== Calculate Twice (Inline) ======================================================================================
--===== This code calculates the DATETIME hour twice outside of the cCTE...
-- Once for the Date column and once for the year column.
--===== Clear the guns
CHECKPOINT;
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
GO
DECLARE @BitBucket1 DATETIME
,@BitBucket2 INT
;
WITH
E1(N) AS (SELECT 1 FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1))E0(N)) --Creates up to 10 rows
,Tally(N) AS (--==== "Pseudo Cursor" to create numbers from 0 to 72,291,696.
SELECT TOP (DATEDIFF(hh,'1753','99991231 23:59')+1)
ROW_NUMBER() OVER (ORDER BY @@SPID)-1
FROM E1 a, E1 b ,E1 c, E1 d, E1 e, E1 f, E1 g, E1 h) --10^8 = 100,000,000 max. rows
SELECT @BitBucket1 = DATEADD(hh,t.N,'1753')
,@BitBucket2 = YEAR(DATEADD(hh,t.N,'1753'))
FROM Tally t
;
GO 5
--===== Calculate once (DRY) ==========================================================================================
--===== This code calculates the DATETIME hour once inside of the cCTE and uses the result twice outside the cCTE...
-- Once for the Date column and once for the year column.
--===== Clear the guns
CHECKPOINT;
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
GO
DECLARE @BitBucket1 DATETIME
,@BitBucket2 INT
;
WITH
E1(N) AS (SELECT 1 FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1))E0(N)) --Creates up to 10 rows
,Tally(DT) AS (--==== "Pseudo Cursor" to create numbers from 0 to 72,291,696.
SELECT TOP (DATEDIFF(hh,'1753','99991231 23:59')+1)
DATEADD(hh,ROW_NUMBER() OVER (ORDER BY @@SPID)-1,'1753')
FROM E1 a, E1 b ,E1 c, E1 d, E1 e, E1 f, E1 g, E1 h) --10^8 = 100,000,000 max. rows
SELECT @BitBucket1 = t.DT
,@BitBucket2 = YEAR(t.DT)
FROM Tally t
;
GO 5
--===== Calculate once (DRY w/CHECKSUM) ===============================================================================
--===== This code is identical to the "Calculate once (DRY)" test code except that CHECKSUM()
--===== Clear the guns
CHECKPOINT;
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
GO
DECLARE @BitBucket1 DATETIME
,@BitBucket2 INT
;
WITH
E1(N) AS (SELECT 1 FROM (VALUES (1),(1),(1),(1),(1),(1),(1),(1),(1),(1))E0(N)) --Creates up to 10 rows
,Tally(DT) AS (--==== "Pseudo Cursor" to create numbers from 0 to 72,291,696.
SELECT TOP (DATEDIFF(hh,'1753','99991231 23:59')+1)
DATEADD(hh,CHECKSUM(ROW_NUMBER() OVER (ORDER BY @@SPID))-1,'1753')
FROM E1 a, E1 b ,E1 c, E1 d, E1 e, E1 f, E1 g, E1 h) --10^8 = 100,000,000 max. rows
SELECT @BitBucket1 = t.DT
,@BitBucket2 = YEAR(t.DT)
FROM Tally t
;
GO 5
--===== Calculate twice (fnTally) =====================================================================================
-- This uses the fnTally function (4X base 256), which can be found at the following URL ..
-- https://www.sqlservercentral.com/scripts/create-a-tally-function-fntally
-- and uses the result twice outside the function...
-- Once for the Date column and once for the year column.
-- Notice that we're using the "0" option, which means that we don't need to use -1 in any of the calculations
--===== Clear the guns
CHECKPOINT;
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
GO
DECLARE @BitBucket1 DATETIME
,@BitBucket2 INT
;
SELECT @BitBucket1 = DATEADD(hh,t.N,'1753')
,@BitBucket2 = YEAR(DATEADD(hh,t.N,'1753'))
FROM dbo.fnTallySSC(0,DATEDIFF(hh,'1753','99991231 23:59')) t
;
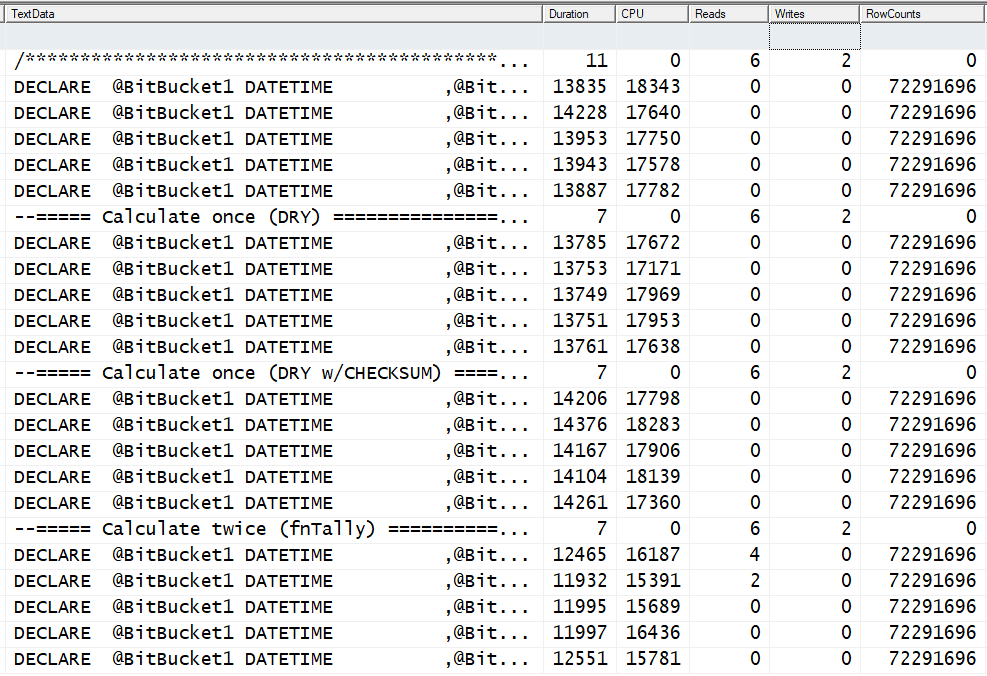
GO 5Here are the results from SQL Server Profiler...

To summarize, there's no performance advantages in DRYing out the code, in this case. It DOES provide a readability advantage, IMHO, which is the normal reason I do such a thing. I'll also DRY code out for other cCTEs if there's a proven performance advantage for an individual piece of code but it also usually requires the use of a blocking operator like a real SORT in the CTE (which also requires a TOP).
As I alluded to previously, although it's wise to be aware of the possible advantage of getting rid of implicit casts (using CHECKSUM in this case), it seems to provide no advantage in this case and has the disadvantage of making the code run slower because the explicit conversion costs more than the implicit conversions, in this case. Again, "It Depends".
Last but not least, is there any advantage to have the sequence generator live in the code rather than in a separate (for example) fnTally function? My answer is "No" except to make it standalone and not dependent on a external function. In fact, there are several disadvantages to using an inline sequence generator...
- There no performance advantage.
- There's the disadvantage of it making the code more complex compared to simply calling a function.
- There's the disadvantage of people not doing things the same way in such code.
- If a performance improvement comes up, you'd have to modify every function that uses such sequences instead of being able to make a single modification in a single function.
- Inline requires more training to get better performance. For example, all of the code uses "-1" to make the result of the ROW_NUMBER() function 0 based instead of 1 based. Most people won't know the trick of of embedding a SELECT N=0 UNION ALL to make the "-1" calculation unnecessary.
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:Kristen-173977 wrote:
I have an actual TALLY table in my database for Numbers ... is that bad? should I be using a Function?
The use of a physical Tally Table DOES cause some DBAs a concern because, especially with frequent use, causes a ton of Logical Reads (from memory). The reason why they concern themselves with that is that they (including me) will frequently use the number of Logical Reads as an indication of code that can probably be made better. The cCTE method produces zero reads on it's own
I (not a DBA) also reach for "logical reads" (and SCANS) as my first line of investigating performance issues. I can't remember ever investigating performance on a query that included Tally Table, so maybe I just got lucky not to have encountered that 🙂 Will be alert when it does happen though, thanks
ScottPletcher wrote:If you do create a tally table, page compress it at 100 fillfactor. That will save significantly on the overhead of reading the table. And, since that table is static, it won't have any fragmentation issues.
I don't know why I have this in my script which creates my Tally table, I expect I copied it from somewhere. I wonder if it is a good idea ... or not
CREATE TABLE dbo.MyTallyTable
(
MyNumber int NOT NULL,
CONSTRAINT [MyPKeyName] PRIMARY KEY CLUSTERED
(
[MyNumber]
) WITH FILLFACTOR = 100 ON [PRIMARY]
)
EXEC sp_indexoption 'dbo.MyTallyTable', 'disallowrowlocks', TRUE
EXEC sp_indexoption 'dbo.MyTallyTable', 'disallowpagelocks', TRUE
INSERT INTO MyTallyTable ...We don't use NOLOCK anywhere ... but is there any benefit using it on TallyTable given it is "read only" ?
- Kristen-173977 wrote:Jeff Moden wrote:Kristen-173977 wrote:
I have an actual TALLY table in my database for Numbers ... is that bad? should I be using a Function?
The use of a physical Tally Table DOES cause some DBAs a concern because, especially with frequent use, causes a ton of Logical Reads (from memory). The reason why they concern themselves with that is that they (including me) will frequently use the number of Logical Reads as an indication of code that can probably be made better. The cCTE method produces zero reads on it's own
I (not a DBA) also reach for "logical reads" (and SCANS) as my first line of investigating performance issues. I can't remember ever investigating performance on a query that included Tally Table, so maybe I just got lucky not to have encountered that 🙂 Will be alert when it does happen though, thanks.
The answer to that might be because of the same problem I have on most machines/databases... folks have so much (um... searching for the politically correct term for "crap code... um... oh yeah... got it) "performance challenged" code that the likes of the reads from a Tally table will never appear in the top 10 of the "code that needs to be looked at" list I generate for logical reads. 😀
--Jeff Moden
RBAR is pronounced "ree-bar" and is a "Modenism" for Row-By-Agonizing-Row.
First step towards the paradigm shift of writing Set Based code:
________Stop thinking about what you want to do to a ROW... think, instead, of what you want to do to a COLUMN.Change is inevitable... Change for the better is not.
Helpful Links:
How to post code problems
How to Post Performance Problems
Create a Tally Function (fnTally) - Jeff Moden wrote:
Most people won't know the trick of of embedding a SELECT N=0 UNION ALL to make the "-1" calculation unnecessary.
I do know that trick, and have used it myself, but I didn't bother with it for only 1000 rows. For larger number of rows, it's amazing how much overhead that "- 1" does cause. Of course I'd have no objection to using SELECT 0 AS number UNION ALL ... instead.
SQL DBA,SQL Server MVP(07, 08, 09) "It's a dog-eat-dog world, and I'm wearing Milk-Bone underwear." "Norm", on "Cheers". Also from "Cheers", from "Carla": "You need to know 3 things about Tortelli men: Tortelli men draw women like flies; Tortelli men treat women like flies; Tortelli men's brains are in their flies".
Viewing 6 posts - 31 through 36 (of 36 total)
You must be logged in to reply to this topic. Login to reply