

(If you’re reading this on SQL Server Central, please click here to see the “Featured Image” which will help explain the “Duck” vs “Rabbit” titles of this and the next posts)
So, the actual question is a bit more specific than would reasonably fit into a title, and it is:
In a WHERE condition (in Microsoft SQL Server, if that’s not obvious), when a string constant containing Unicode characters but not prefixed with a capital-N is compared to a column, which Collation (and hence Code Page) is used to do the implicit conversion of the Unicode characters into VARCHAR? Is it the Database’s default Collation, or the column’s Collation?
I know, I know. You’re probably thinking: “Duh! That’s so obvious. Why would anyone even bother asking such a silly question?” Well, the reason I asked is because I came across something the other day while I was fixing incorrect and misleading statements in the documentation for the HAVING clause via Pull Request #235: “Correct and improve HAVING clause”. In addition to updating the existing wording, I figured it would be nice to link to the page showing how to string multiple conditions together, just like in the WHERE clause. I found the page for “Search Condition” and skimmed it to make sure it had the expected content. That is when I saw the following note (in the “Arguments” section, highlighted in blue):
When referencing the Unicode character data types nchar, nvarchar, and ntext, ‘expression’ should be prefixed with the capital letter ‘N’. If ‘N’ is not specified, SQL Server converts the string to the code page that corresponds to the default collation of the database or column. Any characters not found in this code page are lost.
Well, there is a slight problem with that warning. Did you spot it? It’s subtle. Maybe try reading it again. I’ll wait. ………………………………………………………..
Ok, do you see it now? Yes, that’s it: of those three sentences in the note / warning, none of them are entirely correct. Sure, each sentence contains some amount of truth, but they are all wrong, each in its own way. Let’s look at them individually to see what the problems are:
- “ When referencing the Unicode character data types nchar, nvarchar, and ntext, ‘expression’ should be prefixed with the capital letter ‘N’. ”
While this statement is generally true on its own, it has nothing to do with the topic at hand: character conversions. The reason why you should use the ‘N’ prefix when dealing with NVARCHAR data (columns, variables, other string literals, etc) is to avoid the slight performance hit of the implicit conversion that will occur. Due to Datatype Precedence, any VARCHAR data will automatically convert to NVARCHAR when intermixed. But again, and as we shall see, this has nothing to do with the characters being used in the string literal.
Of course, when you reference non-Unicode character datatypes, then the potential exists for character transformations (that would not have otherwise happened).
Also, the term “expression” is defined, just above this note in the documentation, as “a column name, a constant, a function, a variable, a scalar subquery”. However, only a string constant / literal can be prefixed with a capital-“N”.
“ If ‘N’ is not specified, SQL Server converts the string to the code page that corresponds to the default collation of the database or column. ”
This sentence is the main issue. Like the previous sentence, it is generally true on its own (except that it would then be leaving out cases where the COLLATE keyword is used). Yes, if the string literal is not prefixed with a capital-
N, then it is a VARCHAR string and needs to exist within a Code Page. And yes, Code Pages are determined by the Collation being used. BUT, which Collation is used for string literals that reference VARCHAR columns does not switch between the Database’s or the column’s. It is always one of those two, and the other handles other situations.“ Any characters not found in this code page are lost. ”
Using the word “lost” here makes sense in that the characters might not be what they originally were, but the characters do not disappear or get removed from the string.
What happens to characters not specifically found in the Code Page being used is not as simple as is stated here. When converting characters from Unicode to an 8-bit Code Page, if a direct match cannot be found, the conversion process checks to see if there is a “Best Fit” mapping defined for the target Code Page. If there is a “Best Fit” mapping, then that mapping is checked first. If the Unicode character is listed in the “Best Fit” mapping, then the “approximate” character that it is mapped to for that Code Page is used. This is a type of “data loss” in that you no longer have the original character, but you should have something close enough to still convey the intended meaning.
In the case that either no “Best Fit” mapping exists for the target Code Page, or that a “Best Fit” mapping does exist but the source Unicode character is not listed in that mapping, then the source Unicode character is converted to the default replacement character: ?. Of course, if the source Unicode character is a supplementary character (which is comprised of two UTF-16 Code Points), then that will convert into two default replacement characters: ??.
Which one is it?

Consider the following scenario:
- We have a string literal that contains one or more characters that are not one of the 128 standard ASCII characters defined as values 0 – 127 across all Code Pages (or at least all Code Pages that one has access to within SQL Server), and
- The string literal is not prefixed with a capital-N, and
- The string literal is being compared to an NVARCHAR column (or to an expression derived from one or more NVARCHAR columns), and
- The column being compared to uses a different Collation than the Database in which the query is being executed (the current / active Database is usually of great importance, not just in this situation).
The documentation states that it will be one or the other: “the code page that corresponds to the default collation of the database or column”. Well, in order to find out if it is one or the other or both or even neither, we will consult the primary authority on this topic: SQL Server.
Test Setup
We will create a Database with one Collation and a Table in that Database with an NVARCHAR column having a different Collation than the Database’s. And, to verify my statements regarding “Best Fit” mapping, we will create an additional NVARCHAR column using a 3rd Collation. We will also throw in three VARCHAR columns, one for each of the three Collations being used, to have a more complete picture of the behavior.
CREATE DATABASE [WhichCollation] COLLATE Latin1_General_100_BIN2; ALTER DATABASE [WhichCollation] SET RECOVERY SIMPLE; USE [WhichCollation]; -- DROP TABLE dbo.WhichCollationIsIt; -- TRUNCATE TABLE dbo.WhichCollationIsIt; CREATE TABLE dbo.WhichCollationIsIt ( [Latin1_8bit] VARCHAR(10) COLLATE Latin1_General_100_BIN2, [Latin1_Unicode] NVARCHAR(10) COLLATE Latin1_General_100_BIN2, [Hebrew_8bit] VARCHAR(10) COLLATE Hebrew_100_BIN2, [Hebrew_Unicode] NVARCHAR(10) COLLATE Hebrew_100_BIN2, [Korean_8bit] VARCHAR(10) COLLATE Korean_100_BIN2, [Korean_Unicode] NVARCHAR(10) COLLATE Korean_100_BIN2 );
Some notes:
- We are starting with a Collation of Latin1_General_100_BIN2 for the Database, and will be using it along with Hebrew_100_BIN2 and Korean_100_BIN2 for the columns in the test Table.
- I prefer to use the most recent version of any particular Collation, hence the “100” in each of those Collation names. Not all Collations have a “100” version, so maybe “90” or nothing is the most recent. The “100” series were added in SQL Server 2008 (100 = “10.0” which is the SQL Server version number for 2008). Currently, the “140” series is the most recent, added in SQL Server 2017 (140 = “14.0”), but that only covers some of the Japanese Collations.
- I am using binary Collations (i.e. ending in _BIN2, which you should use instead of those ending with just _BIN ) to make sure that our tests are for exact matches only and not merely something that is considered equivalent.
Next, we will use the “Subscript Two” (Unicode Code Point U+2082) character, (e.g. “H₂O”) because it behaves differently in each of the three Collations that we are testing with. This, again, is why we are using a binary Collation: “Subscript 2” can match a regular number 2, a circled number 2, a superscript 2, etc), and we don’t want false-positives.
To conduct the test, we will use a Stored Procedure that compares the “Subscript 2” character to each combination of the two datatypes and three Collations. A Stored Procedure is being used since we will execute it several times.
GO
CREATE PROCEDURE dbo.CheckConversions
AS
SET NOCOUNT ON;
SELECT -- "Uni" == Unicode
[Latin1_8bit] AS [Latin1],
[Hebrew_8bit] AS [Hebrew],
[Korean_8bit] AS [Korean],
N'█' AS [█], -- visual group separator ( Full Block U+2588 )
IIF([Latin1_8bit] = '₂', 'Match', '') AS [Latin1],
IIF([Latin1_Unicode] = '₂', 'Match', '') AS [Latin1_Uni],
IIF([Hebrew_8bit] = '₂', 'Match', '') AS [Hebrew],
IIF([Hebrew_Unicode] = '₂', 'Match', '') AS [Hebrew_Uni],
IIF([Korean_8bit] = '₂', 'Match', '') AS [Korean],
IIF([Korean_Unicode] = '₂', 'Match', '') AS [Korean_Uni]
FROM dbo.WhichCollationIsIt;
GO
Next, we will insert that character into all of the string columns, and then look to see what is actually in each of those columns. The characters are inserted as NVARCHAR / Unicode to ensure that the source character is what we expect it to be.
INSERT INTO dbo.WhichCollationIsIt VALUES (N'₂', N'₂', N'₂', N'₂', N'₂', N'₂'); SELECT * FROM dbo.WhichCollationIsIt;
And that returns:

Here we have our first indication of differing behavior between the Collations. Looking at each of the “8bit” fields we can see that:
- Latin1_General (Code Page 1252) does not have the exact character, but it does have a “Best Fit” mapping, so it gets translated into a regular number “2”
- Hebrew (Code Page 1255) does not have the exact character, nor does it have a “Best Fit” mapping, so it gets translated into the default replacement character of “?”
- Korean (Code Page 949) does have this exact character, so no translation occurs. Code Page 949 is a Double-Byte Character Set so it has plenty more characters than the 256 that a Single-Byte Character Set holds.
Now that we see what the “Subscript 2” character can be translated into, we should add those two character to our sample data. This is to check if “Subscript 2” matches either “2” or “?” if it doesn’t match itself (due to being transformed).
-- Add potential matches
INSERT INTO dbo.WhichCollationIsIt
VALUES ('2', '2', '2', '2', '2', '2'), -- Possible "best fit" mapping
('?', '?', '?', '?', '?', '?'); -- If not in code page and
-- no "best fit" mapping
SELECT * FROM dbo.WhichCollationIsIt;
That returns:

Now we may officially begin testing.
Testing
Database Collation = Latin1_General_100_BIN2
When we execute:
EXEC dbo.CheckConversions;
the following is returned:

In the results shown above, we see that “Subscript 2” in a string literal that is not prefixed with a capital-“N” only matches a regular number “2”. The documentation said that it would be converted to “the Code Page specified by the Database or column”, but here it is only using the Code Page specified by the Database’s Collation (i.e. Code Page 1252 which is what the Latin1_General Collations use). If the Collation of the column being referenced was being used, then “Subscript 2” would still match the “2” in the Latin1 columns, but it would then match the “?” in the Hebrew columns, and it would match the “₂” in the Korean columns.
To see what is happening, let’s simply SELECT the string literal:
SELECT '₂';
-- 2 ("best fit" mapping for Code Page 1252)
SELECT '₂' COLLATE Korean_100_BIN2;
-- 2 ("best fit" mapping for Code Page 1252)
Both queries return a regular number “2”. This is, again, due to the Collation of the Database being used. That makes sense here since there is no column being referenced. But, even in the second query, the COLLATE keyword does not force it to remain a “₂”, even though “Subscript 2” exists in VARCHAR data in Code Page 949 (used by the Korean Collations).
This is because queries are parsed (for proper syntax, variable name resolution, etc.) before anything is done with the query. The datatype and value of any literal / constant, whether string or numeric, is determined during parsing. Hence, characters are translated (using the Collation of the Database) before any other Collation, whether from a column or COLLATE keyword, is determined or applied.
Let’s continue.
Database Collation = Hebrew_100_BIN2
Since we know that the Database’s Collation is used at least some of the time, we will change the Database’s Collation to Hebrew_100_BIN2 and see what is affected:
USE [master]; ALTER DATABASE [WhichCollation] COLLATE Hebrew_100_BIN2; USE [WhichCollation]; SELECT [name], [collation_name] FROM sys.columns WHERE [object_id] = OBJECT_ID(N'dbo.WhichCollationIsIt'); SELECT * FROM dbo.WhichCollationIsIt;
The two SELECT queries above are only there to show that changing the Database’s Collation did not change the Collation of, or the data in, any of the test Table’s columns. The first query returns the following:
| name | collation_name |
|---|---|
| Latin1_8bit | Latin1_General_100_BIN2 |
| Latin1_Unicode | Latin1_General_100_BIN2 |
| Hebrew_8bit | Hebrew_100_BIN2 |
| Hebrew_Unicode | Hebrew_100_BIN2 |
| Korean_8bit | Korean_100_BIN2 |
| Korean_Unicode | Korean_100_BIN2 |
The second query returns the same sample data rows that we saw before (final image prior to “Testing” header).
When we execute:
EXEC dbo.CheckConversions;
the following is returned:

This time, it is only the “?” that matches. This is due to the Hebrew Collations using Code Page 1255 which does not contain “Subscript 2”, and does not have a “Best Fit” mapping for it either. The behavior of only using the Database’s Collation is consistent with what we saw in the first test.
We can check what happens when we SELECT the string literal and no column is referenced:
SELECT '₂'; -- ? (no match and no "Best Fit" mapping) SELECT '₂' COLLATE Korean_100_BIN2; -- ? (no match and no "Best Fit" mapping)
The queries, along with their results, shown above also indicate that the translation happens before an explicit Collation is applied.
BUT, the documentation states “when an nvarchar datatype was referenced”, and yet there is no other datatype in the two queries above. Ok, fine. Let’s test what happens when the reference is in the context of string concatenation. We will concatenate with both Korean columns since Code Page 949 has the “Subscript 2” character. The resulting Collation should be the column’s Collation since string literals are coercable.
-- DROP TABLE #ConversionTest;
SELECT [Korean_8bit] + '₂' AS [ShouldBeVarcharKorean],
[Korean_Unicode] + '₂' AS [ShouldBeNVarcharKorean]
INTO #ConversionTest
FROM dbo.WhichCollationIsIt;
SELECT * FROM #ConversionTest;
That returns the following:
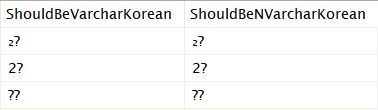
The referenced column being of a Code Page that contains the character did not help in either case, once again showing that the string literal is translated first, using the Collation of the current Database.
Not convinced that the resulting Collation is the column’s Collation? That’s easy to check (and is why the query creates a table to store the results in):
EXEC tempdb..sp_help N'#ConversionTest';
returns the following:
| Column_name | Type | Collation |
|---|---|---|
| ShouldBeVarcharKorean | varchar | Korean_100_BIN2 |
| ShouldBeNVarcharKorean | nvarchar | Korean_100_BIN2 |
That the literal’s Collation is coerced to the column’s Collation plays an even larger role in the next test.
Intermission
So far we have seen that VARCHAR string literals (i.e. those not prefixed with a capital-“N”) are always forced into the Code Page specified by the Database’s Collation. And, we haven’t seen the Collation of the referenced column have any effect. However, we still need to see what happens when the character is in the Code Page of the Database’s Collation, but not in the Code Page of the referenced column.
Regarding the warning in the Microsoft documentation: it’s safe to assume that they’re speaking in terms of starting with a string that is already in the Code Page of the Database’s Collation and would not experience any transformation outside of the referenced column situation that they are trying to warn about. However, they state that the transformation could be due to the Database’s Collation, so it is important to see that the Database’s Collation can have an effect, but does not have the effect that they are warning about.
Please tune in next time for the exciting conclusion of “Who’s Collation is it Anyway?”
