

Things go wrong in IT, it is no different with the cloud. When I say cloud I am thinking quite specific such as the underlying infrastructure that a company like Microsoft looks after for their Azure platform.
I took the below image from https://blogs.msdn.microsoft.com/psssql/2014/03/27/dont-rely-on-a-static-ip-address-for-your-sql-database/
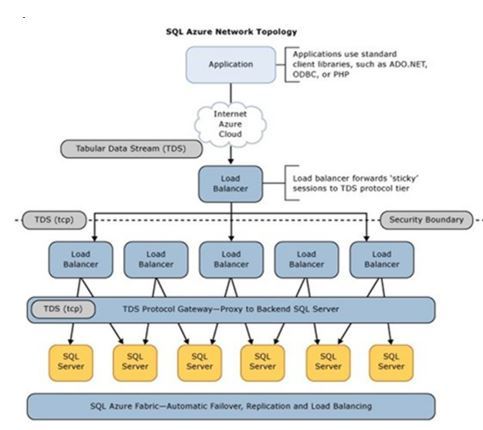
It shows the many different layers involved with a product like Azure SQL Database. What happens if there is a loss of service for a specific component? Obviously we as customers would not be able to fix the issue as this is the responsibility of Microsoft Engineers, the key for me is being kept in the loop with the issue and it is something that they do pretty well. So what happens if the load balancer has issues?
All communication is done via Service Health within the Azure portal.
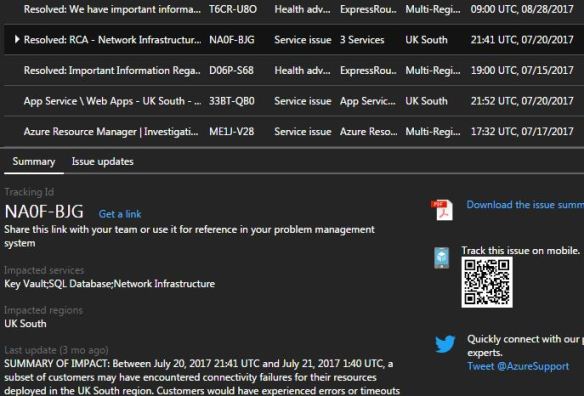
As you can see the top panel gives an overview of issues and warnings followed by a summary section. For this specific case ( in the past) the initial analysis can be found within the Issue updates link above. It stated
PRELIMINARY ROOT CAUSE AND MITIGATION:
You may experience connectivity issues to your databases as a result of downstream impact from a network infrastructure event. This may have included degraded performance, network drops, or time outs when accessing SQL Databases or other Azure resources hosted in this region. Engineers have determined that this was caused by an underlying Network Infrastructure event in this region. Engineers performed a failover of an unhealthy SLB (Software Load Balancer) scale unit to mitigate the issue and continue to investigate the underlying root cause. NEXT STEPS: Engineers will continue to investigate full root cause and a post incident report will be provided within approximately 72 hours.
DETAILED ROOT CAUSE
Frequent updates are given more specifically this time a more detailed ROOT CAUSE: The issue occurred when one of the instances of Azure Load Balancing service went down in the UK South region. The root cause of the issue was a bug in the Azure Load Balancing service. (This goes on into some depth).
NEXT STEPS
To put customers at ease Microsoft issue a NEXT STEP comment where they sincerely apologize for the impact to affected customers.
They go and state “We are continuously taking steps to improve the Microsoft Azure Platform and our processes to help ensure such incidents do not occur in the future. In this case, we will: 1. Roll out a fix to the bug which caused Azure Load Balancing instance data plane to crash. In the interim a temporary mitigation has been applied to prevent this bug from resurfacing in any other region”
Pretty good customer service – In my opinion (you can also track this via your mobile).
Filed under: Azure, Azure SQL DB Tagged: Azure, Azure SQL DB, SQL database, Support 






![]()
