

Today's story starts again with a page escalation:
--
We are seeing very high CPU usage on DistServer01. Could you please take a look and do a health check on this server? Please let us know if there is anything we can do to help.
--
I connnected to DistServer01 and, sure enough, there was consistently 99% CPU in Windows and 90%+ of it was from SQL Server.
 |
| https://i.imgflip.com/1mqb58.jpg |
As you may have guessed, DistServer01 was the Distributor in a very large transactional replication topology.
I checked the active processes looking for something that was abnormally long-running - no good.
I checked the processes again looking for something using high CPU. The top thing I found was a Distribution Agent for one of the many publications being routed through DistServer01. I stopped the SQL Agent job for the Distribution Agent - no good, so I resumed the job.
Next place to turn was that warm comfy place...the Glenn Berry DMV scripts!
 |
| http://s.quickmeme.com/img/50/50aefd57e50f2014dda55437e3637e9c9efd9c6b2f84a1ad7f0fa3937129794e.jpg |
I have heaped praise on Glenn (blog/@GlennAlanBerry) and his scripts before, and they are definitely my go-to when I dive into troubleshooting.
For high CPU an especially useful query is the "top worker time queries" query. This is the 2008R2 version (but it works on later versions as well):
--
-- Get top total worker time queries for entire instance (Query 33) (Top Worker Time Queries)
SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], t.[text] AS [Query Text],
qs.total_worker_time AS [Total Worker Time], qs.min_worker_time AS [Min Worker Time],
qs.total_worker_time/qs.execution_count AS [Avg Worker Time],
qs.max_worker_time AS [Max Worker Time], qs.execution_count AS [Execution Count],
qs.total_elapsed_time/qs.execution_count AS [Avg Elapsed Time],
qs.total_logical_reads/qs.execution_count AS [Avg Logical Reads],
qs.total_physical_reads/qs.execution_count AS [Avg Physical Reads], qs.creation_time AS [Creation Time]
, qp.query_plan AS [Query Plan] -- comment out this column if copying results to Excel
FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK)
CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t
CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp
ORDER BY qs.total_worker_time DESC OPTION (RECOMPILE);
--
The (truncated) results come out like this:
Database Name | Query Text | Total Worker Time | Min Worker Time | Avg Worker Time | Max Worker Time | Execution Count | Creation Time |
NULL | CREATE PROCEDURE sp_MSadd_replcmds( @para | 4224360546 | 0 | 3920 | 475776 | 1077642 | 05/12/2018 22:55:25 |
| NULL | -- -- Name: -- fn_repldecryptver4 -- -- Descrip | 1724660996 | 0 | 89 | 372022 | 19285577 | 05/12/2018 22:55:25 |
| NULL | -- -- Name: -- fn_MSrepl_isdistdb -- -- Desc | 1066486938 | 0 | 53 | 287015 | 19817134 | 05/12/2018 22:55:23 |
| NULL | create procedure sys.sp_MSispeertopeeragent ( | 845048463 | 0 | 43 | 203009 | 19276558 | 05/12/2018 22:55:26 |
| NULL | CREATE PROCEDURE sys.sp_MSadd_distribution_h | 796880096 | 0 | 490 | 368106 | 1623313 | 05/13/2018 03:50:07 |
| NULL | CREATE PROCEDURE sys.sp_MSget_subscription_gui | 527028755 | 0 | 27 | 379022 | 19260376 | 05/12/2018 22:55:27 |
| NULL | create procedure sys.sp_MSispeertopeeragent ( | 500954674 | 0 | 25 | 240012 | 19276558 | 05/12/2018 22:55:26 |
| distribution | CREATE PROCEDURE sp_MSdelete_publisherdb_trans | 434227603 | 0 | 204054 | 5019298 | 2128 | 05/12/2018 23:05:04 |
| master | SELECT target_data FROM sys.dm_xe_session_ | 342630497 | 55006 | 228116 | 963058 | 1502 | 05/13/2018 00:00:08 |
| msdb | CREATE PROCEDURE sp_sqlagent_has_server_access | 267846345 | 30999 | 763095 | 21321226 | 351 | 05/12/2018 22:55:18 |
As you can see here, the internal replication process sp_MSadd_replcmds was by far the largest total consumer of CPU, but its average CPU time was still relatively small - it was just called over a million times since the server was last started!
Just to be sure I checked the Missing/Recommended Indexes to make sure there wasn't a glaringly obvious recommendation (sometimes new indexes drastically help CPU) but there was not.
The next place to turn was the query plan...
 |
| https://imgflip.com/i/2ajq6z |
Query plans can be very complicated subjects. At the most basic level, query plans are the layout of how a query operates. It is what we see represented when we look at a graphical execution plan in Management Studio:
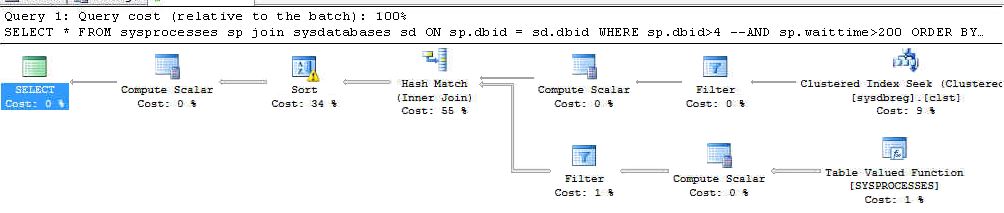
Query plans are created on first execution and then are stored in the plan cache on either the first or second execution of the query (depending on whether you have Optimize for Ad Hoc Workloads enabled).
This is beneficial a majority (a vast majority) of the time because generating the query plan takes much more resources that simply looking it up in cache. The catch is that not all similar queries need the same plan.
The simplest example to me relates to indexing (and is actually one of the reasons my first instinct was to look for missing indexes) - when performing a filtered query (meaning one with a WHERE clause) the amount of data being returned help shape the query plan. If the estimator expects a large portion of the rows in the table to be returned, it will often ignore nonclustered indexes and simply perform a table scan, checking each row to see if it meets the filter criteria and returning the appropriate rows. If the estimator expects a more narrow subset and there is a relevant nonclustered index in place, it generates a plan that performs a scan or seek of the nonclustered index and then performs lookups to return any columns not already included in the index.
The problem comes up when the plan that gets cached is built for one of these two cases that is the less frequent of the two. Using our example above let's say the first run of the query is the large resultset/table scan, which caches that plan. The next one million runs of the query are the narrow resultset that could have used a nice, small nonclustered index - except there is already a table scan query plan stored in the cache, so SQL Server helpfully does what it's supposed to do any uses that plan, performing a million table scans for our million queries!
 |
| http://cdn-webimages.wimages.net/05123d70d127ca613706fc58c0084f07caa772-wm.jpg?v=3 |
The way to deal with a bad query plan is to get rid of it (Simple, right?) Many people think you need to dump the full procedure and/or system caches (or even worse, restart SQL Server) to clear this situation (and *DON'T* do that in production!)
What you can do instead is zap a single offending query plan, impacting only that specific query!
As Glenn describes here, you can look up the individual plan handle and then pass it to DBCC FREEPROCCACHE to remove that single plan from the cache.
To look up the plan handle, you can use this query:
SELECT cp.plan_handle, cp.objtype, cp.usecounts,
DB_NAME(st.dbid) AS [DatabaseName]
FROM sys.dm_exec_cached_plans AS cp CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS st
WHERE OBJECT_NAME (st.objectid)
LIKE N'%sp_MSadd_replcmds%' OPTION (RECOMPILE);
| plan_handle | objtype | usecounts | DatabaseName |
| 0x0500FF7FB38EE9D6A03A9D310501000001000000000000000000000000000000000000000000000000000000 | Proc | 1077642 | NULL |
The next step is to pass this plan_handle to DBCC FREEPROCCACHE:
--
DBCC FREEPROCCACHE(0x0500FF7FB38EE9D6A03A9D310501000001000000000000000000000000000000000000000000000000000000)
| -- |
 |
| https://revdrbrian.files.wordpress.com/2016/03/and-there-was-much-rejoicing.jpg |
Another useful query came from a blog post Chris Skorlinski of Microsoft https://blogs.msdn.microsoft.com/chrissk/2009/05/25/transactional-replication-conversations/
The post is relatively old (2009) but it still is relevant as it talks about troubleshooting replication (which what led me to it, even though my problem ended up not being a replication problem) but the query is useful to find both the plan handles and other relevant information about the top CPU-consuming queries. It is a useful expansion on the Glenn query above:
--
SELECT TOP 25
st.text,
qp.query_plan,
(qs.total_logical_reads/qs.execution_count) as avg_logical_reads,
(qs.total_logical_writes/qs.execution_count) as avg_logical_writes,
(qs.total_physical_reads/qs.execution_count) as avg_phys_reads,
qs.*
FROM sys.dm_exec_query_stats as qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) as st
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) as qp
--WHERE st.text like 'CREATE PROCEDURE sp_MSadd_replcmds%'
ORDER BY qs.total_worker_time DESC
