

In part 1 of this series available here I introduced my drawing of what I think SSDT is and talked about the first major category the development ide and how it can help us. Just to recap for each subject on the image I give a bit of blurb and then some links to further reading.
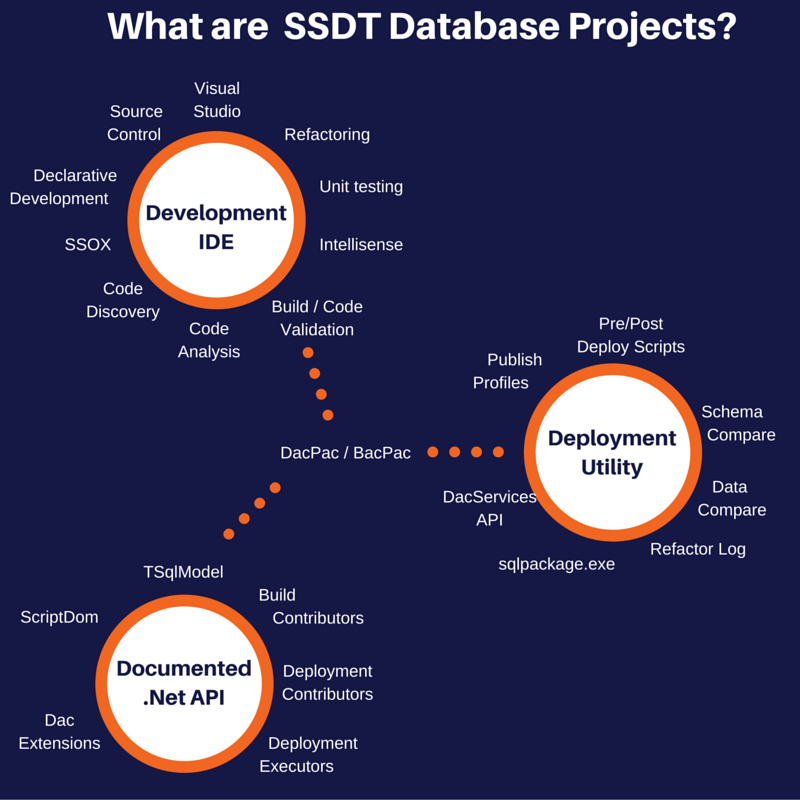
In this part (part 2 would you believe) I will give an overview of the second major category which is that it is a deployment utility. What I mean by deployment utility is that we can take our code and deploy it to a SQL Server (hopefully that is fairly obvious).
DacPac / BacPac
We start again with these as they are critical to the whole process, the development IDE creates a dacpac from an SSDT project (or a dacpac / bacpac are exported from live databases) and then we have a set of tools to take these models of what we want a database to look like and make a database look like that. If you have ever used the redgate sql compare tool then you will understand what I am talking about, it is pretty straight forward right?
Deployment Utility
DacServices API
I will talk about this first as everything else uses this in one form or another. The DacServices API is responsible for comparing a model (inside a dacpac / bacpac) and comparing it to a live database. It is also responsible for the reverse - for extracting code, schema and in the case of a bacpac for exporting the data.
The compare / merge that happens is quite a scary thing when you think about it, there are a lot of different types of objects that SQL Server understands all with a very inconsistent syntax (I can think of at least 4 ways to create each type of constraint so multiple that by the types of constraints and the rest of the objects and it is a big number for a tool to understand).
I have been using SSDT to deploy database changes for around 2 years and at first I was really wary about losing something or a release going wrong but as long as you have a set of tests, verify your deployment scripts in a pre-production environment and run your tests then I am now confident to use the deployment to deploy to any environment including production. I understand that this is a big step for a lot of people but you can start auto-deploying to dev and test environments and start building up your confidence to full continuous deployments.
DacServices Class
https://msdn.microsoft.com/en-us/library/microsoft.sqlserver.dac.dacserv...
Looking at SSDT upgrade scripts
https://the.agilesql.club/blogs/Ed-Elliott/2015-11-01/Looking-at-SSDT-up...
sqlpackage.exe
sqlpackage is the main tool I use to deploy dacpacs it is a command line tool that takes a dacpac (or bacpac, from now on I will just say dacpac and it always applies to bacpacs but if anything doesn't then I will call it out) and compares it to a database and does some stuff. The things it can do are:
- Extract - Take a live database and create a dacpac (not a bacpac)
- DeployReport - Generate an xml report of things it would change if it was allowed to
- DriftReport - If you register a database with a dacpac then this displays a report about what has changed since it was registered (see below for what registering means)<.li>
- Publish - Deploy any changes that the DacServices find to a live database (show me the money!)
- Script - Generate a script that can be run later or just stored so it can be examined later if required (auditing etc)
- Export - Take a live database and create a bacpac (not a dacpac)
- Import - Takes a bacpac (not a dacpac) and creates a new database from it - this is how you deploy an existing database to SQL Azure (or whatever it is called this month)
- Pipe - I have never really figured this one out, it is undocumented and when you try it tries to
connect to a WCF service on the local machine and always fails for me
Things to know about sqlpackage are:
-There are at least 3 ways to tell it what server and database to connect to:
- Via a publish profile (more on that later)
- Via the /TargetConnectionString
- Via /TargetServerName and /TargetDatabaseName
-The arguments are in the form "/" Arg ":" note the colon rather than an ='s
-sqlpackage.exe is always deployed to %ProgramFiles(x86)%\Microsoft SQL Server\%VERSION%\DAC\bin but it is just a .net app so you can copy the folder wherever you want. The only thing you will need to do if you run it on a machine that doesn't have the SQL Client tools installed or SSDT is also copy %ProgramFiles(x86)%\Microsoft SQL Server\%VERSION%\SDK\Assemblies\Microsoft.SqlServer.TransactSql.ScriptDom.dll
-If you wrap calls in sqlpackage.exe in a powershell script you need to redirect stdout and stderr to get all error messages.
What does registering a database mean?
What happens is that the dacpac is stored inside the database itself so later on if you want to know if anything has changed the DacServices will compare the stored dacpac to the database to verify that the schema and code hasn't changed.
I don't use the Visual Studio SSDT Publish
(Basically why I like to fawn over sqlpackage.exe)
https://the.agilesql.club/blog/Ed-Elliott/Visual-Studio-SSDT-Publish-My-...
SqlPackage.exe
(The command line args documentation, get used to this page it is your friend)
https://msdn.microsoft.com/en-us/hh550080.aspx
Publish Profiles
When you deploy a dacpac there are like a hundred options you can set (https://msdn.microsoft.com/en-us/library/microsoft.sqlserver.dac.dacdepl...), you can use sqlpackage and pass each option as a /p:Option=Value but that gets quite tiring typing it over and over and also you tend to forget things in different environments so what you can do is to use a publish profile which is an xml file with the details of where you want to publish to and also any options you might want to use in your environment.
To create a publish profile, if in SSDT you go to publish the database it pops up with a dialog and at the bottom of the dialog it has a button "Save Profile As" this will save your profile and you can just edit this as it is an xml file or you can use the publish database ui that saved it to modify it. Note if you double click a publish profile in SSDT to edit it you must choose save as changes are lost without prompting you to save them. That is only annoying about the first hundred times you forget that 🙂
Publish profiles are basically the easy way to manage different configurations between different environments, use them and live the dream.
Publish Profile Files in SQL Server Data Tools (SSDT)
http://sqlblog.com/blogs/jamie_thomson/archive/2012/05/09/publish-profil...
Deploy a SQL Server Database project’s *.dacpac with SqlPackage.exe
http://www.benday.com/2012/12/18/deploy-a-sql-server-database-projects-d...
Pre/Post Deploy Scripts
When you do an actual deployment or generate a script to be deployed later the process goes:
- 1. Compare dacpac to database
- 2. Create deployment steps (i.e. alter this, create that)
- 3. Add the Pre-Deploy script to the beginning of the deployment steps
- 4. Add the Post-Deploy script to the end of the deployment steps
This means you can run your own t-sql before and after the deployment. This sounds cool right? It gets better, if a table is modified then the constraints on that table are disabled, then the pre-deploy script is run, then the steps and then your post-deploy script and finally the constraints are re-enabled so if you wanted to setup your data of a new column or do something fancy then it is super simple.
You can have one pre-deploy and one post-deploy script per dacpac and if you use references to link together multiple dacpacs when you deploy only the scripts in the main dacpac are run, the other ones are silently ignored.
To add a pre/post deploy script in SSDT you simply add a new Script of type Pre / Post deploy and what happens is that the build action of the script (click on the file in solution explorer and see the properties window) is set to pre/post deploy - any existing scripts that already have the build action will have it removed.
Pre-Compare & Pre-Deployment Scripts to SSDT
https://the.agilesql.club/Blog/Ed-Elliott/Pre-Compare-and-Pre-Deploy-Scr...
Why does sqlpackage.exe not compare after the pre deployment script has run?
https://the.agilesql.club/Blog/Ed-Elliott/Pre-Deploy-Scripts-In-SSDT-Whe...
Peter Schott: SSDT: Pre and Post Deploy Scripts
http://schottsql.blogspot.co.uk/2012/11/ssdt-pre-and-post-deploy-scripts...
Go read anything from Peter Schott, really useful and insightful stuff, it really helped me get to grips with SSDT!
Refactor Log
When you use SSDT to refactor something so maybe you change its name or move it to a different schema to avoid the DacServices dropping the old object and creating a new empty object (horror of horrors!) SSDT adds an entry to the refactorlog. The refactorlog is an xml file that has a list of changes in it, fairly straight forward.
Each entry in the refactor log has a unique guid and when the refactor operation has happened on a database the guid is stored in a table called _refactorlog - what this means is that no matter how many times a dacpac is deployed a specific refactor is only executed once. This stops situations where you have an object, rename it to something else and then create a new object with the old name accidentally being renamed again.
If your refactorlog starts to get quite big and you know all the entries have been applied to all your servers you can also manually edit it and remove any entries you no longer require.
Refactoring with SSDT
http://dotnetspeak.com/2012/03/refactoring-with-ssdt
Schema Compare
I left the schema and data compare until last as although they are really useful I really try not to use them.
The schema compare is basically like the redgate sql compare tool it lets you compare a database and an ssdt project (actually any of a database, ssdt project or dacpac can be compared to each other) and then lets you update the target to match the source. You don't have to set the target to a database you can compare from a database back to an ssdt project and update it.
The reason I try to avoid it is that generally I find people use it to compare back to a project because they have been doing their development in SSMS and need to merge the changes back in - take the plunge and fix any headaches and just do the work in SSDT.
The second reason I try to avoid it is that I find people use it to compare to live environments instead of building an automated deployments and tests etc to prove that everything is good. The correct approach is to move towards continuous integration and delivery and then after that continuous deployment when your dba is bored of running scripts that never fail 🙂
If you do use it then sometimes it tries to deploy objects that haven't changed to see why, click on the object and in the status bar at the bottom it shows the reason why.
How to: Use Schema Compare to Compare Different Database Definitions
https://msdn.microsoft.com/en-us/library/hh272690.aspx
Schema Compare or Publish [SSDT]
http://sqlblog.com/blogs/jamie_thomson/archive/2013/12/19/schema-compare...
Data Compare
Data Compare is similar to the schema compare except it compares data in tables - I rarely use it but it is useful when you need to do that sort of thing. You can only compare live databases and it generates insert statements for you.
Compare and Synchronize Data in One or More Tables with Data in a Reference Database
https://msdn.microsoft.com/en-us/library/dn266029.aspx
Summary
Using the DacServices via whatever method you want (schema compare, sqlpackage, powershell, something else?) really makes it simple to spend your time writing code and tests rather than manual migration steps. It constantly amazes me who well rounded the deployment side of things is. Every time I use something obscure, something other than a table or procedure I half expect the deployment to fail but it just always works.
Over the last couple of years I must have created hundreds if not thousands of builds all with their own release scripts across tens of databases in different environments and I haven't yet been able to break the ssdt deployment bits without it acyually being my fault or something stupid like a merge that goes haywire (that's one reason to have tests).
If you liked the idea of SSDT but for some reason didn't like the deployment stuff you could always use the redgate sql compare tool to compare the ssdt source folder to a database which would at least get you started in the right direction.
In the last part (part 3) I will discuss what is arguably a game changer for RBDMS's a complete API to manage your code 🙂
![]()
