

Per Books Online, DBCC SHOW_STATISTICS displays current query optimization statistics for a table or indexed view. Basically it shows you the statistics, or a summary of the data, that SQL Server will use to help generate an execution plan.
In the example below, we'll be looking at the statistics for the index IX_Person_LastName_FirstName_MiddleName, which is a non-clustered index on the Person.Person table in the AdventureWorks2012 database. We'll cover several queries you can run against your data to help you visualize what the statistics are telling you about your data.
Before we dive into the example, we need to update the statistics with a full scan on this index. This will make sure the details in the example match our queries exactly.
UPDATE STATISTICS Person.Person IX_Person_LastName_FirstName_MiddleName WITH FULLSCAN;
DBCC SHOW_STATISTICS returns three sections of information: the header, the density vector, and the histogram. The first section is the statistics header.
DBCC SHOW_STATISTICS('Person.Person','IX_Person_LastName_FirstName_MiddleName') WITH STAT_HEADER;
The statistics header returns meta data about the statistic. For example, the date it was created or last updated, number of rows in the table or indexed view, the number rows used to calculate the statistic, etc.
The second section is the density vector.
DBCC SHOW_STATISTICS('Person.Person','IX_Person_LastName_FirstName_MiddleName') WITH DENSITY_VECTOR;

The density vector is representation of how many unique values are present within a column or columns of the statistic. Simply put it's 1/# of distinct values. Our example has 4 levels for the density vector; one for each of the three key columns, plus one that includes the clustered index. To see how SQL Server calculates the values for each of these four levels, we can use the following queries.
--Level 1
SELECT CONVERT(DECIMAL(15,12),1.0/COUNT(DISTINCT LastName)) AS 'Level1'
FROM Person.Person;
GO
--Level 2
SELECT CONVERT(DECIMAL(15,12),1.0/COUNT(*)) AS 'Level2'
FROM (SELECT DISTINCT
LastName
,FirstName
FROM Person.Person) AS DistinctRows;
GO
--Level 3
SELECT CONVERT(DECIMAL(15,12),1.0/COUNT(*)) AS 'Level3'
FROM (SELECT DISTINCT
LastName
,FirstName
,MiddleName
FROM Person.Person) AS DistinctRows;
GO
--Level 4
SELECT CONVERT(DECIMAL(15,12),1.0/COUNT(*)) AS 'Level4'
FROM (SELECT DISTINCT
LastName
,FirstName
,MiddleName
,BusinessEntityID
FROM Person.Person) AS DistinctRows;
GO

Our values are formatted to display the entire number, but DBCC SHOW_STATISTICS will use the E notation to shorten number to 5.124001E-05. This notation just means take 5.124001 * 10-5, or an easier explanation would be to move the decimal place 5 spaces to the left. As you can see, our numbers nearly match what is returned by DBCC SHOW_STATISTICS.
The third section of information is the histogram.
DBCC SHOW_STATISTICS('Person.Person','IX_Person_LastName_FirstName_MiddleName') WITH HISTOGRAM;
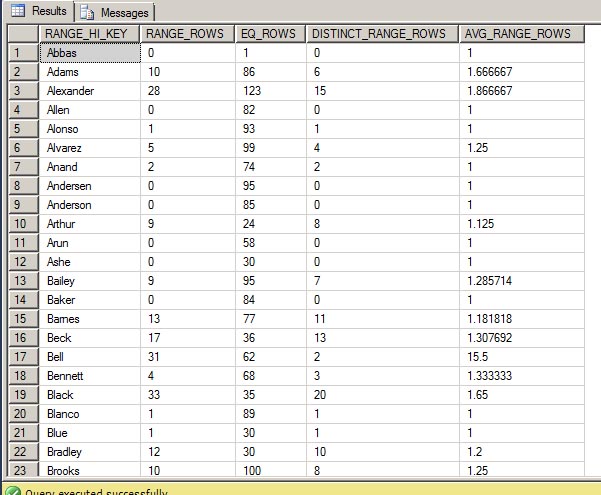
The histogram returns information about the frequency of data within the first key column of the statistic. In our example, we have a composite index of LastName, FirstName, and MiddleName, so the histogram only contains information about the first column, LastName.
- RANGE_HI_KEY - is the upper bound value of the key.
- RANGE_ROWS - is the number of rows who's value falls within the step, but does not equal the upper bound (RANGE_HI_KEY).
- EQ_ROWS - is the number of rows equal to the upper bound.
- DISTINCT_RANGE_ROWS - is the number of distinct values within the histogram step, but does not equal the upper bound (RANGE_HI_KEY).
- AVG_RANGE_ROWS - is the average number of duplicate values within the step, but does not equal the upper bound (RANGE_HI_KEY); calculated as RANGE_ROWS/DISTINCT_RANGE_ROWS.
If we examine the RANGE_HI_KEY value of Adams, we can figure out the exact data rows that fall into this histogram step by looking at these queries.
For the RANGE_ROWS, we need to find all the rows that are greater than the previous RANGE_HI_KEY value, but less than the RANGE_HI_KEY of 'Adams'. This will return the 10 rows that were in the histogram RANGE_ROWS column.
--RANGE_ROWS
SELECT * FROM Person.Person
WHERE LastName > 'Abbas'
AND LastName < 'Adams';
GO

For the EQ_ROWS, we just need to find all the rows that are equal to the RANGE_HI_KEY 'Adams'. This will return the 86 rows that were in the histogram EQ_ROWS column.
--EQ_ROWS
SELECT * FROM Person.Person
WHERE LastName = 'Adams';
GO

For the DISTINCT_RANGE_ROWS, we need to find all the distinct values that are greater than the previous RANGE_HI_KEY but less than the RANGE_HI_KEY of 'Adams'. This will return the 6 rows that were in the DISTINCT_RANGE_ROWS column.
--DISTINCT_RANGE_ROWS
SELECT DISTINCT LastName FROM Person.Person
WHERE LastName > 'Abbas'
AND LastName < 'Adams';
GO

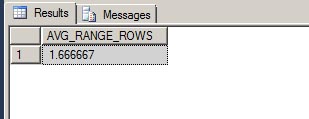
For the AVG_RANGE_ROWS, we need to find the values that are greater than the previous RANGE_HI_KEY but less than the RANGE_HI_KEY of 'Adams', and then divide that by the number of distinct values within the same range. This will return the average value of 1.666667 that was in the AVG_RANGE_ROWS column.
--AVG_RANGE_ROWS
DECLARE
@x DECIMAL(20,6)
,@y DECIMAL(20,6);
SELECT @x = COUNT(LastName) FROM Person.Person
WHERE LastName > 'Abbas'
AND LastName < 'Adams';
SELECT @y = COUNT(DISTINCT LastName) FROM Person.Person
WHERE LastName > 'Abbas'
AND LastName < 'Adams';
IF @y > 0
SELECT CONVERT(DECIMAL(20,6),@x/@y) AS 'AVG_RANGE_ROWS';
GO
As you can see, it's not that hard to see how the statistical information is derived within DBCC SHOW_STATISTICS.
If you would like more detailed information on how statistics are generated and how they help the query optimizer, check out Grant Fritchey's books and blog. He covers a lot of good in-depth information about statistics. And of course Books Online has plenty more information about DBCC SHOW_STATISTICS.
