

I remember being thoroughly baffled in grade school by word problems. How in the world was I supposed to translate “Sally is on a north-bound train moving at 60 miles an hour. John is on a train on the next track over moving at 40 miles an hour. If John left an hour before Sally, how long will it take Sally to catch up, and how far will she travel?” into some kind of mathematical formula? I might as well have been pondering how many angels could dance on the head of a pin, or some other divine mystery.
I eventually became proficient enough to overcome most of my trepidation, but it’s a subject that’s continued to fascinate me, especially after I became involved in IT and application development and began facing the problems of translating business requirements and expectations into code. As I made the transition from application development to database development, the same problems followed, exasperated to a certain degree by the flexibility – and ambiguity – of SQL. For any given data question, there are often multiple potential solutions. Translating English into SQL can be a challenge – even for relatively simple queries.
Consider the very common request, “Bring back everything from A that doesn’t have a B.” We’ll make an imaginary request along these lines from an equally imaginary AdventureWorks executive (using the AdventureWorks2012 database): “Find all the customers who didn’t make a purchase in 2006.” Seemingly straightforward, and a good majority of developers, I think, would come up with this:
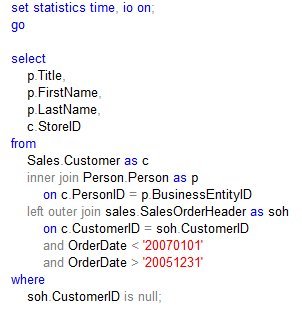
But is what this query says a true translation of the English language request? The execution plan can provide some clues:
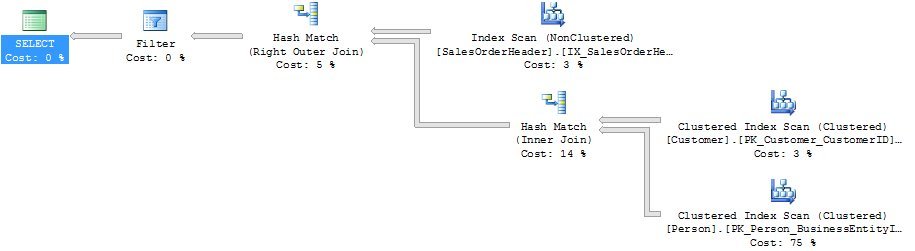
Let’s see if we can translate this back into English: “Take all the Person records” (the clustered index scan of Person) “and match them to all the Customer records” (clustered index scan of Customer) “then match them up with all the sales from years other than 2006” (nonclustered index scan on SalesOrderHeader) “and then filter out the customers that don’t have a match to the sales.”
Somewhat rephrased: “Find all the customers who had sales, then take away the ones that had sales in 2006.” Close to what we started out with: “Find all the customers who didn’t have sales in 2006”: but more of a paraphrase than a translation.
There’s another way to write the SQL, using NOT EXISTS. Let’s see if that translates any better:
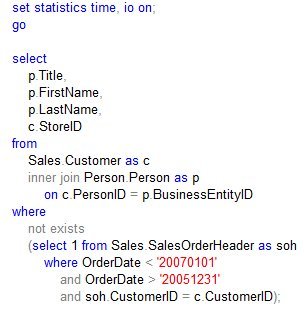
Again, we can use the execution plan to help resolve this back into English:
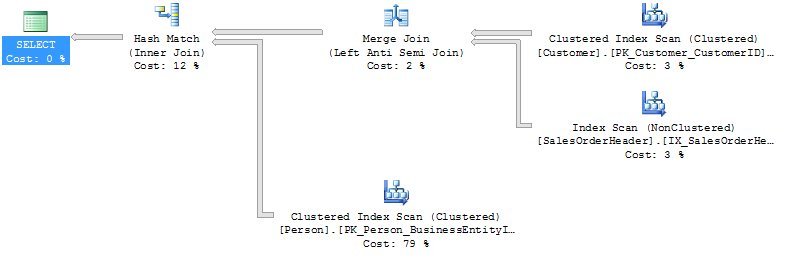
Now our sentence reads: “Take all the customer records” (clustered index scan of Customer) “and match them with the sales from years other than 2006” (nonclustered index scan of SalesOrderHeader) “but return only those Customer records that do not match” (the left anti semi merge join) “and then match them to the Person records” (clustered index scan of Person).
Rephrased: “Find all the customers who did not have sales in 2006.”
In terms of performance, both queries are fast at these low record volumes, but the NOT EXISTS holds a slight edge in CPU and overall execution time: 47ms/165ms versus 63ms/237ms: but not enough to really be noticeable. IO statistics were identical. But decreasing the time span from a year to six months shows a creeping edge to the NOT EXISTS form: 46ms/173ms versus 62ms/263ms: suggesting that it may scale better.
Both translations accomplish the goal: finding customers who had no sales in 2006: but one is clearly closer to the letter and spirit of the original requirement, and offers better performance to boot. Finding the optimal translation of English to SQL often requires patience and experimentation, particularly with complex queries. There may be a “good enough” translation that gets the job done, but perseverance and imagination can sometimes find a better!
