


Looking at the official Microsoft resource System variables supported by Azure Data Factory you're given with a modest selection of system variables that you can analyze and use both on a pipeline and pipeline trigger level. Currently, you have three ways to monitor Azure Data Factory: visually, with the help of Azure Monitor or using a code to retrieve those metrics.
But here is a case of how I want to monitor a control flow of my pipeline in Azure Data Factory:
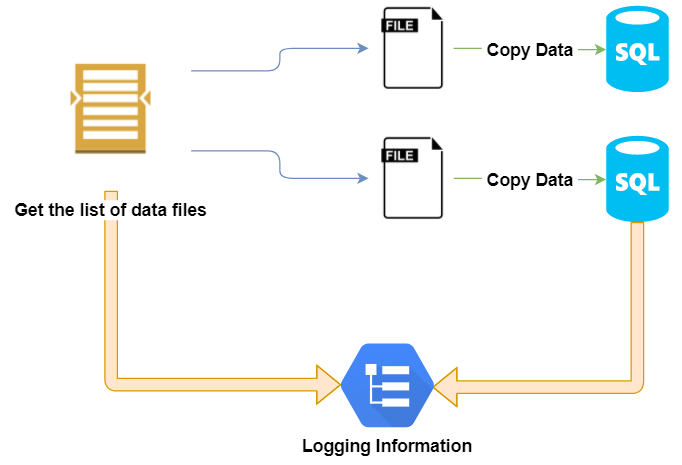
This the same data ingestion pipeline from my previous blog post - Story of combining things together that builds a list of files from a Blob storage and then data from those files are copied to a SQL database in Azure. My intention is to collect and store event information of all the completed tasks, such as Get Metadata and Copy Data.
Here is a current list of pipeline system variable in my disposal:
@pipeline().DataFactory - Name of the data factory the pipeline run is running within
@pipeline().Pipeline - Name of the pipeline
@pipeline().RunId - ID of the specific pipeline run
@pipeline().TriggerType - Type of the trigger that invoked the pipeline (Manual, Scheduler)
@pipeline().TriggerId - ID of the trigger that invokes the pipeline
@pipeline().TriggerName - Name of the trigger that invokes the pipeline
@pipeline().TriggerTime - Time when the trigger that invoked the pipeline. The trigger time is the actual fired time, not the scheduled time.
And after digging a bit more and testing pipeline activity, I've discovered additional metrics that I can retrieve on the level of each individual task:
PipelineName,
JobId,
ActivityRunId,
Status,
StatusCode,
Output,
Error,
ExecutionStartTime,
ExecutionEndTime,
ExecutionDetails,
Duration
Here is my final pipeline in ADF that can populate all these metrics into my custom logging database table:

And this is how I made it work:
1) First I created dbo.adf_pipeline_log table in my SQL database in Azure: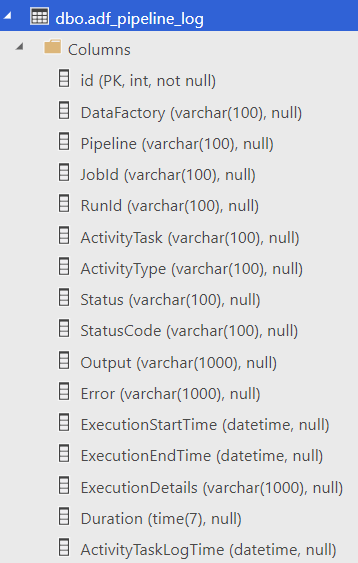
2) Then I used [Append Variable] Activity task as "On Completion" outcome from the "Get Metadata" activity with the following expression to populate a new array type var_logging variable:

var_logging =
@concat('Metadata Store 01|Copy|',
,pipeline().DataFactory,'|'
,activity('Metadata Store 01').Duration,'|'
,activity('Metadata Store 01').Error,'|'
,activity('Metadata Store 01').ExecutionDetails,'|'
,activity('Metadata Store 01').ExecutionEndTime,'|'
,activity('Metadata Store 01').ExecutionStartTime,'|'
,activity('Metadata Store 01').JobId,'|'
,activity('Metadata Store 01').Output,'|'
,pipeline().Pipeline,'|'
,activity('Metadata Store 01').ActivityRunId,'|'
,activity('Metadata Store 01').Status,'|'
,activity('Metadata Store 01').StatusCode)
where each of the system variables is concatenated and separated with pipe character "|".
I did a similar thing to populate the very same var_logging variable in the ForEach container where actual data copy operation occurs:

3) And then I used this final tasks to populate my dbo.adf_pipeline_log table using data from the var_logging variable by calling a stored procedure:

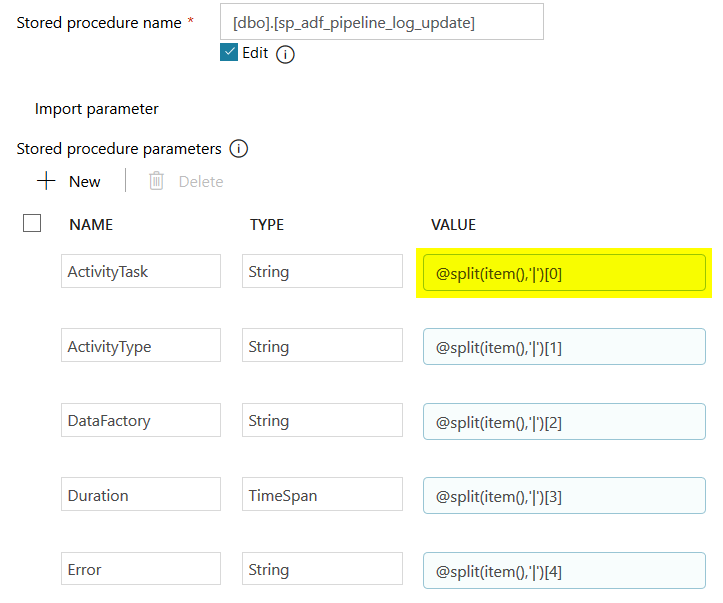
Where the whole trick is to split each of the text lines of the var_logging variable into another array of values split by "|" characters. Then by knowing the position of each individual system variables values, I can set them to their appropriate stored procedure parameters / columns in my logging table (e.g. @split(item(),'|')[0] for the ActivityTask).
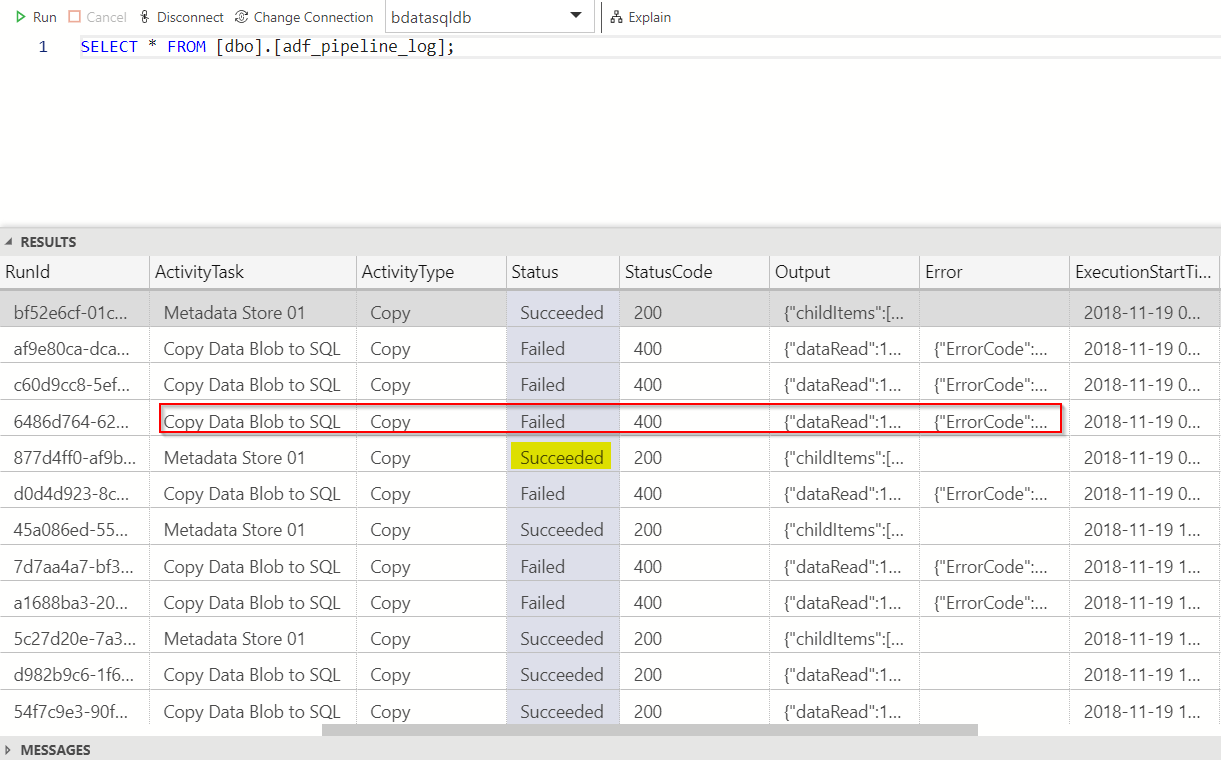
This provided me a flexibility to see both Completed and Failed activity runs (to test a failed activity I had to temporarily rename the target table of my Copy Data task). I can now read this data and get more additional insights from the SQL Server table.
Let me know what you think about this, and have a happy data adventure!
