

Very early in my career I got fascinated by the MS Access TRANSFORM statement, then in 2005 version of the SQL Server the PIVOT/UNPIVOT operators came out and that made me even more excited in the way that now we can forget about all custom T-SQL code and write a simple statement to turn a data set anyway we want to.
I agree with Michael, that all the available reporting tools are much better for preparing a final data set for business users. However I've used PIVOT many times and I like using it in a middle data layer when one data set gets transformed (or in Excel terms, 'transposed') to another form and then moved further along the way.
The SSIS Pivot with UI gave some additional flexibility to transform input data set, however I still prefer the T-SQL method and I can explain you why.
Here is my sourcing query that pulls data the AdventureWorksDW2014 database that I want to transform:
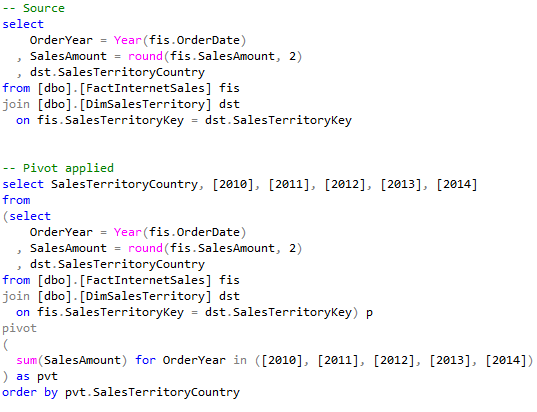
In SSIS I can do the same thing and push the sourcing query through the Pivot task:
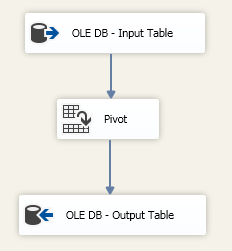

However when I execute it will fail due unique key constraint violation of my Pivot Key of the Pivot task:
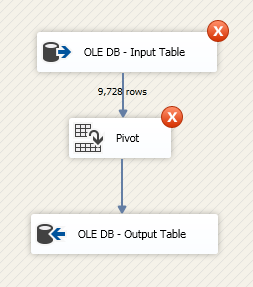
So I had to change the sourcing query and added aggregation function to it:
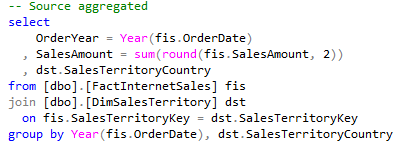
and then it worked:
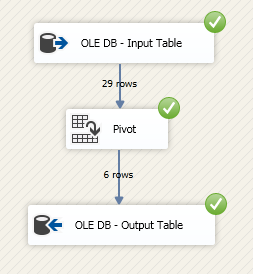
So, with a few hiccups I was able to adopt SSIS Pivot task, but I still prefer writing the Pivot T-SQL statement manually, more control, more flexibility 🙂
Lessons learned:
1) Sourcing data set for SSIS Pivot task needs to be pre-aggregated.
2) If you don't like Pivot output columns (based on Pivot Key and Pivot Value) you can always rename them in the Advanced Editor.
Working with SSIS Pivot task didn't destroy my attitude but made me stronger 🙂
Happy data adventures!
