

Side note :
I originally started this post to show with examples all the scenarios where you can get minimal logging copying data from one table to another in SQL Server. I’m running SQL Server 2017 CU7 and it quickly turned out that I couldn’t get minimal logging to happen in all the scenarios the docs say it should work. Rather than not showing these scenarios, I’m still going to list the examples for them and just note where it didn’t behave as expected.
SQL Server under certain conditions can switch to minimal logging where it then logs at a much higher level (Extent/Page) rather than row. In this post I’m specifically looking at copying data from one table to another and getting the benefit of minimal logging. For SQL Server to use minimal logging a number of things have to be true…
- Recovery model must be Simple or Bulk Logged
- Table must be either
- A heap and insert done with TABLOCK
- A heap + nonclustered index with TABLOCK and either trace flag 610 or SQL Server 2016+
- A clustered index with no data and TABLOCK
- A clustered index with no data and either trace flag 610 or SQL Server 2016+
- A clustered index with data and trace flag 610 or SQL Server 2016+
- A clustered index with nonclustered indexes and TABLOCK and trace flag 610 or SQL Server 2016+
A LOT more information on the above can be found in the following articles from Microsoft
- The Data Loading Performance Guide
- SQL Server 2016, Minimal logging and Impact of the Batchsize in bulk load operations
Even with everything above being true the optimizer can still choose plans that don’t minimally log. For example, if you insert into an empty clustered index and the source data isn’t in the same order as the clustered index then SQL Server will not minimally log. If you need an insert to use minimal logging it’s always best to test it first and not just assume you’re going to get it.
Below I’m going to cover a number of examples of the above conditions and show ways to check if you are getting minimal logging. I’m running all the examples in this post on SQL Server 2017 CU7 so trace flat 610 is not needed for me but if you’re on a version before 2016 you’ll need to enable this traceflag to get the same results.
For the examples in this post I’m going to be using the Stack Overflow database because it’s a nice size and has a schema that is easily understandable. You can download various sized versions from BrentOzar.com
I’ve written the following stored procedure to return log information for a given query. If you’re following along create this in the Stack Overflow database…
/*
Example Usage...
EXEC GetLogUseStats
@Sql = '
INSERT INTO PostsDestination
SELECT * FROM Posts ORDER BY Id ',
@Schema = 'dbo',
@Table = 'PostsDestination',
@ClearData = 1
*/
ALTER PROCEDURE [dbo].[GetLogUseStats]
(
@Sql NVARCHAR(400),
@Schema NVARCHAR(20),
@Table NVARCHAR(200),
@ClearData BIT = 0
)
AS
IF @ClearData = 1
EXEC('TRUNCATE TABLE ' + @Table)
CHECKPOINT
/*Snapshot of logsize before query*/
CREATE TABLE #BeforeLogUsed(
[Db] NVARCHAR(100),
LogSize NVARCHAR(30),
Used NVARCHAR(50),
Status INT
)
INSERT INTO #BeforeLogUsed
EXEC('DBCC SQLPERF(logspace)')
/*Run Query*/
EXECUTE sp_executesql @SQL
/*Snapshot of logsize after query*/
CREATE TABLE #AfterLLogUsed(
[Db] NVARCHAR(100),
LogSize NVARCHAR(30),
Used NVARCHAR(50),
Status INT
)
INSERT INTO #AfterLLogUsed
EXEC('DBCC SQLPERF(logspace)')
/*Return before and after log size*/
SELECT
CAST(#AfterLLogUsed.Used AS DECIMAL(12,4)) - CAST(#BeforeLogUsed.Used AS DECIMAL(12,4)) AS LogSpaceUsersByInsert
FROM
#BeforeLogUsed
LEFT JOIN #AfterLLogUsed ON #AfterLLogUsed.Db = #BeforeLogUsed.Db
WHERE
#BeforeLogUsed.Db = DB_NAME()
/*Get list of affected indexes from insert query*/
SELECT
@Schema + '.' + so.name + '.' + si.name AS IndexName
INTO
#IndexNames
FROM
sys.indexes si
JOIN sys.objects so ON si.[object_id] = so.[object_id]
WHERE
si.name IS NOT NULL
AND so.name = @Table
INSERT INTO #IndexNames VALUES(@Schema + '.' + @Table)
/*Get log recrod sizes for heap and/or any indexes*/
SELECT
AllocUnitName,
[operation],
AVG([log record length]) AvgLogLength,
SUM([log record length]) TotalLogLength,
COUNT(*) Count
INTO #LogBreakdown
FROM
fn_dblog(null, null) fn
INNER JOIN #IndexNames ON #IndexNames.IndexName = allocunitname
GROUP BY
[Operation], AllocUnitName
ORDER BY AllocUnitName, operation
SELECT * FROM #LogBreakdown
SELECT AllocUnitName, SUM(TotalLogLength) TotalLogRecordLength
FROM #LogBreakdown
GROUP BY AllocUnitNameGetLogUseStats will allow us to pass in an insert query and a table name then return all the log information that happened on the table and its associated indexes. For this post I’ll mainly be passing 1 in for the ClearData parameter to force each query to run on an empty table. This is designed to be run on a Development server, for accuracy try to run it on a database that nothing else is running on or log records written by other queries will throw out the results.
To keep the examples simple, we’re just going to look at ways to insert all the records in the posts table into a second table. If you’re following along once you’ve restored Stack Overflow database set it to simple recovery model (Bulk would also work). I’ve trimmed the Posts table down to 500k records to keep things running fast on my laptop but you can adjust this to suit your machine.
ALTER DATABASE StackOverflow SET RECOVERY SIMPLEcreate an empty table that we’re going to copy the posts into…
CREATE TABLE [dbo].[PostsDestination](
[Id] [int] NOT NULL,
[AcceptedAnswerId] [int] NULL,
[AnswerCount] [int] NULL,
[Body] [nvarchar](max) NOT NULL,
[ClosedDate] [datetime] NULL,
[CommentCount] [int] NULL,
[CommunityOwnedDate] [datetime] NULL,
[CreationDate] [datetime] NOT NULL,
[FavoriteCount] [int] NULL,
[LastActivityDate] [datetime] NOT NULL,
[LastEditDate] [datetime] NULL,
[LastEditorDisplayName] [nvarchar](40) NULL,
[LastEditorUserId] [int] NULL,
[OwnerUserId] [int] NULL,
[ParentId] [int] NULL,
[PostTypeId] [int] NOT NULL,
[Score] [int] NOT NULL,
[Tags] [nvarchar](150) NULL,
[Title] [nvarchar](250) NULL,
[ViewCount] [int] NOT NULL,
)So at this point we have a heap with no nonclustered indexes.
I’m going to run through each of the points above that support minimal logging but before we do lets first do an insert into the heap with no TABLOCK which as we can see from the bullet points above will not minimally log…
EXEC sp_GetLogUseStats
@Sql = '
INSERT INTO PostsDestination
SELECT * FROM Posts ORDER BY Id ',
@Schema = 'dbo',
@Table = 'PostsDestination',
@ClearData = 1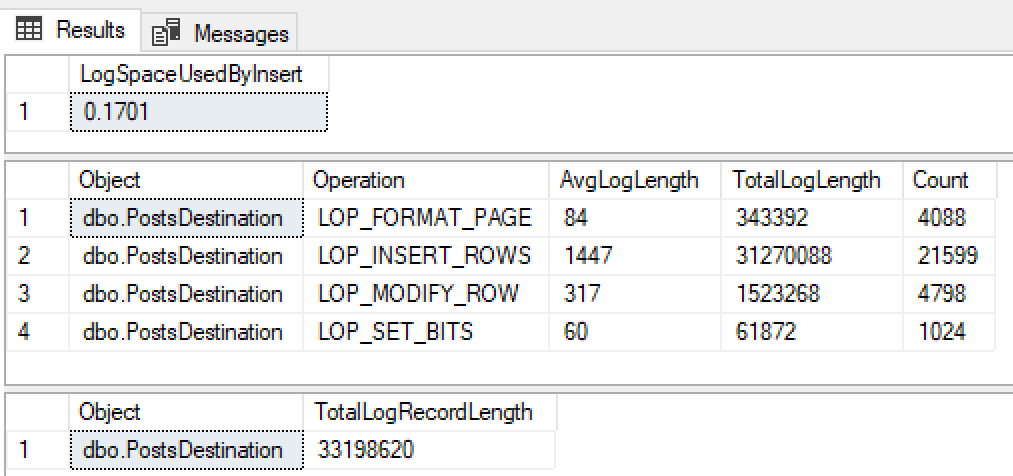
We’ve caused the log file to grow 0.1701mb and we can see we have a large number of individual LOP_INSERT_ROWS records in our log file. As suspected this query was not minimally logged. Follow through the next example to see what a minimally logged query looks like.
Heap With No Indexes and TABLOCK
Let’s try this again but this time using TABLOCK to take a table lock on our PostsDestination table which as we know should get us a minimally logged insert..
EXEC sp_GetLogUseStats
@Sql = '
INSERT INTO PostsDestination WITH(TABLOCK)
SELECT * FROM Posts ORDER BY Id ',
@Schema = 'dbo',
@Table = 'PostsDestination',
@ClearData = 1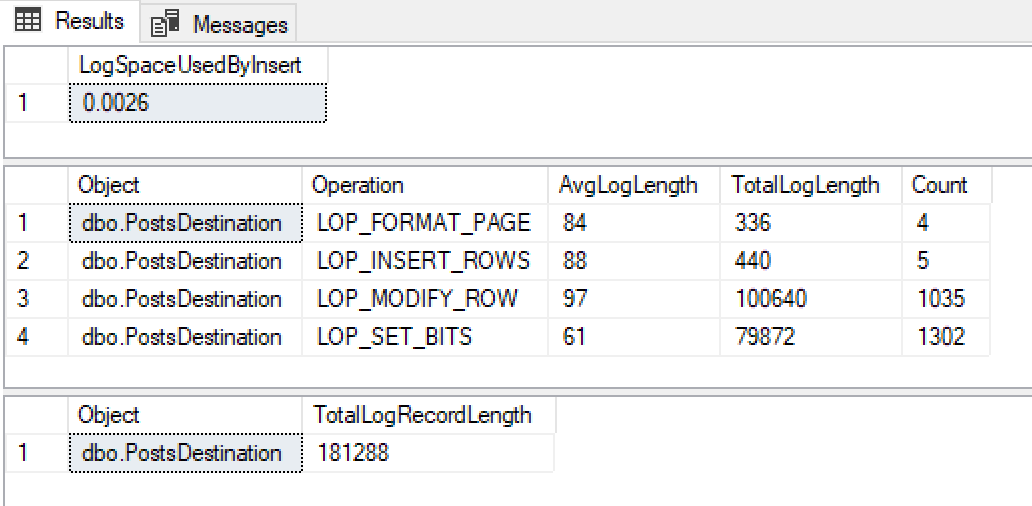
Our log record growth has gone from 0.1701mb to 0.0026mb, down by about a factor of 60 (These are low numbers even on the non minimally logged example as I shrunk my dataset). Also notice we have hardly any LOG_INSERT_ROWS records as we’re now working at the page level rather than the row.
Heap With NonClustered Index and TABLOCK (Trace Flag 610 or 2016+)
This is where things get interesting according to the docs you get minimal logging on a nonclustered index when using TABLOCK if you either enable trace flag 610 or are on SQL Server 2016. As mentioned I’m running SQL Server 2017 CU7, let’s see what happens….
First create a nonclustered index on our table…
CREATE NONCLUSTERED INDEX ndx_PostsDestination_Id ON PostsDestination(Id)
ALTER INDEX ndx_PostsDestination_Id ON PostsDestination SET (ALLOW_PAGE_LOCKS = ON);I’m explicitly setting ALLOW_PAGE_LOCKS to on here even though it’s the default just to prove the index will allow page locking as without it the insert can’t be minimally logged.
Then let’s run our insert again with TABLOCK…
EXEC sp_GetLogUseStats
@Sql = '
INSERT INTO PostsDestination WITH(TABLOCK)
SELECT * FROM Posts ORDER BY Id ',
@Schema = 'dbo',
@Table = 'PostsDestination',
@ClearData = 1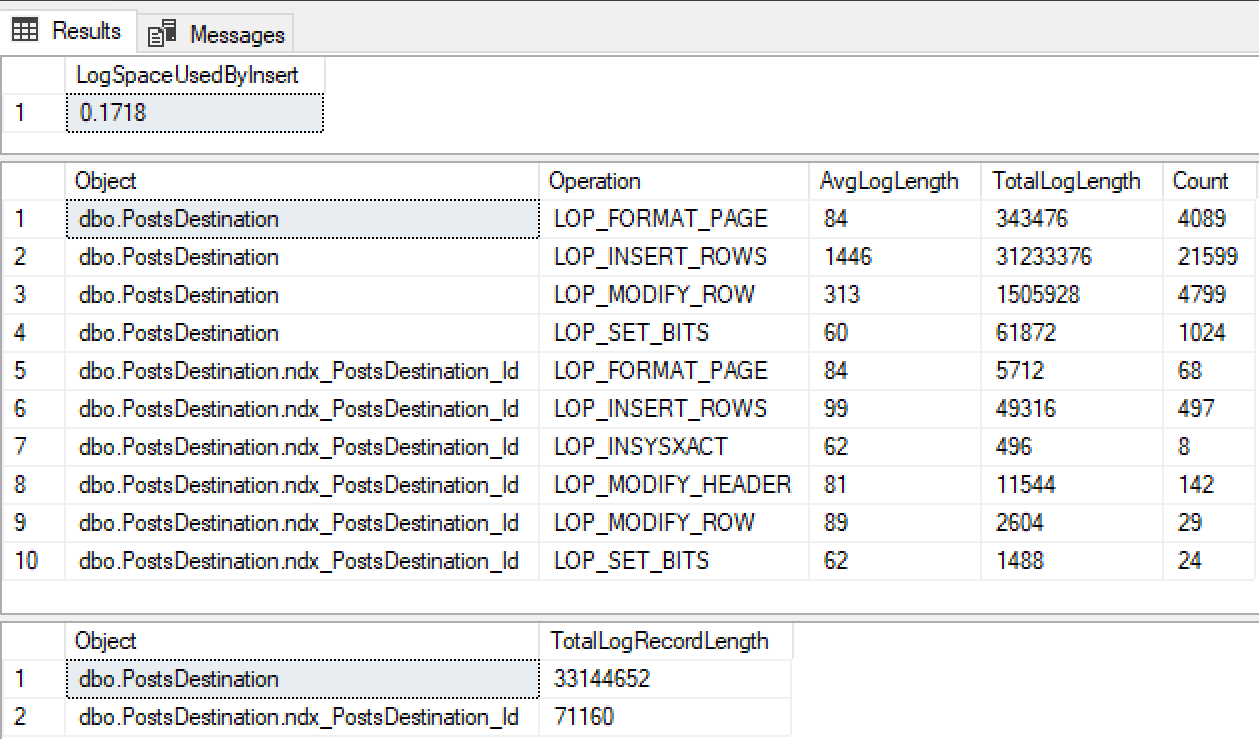
Looking at this we can see the log file grew by 0.1718mb and log records for both the heap and the index have a high number of LOG_INSERT_ROW records. Not only did we not minimally log the insert into the index we also lost minimal logging to the heap. This is completely unexpected from reading the documentation. I’m not sure if I’ve missed something here but as far as I can see the query above meets all the criteria for a minimally logged insert.
Empty Clustered Index With TABLOCK
If you still have it drop the nonclustered index from the above example and create a clustered index…
DROP INDEX ndx_PostsDestination_Id ON PostsDestination
CREATE CLUSTERED INDEX ndx_PostsDestination_Id ON PostsDestination(Id)Then lets run our TABLOCK insert again…
EXEC GetLogUseStats
@Sql = '
INSERT INTO PostsDestination WITH(TABLOCK)
SELECT * FROM Posts ORDER BY Id ',
@Schema = 'dbo',
@Table = 'PostsDestination',
@ClearData = 1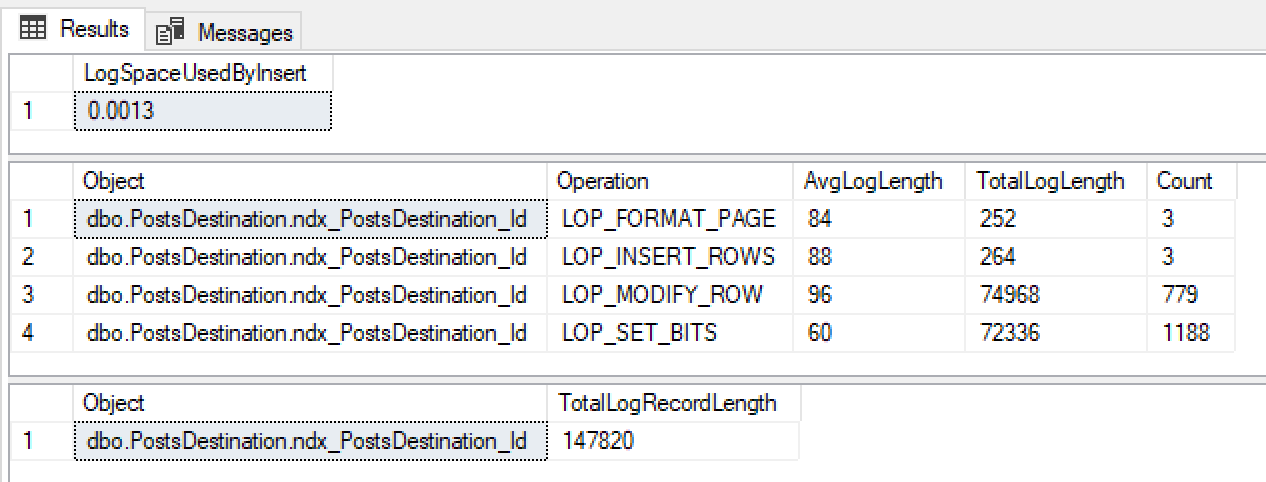
Woop back in to chartered territory, minimal logging is back! The log grew by 0.0013mb (Our smallest yet) and only 3 LOP_INSERT_ROW records.
Empty Clustered Index With Trace 610 Or 2016+
Now let’s try again without TABLOCK, before we do that though let’s drop and recreate the index to keep things clean
DROP INDEX ndx_PostsDestination_Id ON PostsDestination
CREATE CLUSTERED INDEX ndx_PostsDestination_Id ON PostsDestination(Id)EXEC GetLogUseStats
@Sql = '
INSERT INTO PostsDestination
SELECT * FROM Posts ORDER BY Id ',
@Schema = 'dbo',
@Table = 'PostsDestination',
@ClearData = 1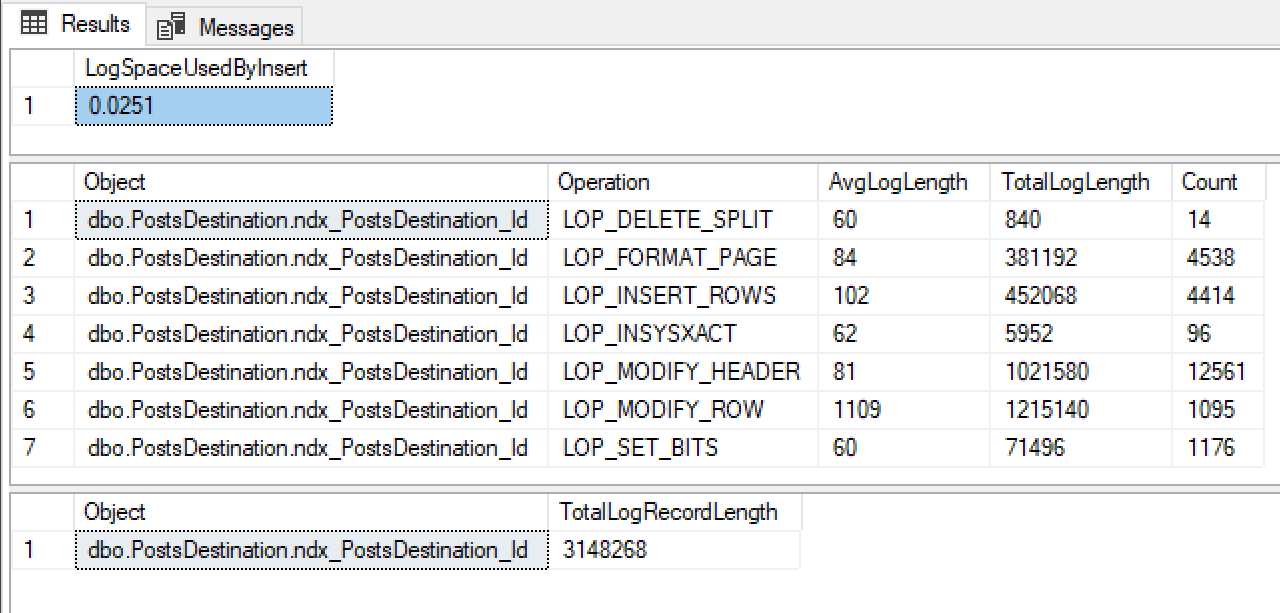
Failure number 2! 0.0251mb Log Growth and lots of log operations at LOP_INSERT_ROW level. Reason again that you should always check your assumptions with minimal logging if you’re relying on it happening.
Clustered Index With Data and Trace 610 OR 2016+
Moving along, let’s recreate the index again…
DROP INDEX ndx_PostsDestination_Id ON PostsDestination
CREATE CLUSTERED INDEX ndx_PostsDestination_Id ON PostsDestination(Id)Now let’s insert records with an Id < 100
INSERT INTO PostsDestination
SELECT * FROM Posts WHERE Id < 100 ORDER BY IdNow let’s try inserting where the Id is > 100 with TABLOCK and without clearing down the table first…
EXEC GetLogUseStats
@Sql = '
INSERT INTO PostsDestination WITH(TABLOCK)
SELECT * FROM Posts
WHERE Id > 100
ORDER BY Id ',
@Schema = 'dbo',
@Table = 'PostsDestination',
@ClearData = 0Notice the @ClearData=0.
Failure number 3, high log growth with many LOP_ROW_INSERT log records.
Clustered Index With NonClustered Indexes and TABLOCK Or Trace 610/SQL 2016+
Let’s first recreate our clustered index and add nonclustered index to the mix…
DROP INDEX ndx_PostsDestination_Id ON PostsDestination
CREATE CLUSTERED INDEX ndx_PostsDestination_Id ON PostsDestination(Id)
CREATE NONCLUSTERED INDEX ndx_PostsDestination_CommentCount ON PostsDestination(CommentCount)Now let’s try our insert again
EXEC GetLogUseStats
@Sql = '
INSERT INTO PostsDestination WITH(TABLOCK)
SELECT * FROM Posts
ORDER BY Id ',
@Schema = 'dbo',
@Table = 'PostsDestination',
@ClearData = 1Failure number 4! High log growth and inserted log records at a row level.
Summary
So all the scenarios where minimal logging should work with a nonclustered index failed along with any that said TABLOCK was not required and anywhere data already exists.
These results weren’t as I’d expected but this was still an interesting exorcise. I’m sure I’m missing something here but after rereading the documentation several times I really can’t see what. If anyone does have any ideas on the above scenarios drop me a message in the comments.
