

Working with Microsoft SQL Server for many years I have spent a lot of time discussing the importance of the availability of SQL Server databases. Questions that always come up when discussing availability of the data is “Recovery Time Objective – RTO” and “Recovery Point Objective – RPO”. Both questions are very important when determining your solution for high availability (HA) within your data center as well as your solution for disaster recovery (DR).
Microsoft SQL Server gives us several options for mitigating potential risk for our SQL Server environments. Each solution has its pros and cons and careful consideration should go into your solution. Before you can build a solution you have to have requirements on what risk you are trying to protect against. Some items you might want to protect against are OS failure, hardware failure, data corruption, or a data center failure. We have different options to help mitigate these potential failures and each solution comes with a certain cost and level of complexity. For organizations, they have to weigh the cost of the solution and complexity to manage it against the actual risk. I like to say that it comes down to a math problem that usually involves a budget. What are some technologies we typically see implemented to address HA/DR with SQL Server? Below you will see a chart I like to use that demonstrates some of the pros and cons of Log Shipping, Database Mirroring, Replication, Windows Failover Clusters, Availability Groups, and Virtualization (not a SQL technology) 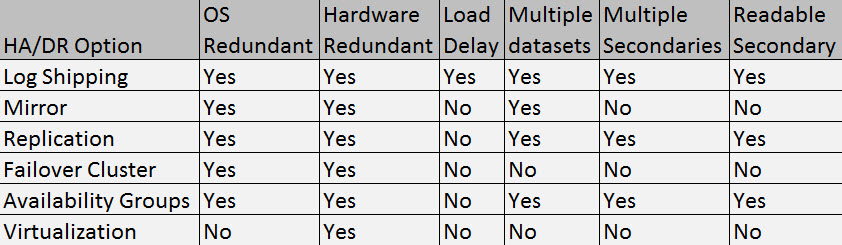
Many times when discussing HA and DR people tend to confuse or mix the two. HA is a system designed that allows for minimal downtime, typically this is for protection from an OS or hardware failure. DR is risk avoidance on a much larger scale. When discussing DR we typically cover risk management, RPO, RTO and build a disaster recovery plan. DR typically involves a second data center whereas HA is typically building redundancy within your data center.
As you can see from the list above, all but virtualization provide both hardware and OS level protection. Log Shipping is the only solution that provides a load delay in synchronizing data. This is a very important feature that can help you protect against an accidental data oops. Imagine ingesting bad that would require you to restore a database, or have an accident where an update/delete statement was ran without a where clause. If you were using replication, mirroring or any other HA solution that provides near real time replication, those transactions would also be applied against your replica. If you had a load delay of 12 to 24 hours you could roll the logs to just before the accident and be back online much quicker than restoring the database.
As previously stated, in order to know which solution is best for you, you really have to know what your requirements are. For me, I typically use a combination of most of the solutions depending on my environment. I have a combination of log shipping, failover clustering, availability groups and virtualization in place. For very large critical environments, a log shipped secondary provides a nice level of comfort knowing I can bring a multi terabyte database back online in minutes in the event I have a data issue.
![]()
