

Proper configuration of the TempDB system database is crucial for optimal performance of a SQL Server instances during heavy loads. The recommended strategy is to create multiple data files, one per CPU core (logical processor), but not more than 8. Those files should be equal in size and with the same autogrowth settings. In past, this had to be done manually after the initial installation of SQL Server so many instances went to production with default values. SQL Server 2016 allows the configuration of TempDB DURING the setup process and it also sets better default settings than ever before.
Here’s a screenshot from the current community preview version of SQL 2016:
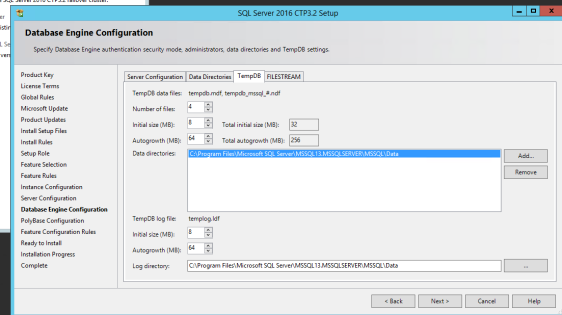
The first TempDB data file is still named tempdev.mdf for compatibility reasons while all other files are set to temp2, temp3, and so on. .
The default number of files is set according to the recommendations from Microsoft: if the number of logical processors is less than or equal to 8, use the same number of data files as logical processors.
The default initial size is set too low, so everyone should adjust that parameter according to his needs. Same goes for the Autogrowth parameter. Notice that there is no option to set the autogrowth in percents which is a great thing as it prevents taking that bad option which, btw, used to be default in previous versions of SQL Server.
Finally, the directories for data and log files can be changed from default values.
Advanced settings
There are a couple of important points that are not visible from that setup screen:
If there are multiple TempDB database files then all files will grow at the same and all allocations will use uniform extents. In other words, the behavior of the trace flags 1117 and 1118 is enabled for TempDB by default and those trace flags are not required any more.
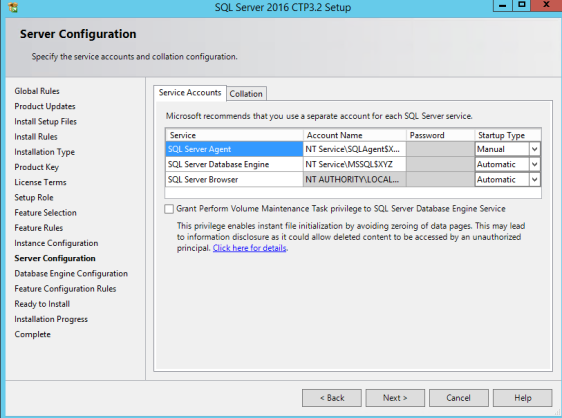
Instant file initialization can now be requested during setup on this screen:
Conclusion
In my opinion, the possibility to configure TempDB during the installation of SQL Server is a great improvement for several reasons:
- it will enforce best practices
- it will prevent some bad practices like percentage autogrowth
- it will enable the trace flags behavior that are often overlooked
I’m curious to see what improvements will be added in the release version of SQL 2016.
