

1. Using the OVER clause with aggregate functions
The following sample is from BOL:
-------------------------------------
USE AdventureWorks2008R2;
GO
SELECT SalesOrderID, ProductID, OrderQty
,SUM(OrderQty) OVER(PARTITION BY SalesOrderID) AS 'Total'
,AVG(OrderQty) OVER(PARTITION BY SalesOrderID) AS 'Avg'
,COUNT(OrderQty) OVER(PARTITION BY SalesOrderID) AS 'Count'
,MIN(OrderQty) OVER(PARTITION BY SalesOrderID) AS 'Min'
,MAX(OrderQty) OVER(PARTITION BY SalesOrderID) AS 'Max'
FROM Sales.SalesOrderDetail
WHERE SalesOrderID IN(43659,43664);
-------------------------------------
If using subqueries, the script will be more complicated:
-------------------------------------
SELECT A.SalesOrderID, B.ProductID, B.OrderQty, A.Total, A.Avg, A.Count, A.Min, A.Max
FROM
(
SELECT SalesOrderID
,SUM(OrderQty) AS 'Total'
,AVG(OrderQty) AS 'Avg'
,COUNT(OrderQty) AS 'Count'
,MIN(OrderQty) AS 'Min'
,MAX(OrderQty) AS 'Max'
FROM Sales.SalesOrderDetail
WHERE SalesOrderID IN(43659,43664)
GROUP BY SalesOrderID
) A
INNER JOIN Sales.SalesOrderDetail B
ON A.SalesOrderID=B.SalesOrderID
GO
-------------------------------------
However, if the table size is big, you'd better verify the performance of over clause comparing with subqueries first. Based on my testing, the performance of over clause is not as good as subqueries. Here is the execution plan and statistics of both 2 queries:
a) OVER Clause query

The execution plan uses the table spool to cache the temporary data, and generate aggregation data.

the io statistics reveals there are 3 physical reads and 55 locical reads
b) subqueries

here the execution plan seek the table 2 times.

Physical reads is the same 3, but there is only 12 logical reads. the sql server elapsed time is only 27ms.
looks like subquery is faster than OVER clause 🙂 , But OVER Clause with Aggregation function makes your script concise and easy to understand.
2. CTE - Common Table Expressions
CTE is another way to make you code concise and efficient.
a) Recursive Queries Using CTE
Returning hierarchical data is a common use of recursive queries, for instance, displaying employees in an organizational chart. If you are familiar with oracle sqlplus, you can get the hierarchical data by the "Connect by prior" command just like code below:
--Oracle code--
SELECT employee_id, manager_id, first_name, last_name
FROM employee
START WITH employee_id = 1
CONNECT BY PRIOR employee_id = manager_id;
In SQL Server, you can use the Recursive CTE query get the same result. here is the sample:
-------------------------------------
CREATE TABLE employee (
employee_id INTEGER,
manager_id INTEGER,
first_name VARCHAR(10) NOT NULL,
last_name VARCHAR(10) NOT NULL,
title VARCHAR(20),
salary INT
);
insert into employee (EMPLOYEE_ID, MANAGER_ID,FIRST_NAME,LAST_NAME,TITLE,SALARY)
values (6,4,'Jane','Brown','Support Person',45000),
(3,2,'Fred','Hobbs','Sales Person',200000),
(4,1,'Susan','Jones','Support Manager',500000),
( 1 ,0, 'James','Smith','CEO',800000),
(2 ,1,'Ron','Johnson','Sales Manager',600000),
(5,2,'Rob' ,'Green','Sales Person', 40000);
;WITH DIRECTREPORT(EMPLOYEE_ID, MANAGER_ID,FIRST_NAME,LAST_NAME,TITLE,SALARY, LEVEL)
AS
(
SELECT EMPLOYEE_ID, MANAGER_ID,FIRST_NAME,LAST_NAME,TITLE,SALARY, 0 AS LEVEL
FROM employee
WHERE MANAGER_ID=0
UNION ALL
SELECT e.EMPLOYEE_ID, e.MANAGER_ID,e.FIRST_NAME,e.LAST_NAME,e.TITLE,e.SALARY, d.LEVEL+1 AS LEVEL
FROM employee e INNER JOIN DIRECTREPORT d on e.manager_id=d.EMPLOYEE_ID
)
SELECT EMPLOYEE_ID, MANAGER_ID,FIRST_NAME,LAST_NAME,TITLE,SALARY, LEVEL
FROM DIRECTREPORT
-------------------------------------
the output is like
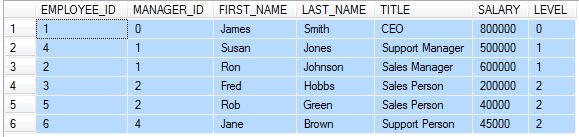
b) Delete duplicate row with CTE
you can not only select data from CTE but also delete data by CTE. Without CTE, deleting duplicated row is not easy, you can find some ways with the KB below
http://support.microsoft.com/kb/139444
http://support.microsoft.com/kb/70956
However, with CTE there is very nice way to implement it. Here is the script:
-------------------------------------
CREATE TABLE dup(a int, b int)
GO
insert into dup(a,b) values(1,1),(1,1),(1,1),(2,2),(2,2),(3,3),(4,4),(4,4),(4,4),(5,5),(5,5)
GO
;WITH dupcte (a,b, row_count)
AS
(
SELECT a,b,
ROW_NUMBER() OVER(PARTITION BY a,b ORDER BY a,b) AS row_count
FROM dup
)
DELETE
FROM dupcte
WHERE row_count > 1
GO
GO
select * from dup
GO
-------------------------------------
The Final output is like

3. Merge Statement
The T-SQL Merge Statement is simliar with Oracle sqlplus "Merge Into"(study from Oracle? 🙂 ). It provide you an easy way to impletement:
If find the same data in the destination table then update, or else insert a new row.
Sample code:
-------------------------------------
--Create the employee table and insert the testing data with the code in 2.a
DECLARE @EMPLOYEE_ID INT, @MANAGER_ID INT, @SALARY INT
DECLARE @FIRST_NAME VARCHAR(10), @LAST_NAME VARCHAR(10), @TITLE VARCHAR(20)
SET @EMPLOYEE_ID=4
SET @MANAGER_ID=1
SET @FIRST_NAME='Susan'
SET @LAST_NAME='Jones'
SET @TITLE='Support Manager'
SET @SALARY=550000
--if find employee then update, or else insert.
MERGE INTO EMPLOYEE AS TARGET
USING (VALUES(@EMPLOYEE_ID, @MANAGER_ID,@FIRST_NAME,@LAST_NAME,@TITLE,@SALARY))
AS SOURCE (EMPLOYEE_ID, MANAGER_ID,FIRST_NAME,LAST_NAME,TITLE,SALARY)
ON TARGET.EMPLOYEE_ID=Source.EMPLOYEE_ID
WHEN MATCHED THEN
UPDATE SET SALARY=SOURCE.SALARY
WHEN NOT MATCHED BY TARGET THEN
INSERT (EMPLOYEE_ID, MANAGER_ID,FIRST_NAME,LAST_NAME,TITLE,SALARY)
VALUES (@EMPLOYEE_ID, @MANAGER_ID,@FIRST_NAME,@LAST_NAME,@TITLE,@SALARY);
-------------------------------------
4. GO
Sorry, this is not T-SQL function, "GO" is only a command of sqlcmd and SSMS. why I mention it here is there is a interesting parameter [count] for it.
GO [count]
The batch preceding GO will execute the specified number of times.so if you want to run a simple script multiple times, you can try it.
