

How does Scalar UDF Inlining affect the performance of scalar functions?
SQL Server 2019 introduces a new feature called “Scalar UDF Inlining”. In a nutshell, this feature will take a scalar function and it will inline it into the query plan (similar to an Inline Table Valued Function (TVF), or even a view).
This blog post will examine changes to the query plan and performance when Scalar UDF Inlining is occurring.
I have previously blogged about function performance – here and here. For a quick recap, the performance test ranks these function in duration. The order of the types of functions by duration is Inline TVF, Scalar UDF, and then finally a Multi-Statement TVF (MSTVF) – and the MSTVF is way behind the other two types of functions.
I’m using a Linux (Ubuntu) VM with SQL Server 2019 to perform these comparison performance tests. I use one database in the SQL 2019 compatibility level, and another one in the SQL 2017 compatibility level. I’m using the same performance test used in the previous blog posts.
Creating the test environment
I start off by creating two databases, and putting one of them in the SQL 2017 compatibility level:
IF DB_ID('FunctTest140') IS NULL
CREATE DATABASE FunctTest140;
ALTER DATABASE FunctTest140 SET COMPATIBILITY_LEVEL = 140;
GO
IF DB_ID('FunctTest150') IS NULL
CREATE DATABASE FunctTest150;
GONext, I create a table with a million rows of random, and three functions. These functions perform the same work, the only difference is in the type of function. The functions remove the non-numeric characters from the string, and return the result in the order that the digits appear. This table and the functions are created in both databases:
IF OBJECT_ID('dbo.temp1', 'U') IS NOT NULL DROP TABLE dbo.temp1;
WITH cteSymbols AS
(
SELECT CharSymbol
FROM (VALUES ('('), ('('), ('-'), (' '), ('-('), (')-'), ('.'), (','), ('/'), ('@')) dt (CharSymbol)
)
SELECT TOP (1000000)
IDENTITY(INTEGER) AS RowID,
CONVERT(VARCHAR(30), s1.CharSymbol + CONVERT(VARCHAR(8), ABS(so1.object_id) % 10000000,0) +
s2.CharSymbol + CONVERT(VARCHAR(8), ABS(so2.object_id) % 10000000,0) +
s3.CharSymbol
) AS StringOfNumbersWithNonNumbers
INTO dbo.temp1
FROM cteSymbols s1
CROSS JOIN cteSymbols s2
CROSS JOIN cteSymbols s3
CROSS JOIN sys.all_objects so1
CROSS JOIN sys.all_objects so2;
-- let's look at a few rows to see what we have
SELECT * FROM dbo.temp1 WHERE RowID <= 10;
GO
-- Inline table valued function
IF OBJECT_ID('dbo.ITVF_TEST') IS NOT NULL DROP FUNCTION dbo.ITVF_TEST;
GO
CREATE FUNCTION dbo.ITVF_TEST (@Input VARCHAR(30))
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
SELECT (SELECT SUBSTRING(@Input,N,1)
FROM (VALUES (1),(2),(3),(4),(5),(6),(7),(8),(9),(10),(11),(12),(13),(14),(15),(16),(17),(18),(19),(20),(21),(22),(23),(24),(25),(26),(27),(28),(29),(30)) AS x(N)
WHERE N<=LEN(@Input)
AND SUBSTRING(@Input,N,1) LIKE ('[0-9]')
ORDER BY N
FOR XML PATH(''), TYPE).value('.','VARCHAR(30)') AS StringNumbersOnly;
GO
-- Multi-statement table valued function
IF OBJECT_ID('dbo.MSTVF_TEST') IS NOT NULL DROP FUNCTION dbo.MSTVF_TEST;
GO
CREATE FUNCTION dbo.MSTVF_TEST (@Input VARCHAR(30))
RETURNS @Output TABLE (StringNumbersOnly VARCHAR(30))
WITH SCHEMABINDING
AS
BEGIN
INSERT INTO @Output (StringNumbersOnly)
SELECT (SELECT SUBSTRING(@Input,N,1)
FROM (VALUES (1),(2),(3),(4),(5),(6),(7),(8),(9),(10),(11),(12),(13),(14),(15),(16),(17),(18),(19),(20),(21),(22),(23),(24),(25),(26),(27),(28),(29),(30)) AS x(N)
WHERE N<=LEN(@Input)
AND SUBSTRING(@Input,N,1) LIKE ('[0-9]')
ORDER BY N
FOR XML PATH(''), TYPE).value('.','VARCHAR(30)') AS StringNumbersOnly;
RETURN;
END;
GO
-- Scalar function
IF OBJECT_ID('dbo.SF_TEST') IS NOT NULL DROP FUNCTION dbo.SF_TEST;
GO
CREATE FUNCTION dbo.SF_TEST (@Input VARCHAR(30))
RETURNS VARCHAR(30)
WITH SCHEMABINDING
AS
BEGIN
DECLARE @Output VARCHAR(30);
SELECT @Output = (SELECT SUBSTRING(@Input,N,1)
FROM (VALUES (1),(2),(3),(4),(5),(6),(7),(8),(9),(10),(11),(12),(13),(14),(15),(16),(17),(18),(19),(20),(21),(22),(23),(24),(25),(26),(27),(28),(29),(30)) AS x(N)
WHERE N<=LEN(@Input)
AND SUBSTRING(@Input,N,1) LIKE ('[0-9]')
ORDER BY N
FOR XML PATH(''), TYPE).value('.','VARCHAR(30)');
RETURN @Output;
END;
GOThe following query tests that all the functions do truly return the same data:
SELECT TOP (10)
t.RowID,
t.StringOfNumbersWithNonNumbers AS StringOfNumbers,
dbo.SF_TEST(t.StringOfNumbersWithNonNumbers) AS ScalarFunction,
MSTVF.StringNumbersOnly AS MultiStatementTVF,
ITVF.StringNumbersOnly AS InlineTVF
FROM dbo.temp1 t
CROSS APPLY dbo.MSTVF_TEST(t.StringOfNumbersWithNonNumbers) MSTVF
CROSS APPLY dbo.ITVF_TEST(t.StringOfNumbersWithNonNumbers) ITVF;
Differences in the query plans
The first thing that I want to do is to compare the difference in the query plans produced in each database. I run the following query in each database with the actual execution plan turn on:
SELECT TOP (10)
t.RowID,
t.StringOfNumbersWithNonNumbers AS StringOfNumbers,
dbo.SF_TEST(t.StringOfNumbersWithNonNumbers) AS ScalarFunction
FROM dbo.temp1 t;For the database in the SQL 2017 compatibility level, the resulting query plan is:

SQL 2017 Query Plan
Hovering over the Select operator:
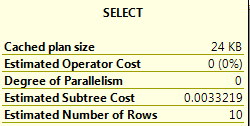
SQL 2017 query plan cost
For the database in the SQL 2019 compatibility level, the resulting query plan is:

SQL 2019 Query Plan
Hovering over the Select operator:
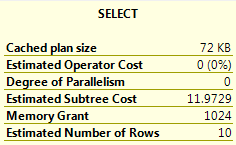
SQL 2019 Query Plan Cost
A casual look shows that the Scalar UDF Inlining has occurred. The work being performed by the scalar function has been inlined into the query plan. In SQL 2017, all of the work is shown by a “Compute Scalar” operator. This operator hides all of the underlying work going on in the Scalar UDF. This results in a query plan with a cost that does not truly represent the work going on.
The performance test
The next step is to test the performance of each of the functions. This run is performed 11 times for each type of function, in each of the databases. Why 11 times? Well, I did it once, then decided to run this in a batch for ten loops. The performance testing code is:
-- PERFORMANCE TESTING TIME!!!
-- table to store the times:
IF OBJECT_ID('tempdb.dbo.#temp2') IS NOT NULL DROP TABLE #temp2;
CREATE TABLE #temp2 (
RowID INTEGER IDENTITY,
FunctionName sysname,
ActionDateTime DATETIME2(7) NOT NULL DEFAULT(SYSDATETIME()));
--------- INLINE TABLE-VALUED FUNCTION -----------
IF OBJECT_ID('dbo.ITVF_RESULTS') IS NOT NULL DROP TABLE dbo.ITVF_RESULTS;
INSERT INTO #temp2 (FunctionName) VALUES ('ITVF_TEST');
SELECT *
INTO dbo.ITVF_RESULTS
FROM dbo.temp1
CROSS APPLY dbo.ITVF_TEST(StringOfNumbersWithNonNumbers)
INSERT INTO #temp2 (FunctionName) VALUES ('ITVF_TEST');
--------- MULTI_STATEMENT TABLE-VALUED FUNCTION -----------
IF OBJECT_ID('dbo.MSTVF_RESULTS') IS NOT NULL DROP TABLE dbo.MSTVF_RESULTS;
INSERT INTO #temp2 (FunctionName) VALUES ('MSTVF_TEST');
SELECT *
INTO dbo.MSTVF_RESULTS
FROM dbo.temp1
CROSS APPLY dbo.MSTVF_TEST(StringOfNumbersWithNonNumbers)
INSERT INTO #temp2 (FunctionName) VALUES ('MSTVF_TEST');
--------- SCALAR FUNCTION ------------
IF OBJECT_ID('dbo.SF_Results') IS NOT NULL DROP TABLE dbo.SF_Results;
INSERT INTO #temp2 (FunctionName) VALUES ('SF_TEST');
SELECT *, dbo.SF_TEST(StringOfNumbersWithNonNumbers) AS StringNumbersOnly
INTO dbo.SF_Results
FROM dbo.temp1;
INSERT INTO #temp2 (FunctionName) VALUES ('SF_TEST');
---------- Show the testing results -----------
WITH cte AS
(
SELECT t.FunctionName,
DATEDIFF(MICROSECOND, MIN(t.ActionDateTime), MAX(t.ActionDateTime)) AS [Duration (microseconds)]
FROM #temp2 t
GROUP BY t.FunctionName
)
SELECT DB_NAME() AS DatabaseName,
FunctionName,
[Duration (microseconds)],
CONVERT(NUMERIC(5,2), (cte.[Duration (microseconds)] * 1.0 / SUM(cte.[Duration (microseconds)]) OVER () * 1.0) * 100.0) AS PercentOfBatch
FROM cte
ORDER BY [Duration (microseconds)];
GO 10The results for SQL 2017:
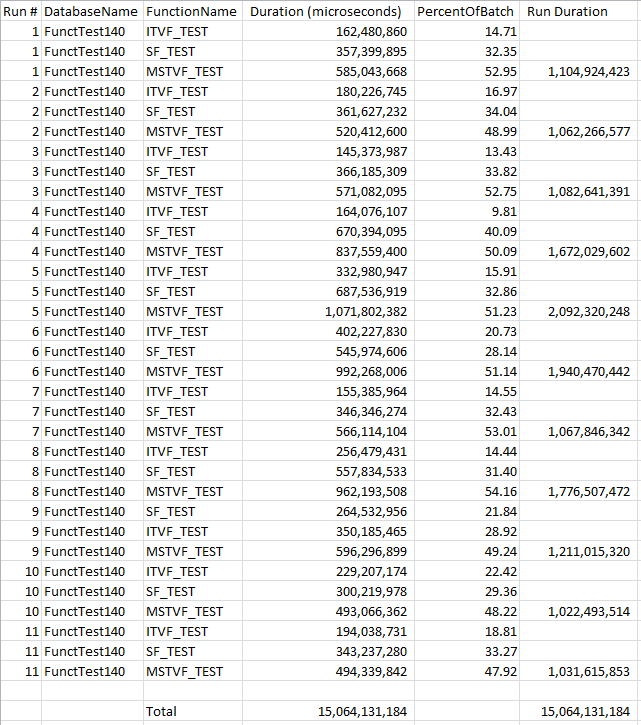
SQL 2017 Results
As expected (based on the other two blog posts), the MSTVF is the slowest. Overall, the inline TVF is the fastest, with the scalar UDF falling between the two. For each batch, the Inline TVF is about 20% of the batch, the Scalar UDF is about 35%, and the MSTVF is about 45%.
How does the Scalar UDF Inlining help out? Well, the results for that are:
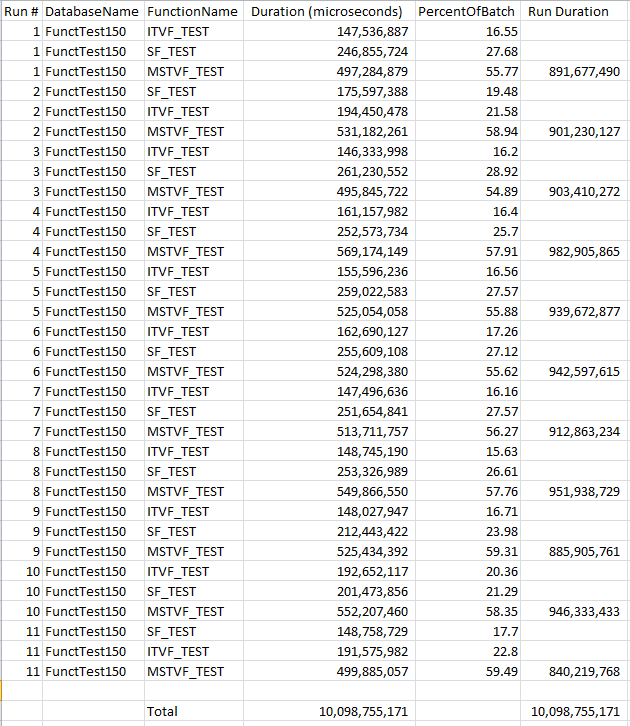
SQL 2019 Results
In this result set, we can see that the Scalar functions have improved, but the overall ranking has remained the same. The scalar functions are still between the Inline TVF and the MSTVF. However, when you look at the percent of batch, the Inline TVF is about 17%, the Scalar UDF is about 25% and the MSTVF is about 58%.
And if you look at the overall duration for all batches, we see that the SQL 2019 runs shaved off about 1/3 of the total time.
Both of these show that Scalar UDF Inlining is improving those Scalar UDFs!
In Conclusion…
We can see that the Scalar UDF Inlining is improving the performance of the Scalar UDFs. When the batches are running in 1/3 less time, that is a pretty dramatic improvement.
Going into this test, I was hopeful that the Scalar UDF Inlining performance would be on par with the Inline TVFs. While the performance has dramatically improved, it wasn’t enough to match the Inline TVFs. This means that when you are working with functions, the best choice is still to use an Inline TVF where possible. This also shows that we still want to avoid using a MSTVF.
Be sure to read the Microsoft article (the link is in the first line of this post) for all that you can, and can’t, do with Scalar UDF Inlining.
The post Scalar UDF Inlining in SQL Server 2019 appeared first on Wayne Sheffield.
