

Sometimes loading new data or even changes into a table just isn’t going to work. You need a complete reload. A summary table of data from the previous month, for example. It just doesn’t make sense to do an update. You delete/truncate and you re-load. Unfortunately, this leaves the table unusable for a period of time, and depending on your usage and load time that downtime may not be acceptable.
Now if this table is paritioned you’d use SWITCH and bring in a new partition.
For those that don’t know, when a table is partitioned, you can create a new empty partition, and a new empty table, load the table, make the table exactly match the partition (structure, check constraints, & indexes for example) and you can SWITCH it in. The SWITCH part is a metadata operation and is fast!
But what do you do if the table isn’t partitioned? Well, I was having a conversation with Andy Mallon (b/t) and he reminded me of something.
Technically all tables are partitioned. Go take a look at the system view sys.partitions. In it, you will find an entry for every table partitioned or not. Those that are not partitioned only have a single entry for partition 1. As a result, you can, in fact, SWITCH into an empty table. So for example (of course):
-- Set up the initial table
CREATE TABLE dbo.DestinationTable (
Id INT NOT NULL IDENTITY(1,1) CONSTRAINT pk_DestinationTable PRIMARY KEY,
Col1 varchar(50) CONSTRAINT df_DestinationTable DEFAULT(''),
Col2 varchar(50) CONSTRAINT ck_DestinationTable CHECK (Col2 IN ('Yes','No'))
);
CREATE INDEX ix_DestinationTable ON dbo.DestinationTable(Col1);
GRANT SELECT ON dbo.DestinationTable TO Doc;
GO
CREATE TRIGGER dbo.trDestinationTable
ON [dbo].[DestinationTable]
FOR DELETE, INSERT, UPDATE
AS
BEGIN
SET NOCOUNT ON
END;
GO
INSERT INTO dbo.DestinationTable VALUES ('123','Yes'),
('789','Yes'),('345','Yes'),('901','No');
GOIn order to do the swap we need another table that’s identical (almost) but with different data.
CREATE TABLE dbo.LoadTable (
Id INT NOT NULL IDENTITY(1,1) CONSTRAINT pk_LoadTable PRIMARY KEY,
Col1 varchar(50),
Col2 varchar(50) CONSTRAINT ck_LoadTable CHECK (Col2 IN ('Yes','No'))
);
GO
INSERT INTO dbo.LoadTable VALUES ('abc','No'),
('ghi','No'),('mno','Yes'),('stu','No');
GO
CREATE INDEX ix_LoadTable ON dbo.LoadTable(Col1);
GONotice that I have the same indexes, the same check constraints, and the same table structure. I do not have the same default constraints, triggers, and permissions. (I do not promise this is the extent of the requirements for SWITCHing just part of it.) Also I created my non-clustered indexes (NCIs) after loading the data. In some cases, this can be quite a bit faster, particularly with large amounts of data. If you are going to be doing this on a regular database I recommend testing it both ways.
Now let’s move the data into the DestinationTable.
-- Before SELECT * FROM dbo.DestinationTable; GO -- Clean out the old data TRUNCATE TABLE dbo.DestinationTable; -- Normally there is a PARTITION # at the end of the statement -- In this case, it isn't necessary. You can include it but it -- will give you a warning that it's been ignored because the -- table isn't actually partitioned. ALTER TABLE dbo.LoadTable SWITCH TO dbo.DestinationTable; GO -- After SELECT * FROM dbo.DestinationTable; GO
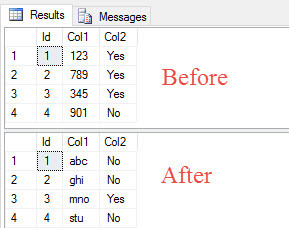
And again, remember that TRUNCATE and SWITCH are both fast operations. In fact, table size will have a very very limited effect on this part of the process, meaning that the actual down time for the users is negligable. (Subsecond or maybe seconds).
Filed under: Microsoft SQL Server, Partitioning, Performance, T-SQL Tagged: microsoft sql server, Partitioning, T-SQL 






![]()
