

This post talks about having primary replica jobs. That is, jobs that will only run on the primary replica of an availability group.
Overview
An Availability Group (AG) takes one or more databases, and copies all changes to those databases from the primary replica to all the secondary replicas. However, anything that is not part of those databases are not copied over. Microsoft documents all of these in this article. This includes jobs that run against a database in an AG. Such jobs might include index or statistics maintenance, partition switching, etc. In short, any job that modifies the database needs to run against the primary replica only.
If the AG fails over to another replica, you want these processes to just keep on running. This means that you need these jobs installed on all the replicas, in the same state (enabled) and with the same schedule. However, trying to do these actions will cause the job to fail on the secondary replicas, since it can’t write to the database. So we need a way so that the job always runs, but it only does the work if the current SQL Server instance is the primary replica for this AG. Synchronizing jobs, and the ability of those jobs to run, is beyond the scope of this article.
Creating primary replica jobs
Obviously, what we need to do is to create the job so that it is aware of whether it is running on the instance that is the primary replica, and only proceed if it is. This last part “only proceed if it is” gives us a clue of what we need to do. We need to put the check and the work into separate job steps, and only run the work if the check is successful.
Do you see the next clue here? “if the check is successful”. We need to run a check to determine whether this is a primary replica. If successful, run the next part of the job. If not, stop. While there isn’t a way to tell a job whether or not to continue from within a job step, there are a few ways that we can stop the job completely if we need to.
Stopping the job, method 1
The first method for how to stop a job is to just raise an error. This method requires that the job step be configured to stop the job successfully on a failure. The text of the job step is simply:
IF NOT EXISTS ( SELECT 1
FROM sys.dm_hadr_availability_group_states hags
JOIN sys.availability_groups ags ON hags.group_id = ags.group_id
WHERE hags.primary_replica = @@SERVERNAME
AND ags.name = 'MyAGName'
)
BEGIN
RAISERROR('Not the primary replica', 16, -1);
END;And the job step’s properties will look like this:

Job Step configuration
When the job runs, if it’s not the primary replica for the specified AG, then the job step fails. Because the job step does not fail the job, the job is successful. If you view the job history, it will look like:
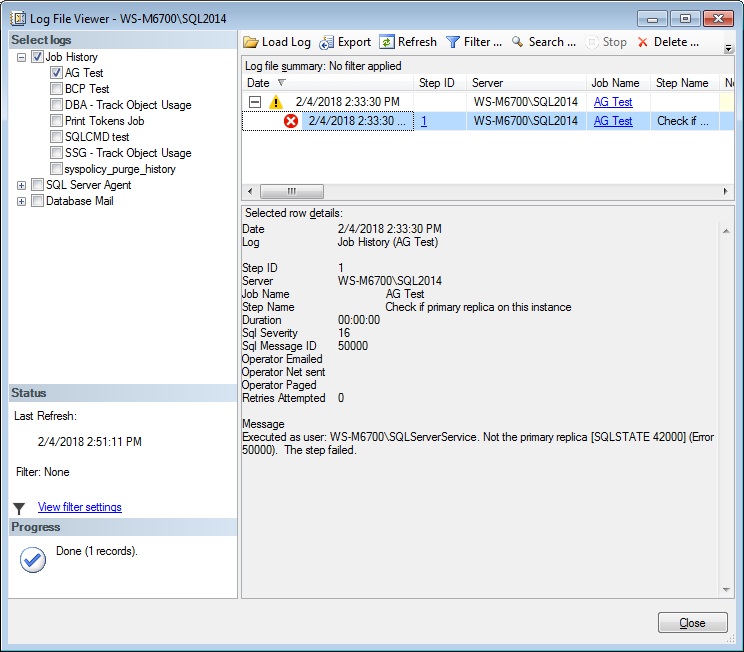
Job history
What I like about this method is the simplicity and that everything is in the one job. What I don’t like is seeing yellow and red when viewing the job history. When it does run on the primary replica, the job history will be green, so you can tell when it was the primary replica.
Stopping the job, method 2
A second way to stop the job is to execute the msdb.dbo.sp_stop_job stored procedure. This requires you to know either the job name or the job id. While we could hard code this, I like to make things dynamic when possible.
There is a way to know the job_id of the job dynamically. That is by using a SQL Agent token. Note that although the documentation says that JOBNAME and STEPNAME are valid, I (and others) cannot get those to work. However, the JOBID token does work. The job step will look like this:
IF NOT EXISTS ( SELECT 1
FROM sys.dm_hadr_availability_group_states hags
JOIN sys.availability_groups ags ON hags.group_id = ags.group_id
WHERE hags.primary_replica = @@SERVERNAME
AND ags.name = 'MyAGName'
)
BEGIN
DECLARE @job_id UNIQUEIDENTIFIER;
SET @job_id = CONVERT(UNIQUEIDENTIFIER, CONVERT(VARBINARY(34), $(ESCAPE_SQUOTE(JOBID)), 1));
EXECUTE msdb.dbo.sp_stop_job @job_id = @job_id;
END;If this step stops the job, then the job history reports being cancelled. If you view the job history, it will look like:
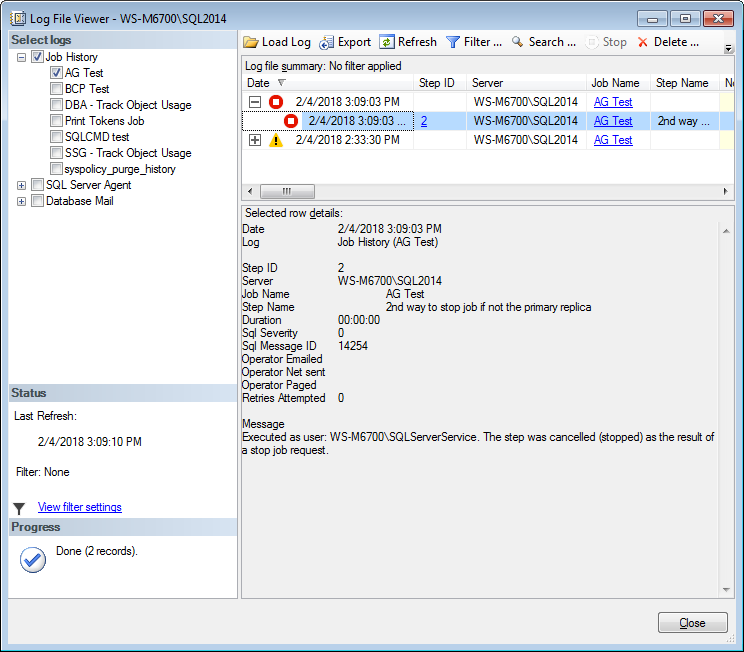
Stopping job with sp_stop_job
What I like about this method is the simplicity and that everything is in the one job. What I don’t like is seeing red when viewing the job history. When this does run on the primary replica, the red will (should) be green, so you can tell when it was the primary replica. This method is slightly more complex than the other methods, but not enough to really make a difference.
Start another job
Another way to handle this is to have this job start another job. In this case, the job with the test has the schedule attached to it, and if it is the primary replica, it starts another job. The second job needs to be disabled and not have a schedule. The code for this method would look like:
IF EXISTS ( SELECT 1
FROM sys.dm_hadr_availability_group_states hags
JOIN sys.availability_groups ags ON hags.group_id = ags.group_id
WHERE hags.primary_replica = @@SERVERNAME
AND ags.name = 'MyAGName'
)
BEGIN
EXECUTE msdb.dbo.sp_start_job @job_name = N'Job to run';
END;What I like about this method is the simplicity and that the job history shows all green. What I don’t like is having twice as many jobs and having to hard-code the job to be run. Additionally, you can’t tell by looking at the job history when the job ran on the primary replica.
Programming Notes
In all three of these methods, the code references the AG name (MyAGName). If you only have one AG on the instance, then this line is not necessary. However, since you can have more than one AG on an instance, and each AG can have a different primary replica, I’m showing how to handle this.
Additionally, there is another way to determine if the current server is the primary replica, but this is on a database-by-database method. Just use the system scalar function sys.fn_hadr_is_primary_replica and pass in the database name to check.
Conclusion
In this post, I have shown three different ways to create primary replica jobs that only run if it is on the primary replica. The job is installed and enabled on all the replicas, and the work will only be performed on the primary replica. All three of these methods are viable methods of accomplishing this. You can use whichever method that you prefer. The order that I like to use these methods is 1): RAISERROR (simplicity), 2): Start another job (don’t like seeing red on the job history), then 3): using sp_stop_job
The post Primary Replica Jobs appeared first on Wayne Sheffield.
