

One of the most basic things to improve performance in our queries is using indexes, but this doesn't mean that we can blindly create them for all our tables, or just thinking that it is enough to create them only for the columns we use to "search", yes, this could be beneficial if our tables are now big enough, our system is not under a great I/O pressure.
But for high concurrency systems, queries to large tables or more complex T-SQL statements, we could tune indexes a little bit more, and try to avoid disk reads as possible as we can do it.
What we can do to improve performance is to avoid key lookups whenever possible.
 |
| Key lookup icon |
The Key Lookup operator works this way: you have an index defined for your search argument, the index is used to locate the record, and then once located, an additional search is made to locate the record and retrieve the required columns in our query.
So... for example, if the query is not used often and only to locate a single record, this is not an issue, but for queries that manipulate or select big sets of data, an additional disk read for each record can painfully affect your performance.
I will demonstrate in the following example how to locate a Key lookup and how to fix it
- Let us locate the query, I use a simple select from AdventureWorks database and the current index definition :
select ProductNumber
from Production.Product
where ProductNumber = 'CA-7457'
--Index
CREATE UNIQUE NONCLUSTERED INDEX [AK_Product_ProductNumber]
ON [Production].[Product]
(
[ProductNumber] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF,
IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON,
ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
- With the current index definition for that table, if we execute the select statement, an index seek is performed (everything ok until now)


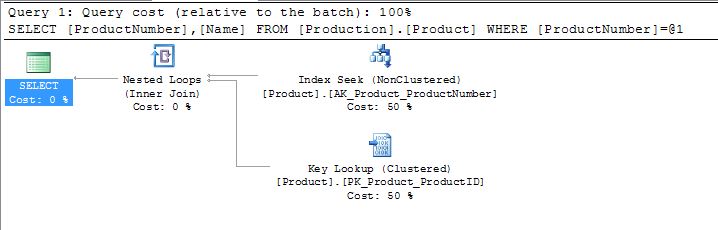
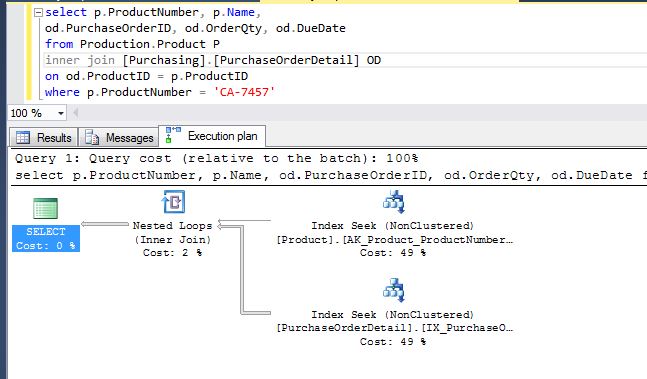
- But what if, we add another column to the SELECT statement, let's say Name:
select ProductNumber, Name
from Production.Product
where ProductNumber = 'CA-7457'
- Now a key lookup is performed because the index is used just to locate the product number record, and an additional disk read must be performed to retrieve the name:

- What if we change the index definition to include the Name column?
CREATE UNIQUE NONCLUSTERED INDEX [AK_Product_ProductNumber]
ON [Production].[Product]
(
[ProductNumber] ASC
)
INCLUDE ([Name])
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF,
DROP_EXISTING = OFF, ONLINE = OFF,
ALLOW_ROW_LOCKS = ON,
ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
- Now if we execute the same query, an index seek is performed, we eliminated the key lookup and removed the additional I/O overhead just with including that column in the index.
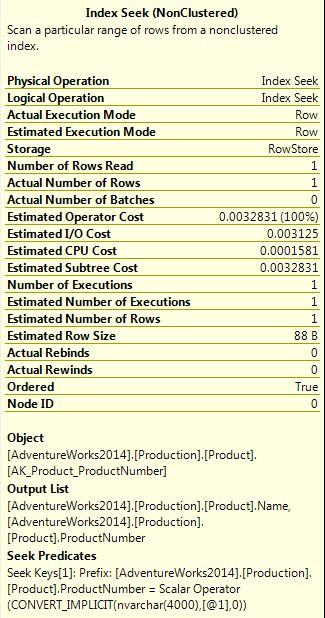
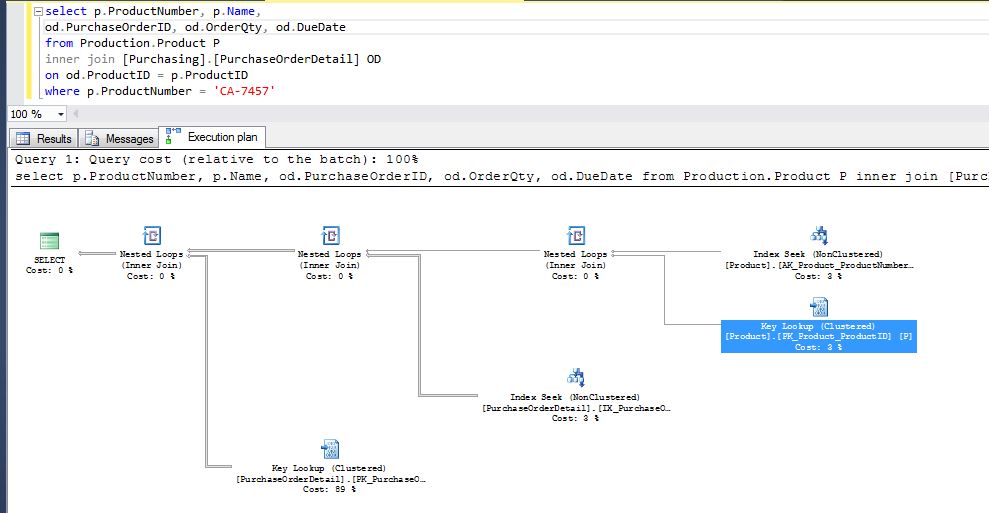
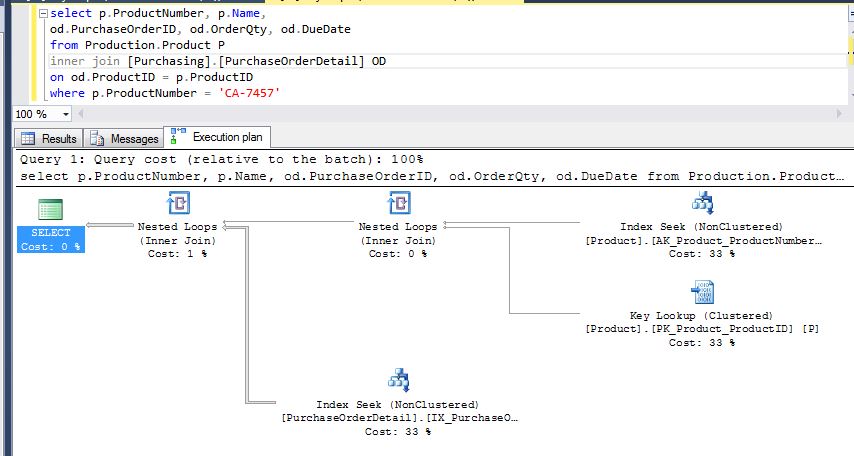
- The previous example was just for a simple select just for one table, and the performance is almost the same for both cases, but for the next example we can see the query execution is improved using index seeks instead of key lookups:
Fist execution, indexes doesn't have included columns, key lookups are used Second execution: After adding included columns for the index in one of the tables Third execution: After adding included columns for the index in the remaining table

Always remember that you must test any of these changes prior to applying it to production, you must measure the performance before and after doing these changes to check if the additional overhead modifying your indexes worth the bonus in performance you could obtain.
