

Here’s my take on partitioning. I’ll be focusing on getting queries to perform on partitioned tables, and not on partition maintenance, which can be its own headache. This is the first part in a series I’m planning to write, so this post may not answer all the questions.
Partitioning disclaimer
I feel like it’s necessary to add a disclaimer: Partitioning is not designed as a performance feature, its strengths are in moving large amounts of data in a single command. Truncating an entire partition is also an easy way to delete stale data without using a lot of space in the transaction log.
Setting up a partitioned table
CREATE PARTITION FUNCTION Posts_Partition_Function (DATETIME)
AS RANGE RIGHT FOR VALUES ('2008-01-01',
'2009-01-01',
'2010-01-01',
'2011-01-01',
'2012-01-01',
'2013-01-01',
'2014-01-01',
'2015-01-01',
'2016-01-01',
'2017-01-01',
'2018-01-01') ;
GO
CREATE PARTITION SCHEME Posts_Partition_Scheme
AS PARTITION Posts_Partition_Function ALL
TO ([PRIMARY]) ;
GOAnd creating a Posts_Partitioned table, in StackOverflow2010, to demo the scripts:
USE [StackOverflow2010] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO IF NOT EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'[dbo].[Posts_Partitioned]') AND type in (N'U')) BEGIN CREATE TABLE [dbo].[Posts_Partitioned]( [Id] [int] IDENTITY(1,1) NOT NULL, [AcceptedAnswerId] [int] NULL, [AnswerCount] [int] NULL, [Body] [nvarchar](max) NOT NULL, [ClosedDate] [datetime] NULL, [CommentCount] [int] NULL, [CommunityOwnedDate] [datetime] NULL, [CreationDate] [datetime] NOT NULL, [FavoriteCount] [int] NULL, [LastActivityDate] [datetime] NOT NULL, [LastEditDate] [datetime] NULL, [LastEditorDisplayName] [nvarchar](40) NULL, [LastEditorUserId] [int] NULL, [OwnerUserId] [int] NULL, [ParentId] [int] NULL, [PostTypeId] [int] NOT NULL, [Score] [int] NOT NULL, [Tags] [nvarchar](150) NULL, [Title] [nvarchar](250) NULL, [ViewCount] [int] NOT NULL, CONSTRAINT [PK_Posts__Id_CreationDate] PRIMARY KEY CLUSTERED ( [Id], [CreationDate] )ON [Posts_Partition_Scheme](CreationDate) ) END GO
Loading some data into Posts_Partitioned
I used the SSIS Import/Export Data Wizard and specified all the columns except the Id column. There’s about 3.7 million rows loaded.
Creating some indexes and comparing performance before and after
Query performance on partitioned tables can be confusing. Yes, queries can run faster on partitioned tables IF they can use partition elimination. That means that the query contained the partitioning column in one of the predicates, like the WHERE clause or the JOIN. Then, the SQL Server optimizer is able to skip those partitions when running the query.
What I’m focusing on is whether a query performs better or worse after partitioning, whether the query is capable of partition elimination, and if it achieved that partition elimination.
First, we’ll create indexes, with the index on Posts_Partitioned aligned to the partition.
CREATE NONCLUSTERED INDEX ix_Posts_LastEditorUserId ON Posts(LastEditorUserId) INCLUDE (Score) GO CREATE NONCLUSTERED INDEX ix_Users_DisplayName ON Users(DisplayName) GO CREATE NONCLUSTERED INDEX ix_Posts_Partitioned_LastEditorUserId ON Posts_Partitioned(LastEditorUserId) INCLUDE (Score) ON Posts_Partition_Scheme(CreationDate) GO
Great! Let’s run a query on these tables with our brand new indexes.
SET STATISTICS IO ON; SELECT Score FROM Posts as p JOIN Users as u on u.Id = p.LastEditorUserId WHERE u.DisplayName = 'Community' --The Community user in StackOverflow is an internal user, --so it has a lot of posts! /* (118119 rows affected) Table 'Posts'. Scan count 1, logical reads 267, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Users'. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. */
What about the execution plan?
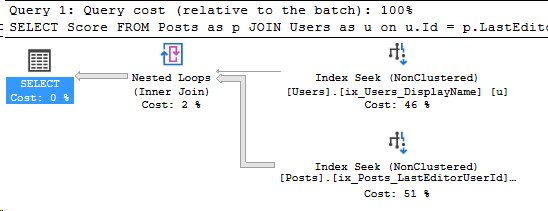
Looks pretty good to me.
The same query, same indexes on Posts with partition aligned indexes
SELECT Score FROM Posts_Partitioned as p JOIN Users as u on u.Id = p.LastEditorUserId WHERE u.DisplayName = 'Community' /* (118119 rows affected) Table 'Posts_Partitioned'. Scan count 12, logical reads 391, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Users'. Scan count 1, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. */
Uh-oh. This looks a little worse. Just to be sure, let’s look at the execution plan:

So what happened?
The first giveaway is that the query on Posts_Partitioned has a “Scan count” of 12. There’s more answers here though, let’s take a look at the Index Seek.
Here’s the properties of the Index Seek on Posts_Partitioned:

So this Index Seek had to access each partition to check if it had data for our Community user. That increased the amount of work done.
Summary of this example
This is an example of when a query didn’t achieve partition elimination, and therefore it did more work on the partitioned table. I hope to write some other posts on whether this issue could be fixed in the query, and other query patterns that can cause confusion when working with partitioning.
Stay tuned!
