

By Steve Bolton
…………In the last two installments of this series of amateur self-tutorials, I mentioned that the various means of detecting outliers with SQL Server might best be explained as a function of the uses cases, the context determined by the questions one chooses to ask of the data, the number and data types of the inputs and the desired mathematical properties of the outputs. The means of calculation in between the input and output stage may also be pertinent for performance reasons. Moreover, we can differentiate these aberrant data points we call “outliers” by their underlying causes, which must be matched with the correct response; it does us no good to find extreme values in our datasets if we can’t determine whether they were the product of faulty data collection, corruption during storage, natural random variations or some other root cause, then use that determination to handle them correctly. If we could build a matrix of outlier detection methods and their uses cases, then Grubbs’ Test would occupy a very narrow range. The inputs and questions the test can answer are quite constrained, since the test can only determine whether the highest and lowest values in a sample are outliers. It outputs a single test statistic, which can be used to output a single Boolean answer, rejecting or accepting the null hypothesis that there are no outliers in the dataset. The National Institute for Standards and Technology’s Engineering Statistics Handbook, one of the best online resources for explaining statistics in plain English, warns that, “If you suspect more than one outlier may be present, it is recommended that you use either the Tietjen-Moore test or the generalized extreme Studentized deviate test instead of the Grubbs’ test.” In the kinds of billion-row databases that SQL Server DBAs work with on a day-to-day basis, we can expect far more than a single aberrant data point just by random chance alone. Grubbs’ Test is more applicable to hypothesis testing on small samples in a research environment, but I’ll provide some code anyways in the chance that it might prove useful to someone in the SQL Server community on small datasets.
…………The “maximum normed residual test” originated with the a paper penned for the journal Technometrics by Frank E. Grubbs, a statistician for the U.S. Army’s Ballistics Research Laboratory (BRL), six years before his retirement in 1975. Apparently the Allies owe him some gratitude, given that “he was dispatched to England in 1944 as part of a team on a priority mission to sample and sort the artillery ammunition stockpiled for the invasion of France. After the team conducted thousands of test firings of the hundreds of different lots of artillery ammunition in the stockpiles, he analyzed the statistical variations in the data and was able to divide the ammunition into four large categories based on their ballistic characteristics. As a result, the firing batteries did not need to register each lot of ammunition before it was unpacked; they only needed to apply four sets of ballistic corrections to the firing tables to achieve their objectives.” After the war, he assisted the BRL in evaluating the reliability and ballistic characteristics of projectiles, rockets, and guided missiles; maybe he wasn’t a “rocket scientist,” as the saying goes, but close enough. The groundwork for the test that bears his name was laid in 1950, when he published a paper titled “Procedures for Detecting Outlying Observations in Samples” for Annals of Mathematical Statistics, which I also had to consult for this article. The 1950 paper is made publicly available by the Project Euclid website, while the one establishing the test itself is made available at California Institute of Technology’s Infrared Processing and Analysis Center, for anyone wise enough to double-check my calculations and code or to get more background.
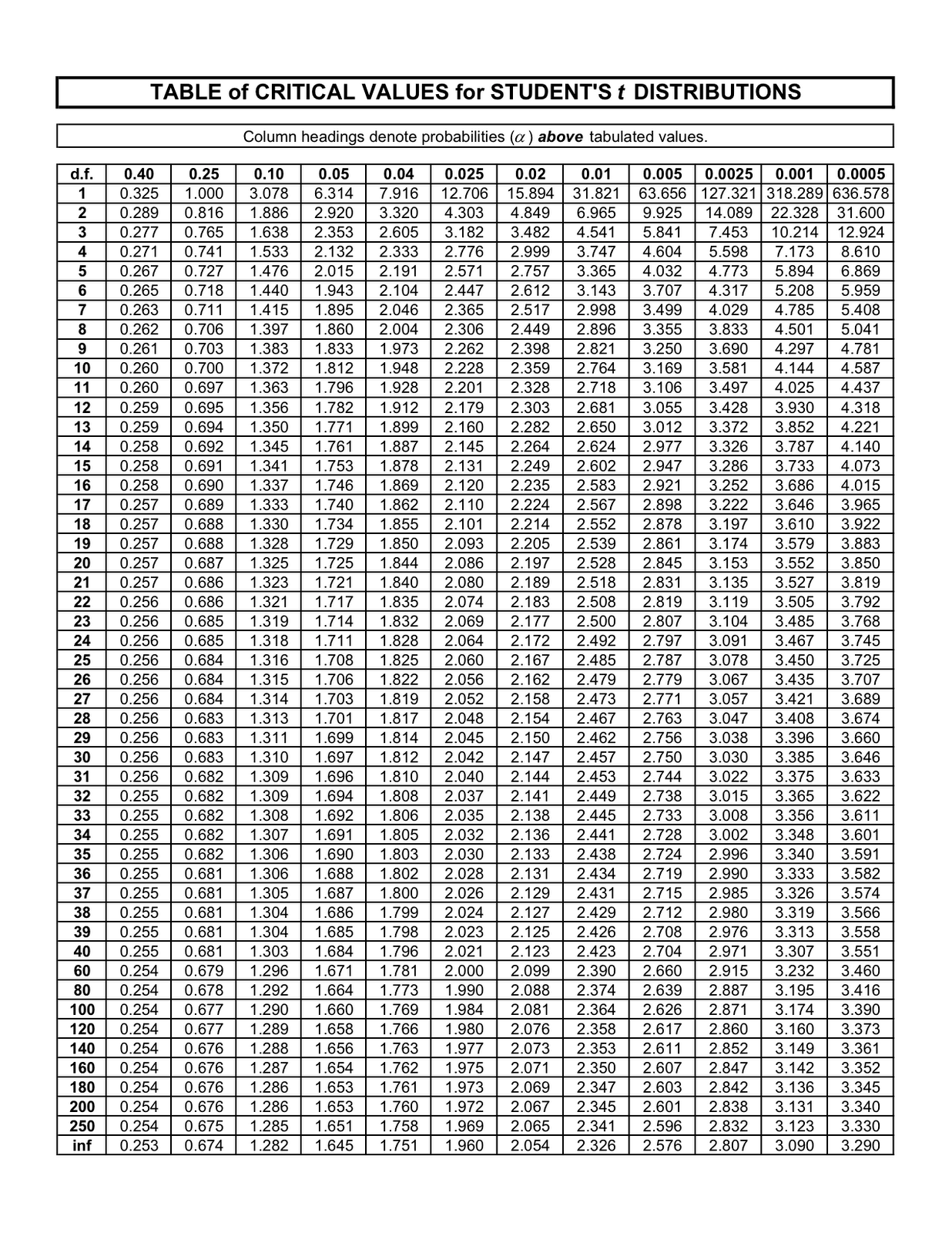
…………Calculating the test statistic from the formula at the NIST webpage is really trivial; the difficulty is in finding proper tables of the T-distribution to interpret the statistic with. The equation for the two-sided test is quite similar to the familiar Z-Score, except that we take the maximum value of the absolute deviation (i.e., the data point minus the mean) before dividing by the standard deviation. The one-sided tests for determining if a minimum or maximum value in a dataset is an outlier are only slightly different; in the former we subtract the minimum value from the mean, while in the latter we subtract the mean from the maximum. Since the code is so easy that even a caveman can do it, I decided not to complicate it by adding logic to let the user select which of the three tests to use; I simply return all three in one row, along with the critical regions for each. The formulas for calculating the critical regions at the NIST’s webpage on Grubbs’ Test are more involved, which requires the use of the function in Figure 3. This in turn calls a rather sloppy but effective function to find the correct critical values for the T-distribution, from the lookup tables defined in Figure 1. I haven’t supplied any code to populate them, but this can be easily rectified by using one of the thousands of lookup tables available on the Internet for that distribution. The tricky part was finding a table that was reasonably complete, since many sources begin skipping over deciles around 40 or 50 degrees of freedom; I populated my own from the best source I could find, the “Tables of Critical values of t for Probabilities” at the StatsToDo website. In fact, you may need to tweak the DDL and retrieval code if you use a different source, since my ranges and stopping point of 200 degrees of freedom are derived from that particular source. According to another lookup table (from a Blogspot post by a writer who I’ve been unable to identify to give proper credit) that I didn’t use because it skips some deciles, the values for 200 and 250 are nearly identical except down to the hundredth of percentage points; the next value listed there is for infinity, which varies only a few hundredths of a percentage point from 250. Unlike researchers working with small samples drawn from an unknown population, SQL Server users can often instantly call up millions of records, so using the smaller values of these lookup tables may be of limited utility for our use cases. I only recently learned how to do hypothesis testing, so my standard advice to check my code before putting it into a production environment definitely holds here. The Grubbs Statistic values match the NIST sample results though and could prove useful, by providing a measurement of “the largest absolute deviation from the sample mean in units of the sample standard deviation.”
Figure 1: DDL for the T-Distribution Lookup Tables
CREATE TABLE [Calculations].[CriticalValueRangeTable](
[ID] [smallint] IDENTITY(1,1) NOT NULL,
[OneTail] [decimal](5, 4) NULL,
[TwoTail] [decimal](5, 4) NULL,
CONSTRAINT [PK_CriticalValueRangeTable] PRIMARY KEY CLUSTERED (
[ID] ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE =
OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]) ON [PRIMARY]
CREATE TABLE [Calculations].[TDistributionTable](
[ID] [smallint] IDENTITY(1,1) NOT NULL,
[ProbabilityRange1] [decimal](7, 4) NULL,
[ProbabilityRange2] [decimal](7, 4) NULL,
[ProbabilityRange3] [decimal](7, 4) NULL,
[ProbabilityRange4] [decimal](7, 4) NULL,
[ProbabilityRange5] [decimal](7, 4) NULL,
[ProbabilityRange6] [decimal](7, 4) NULL,
[ProbabilityRange7] [decimal](7, 4) NULL,
CONSTRAINT [PK_TDistributionTable] PRIMARY KEY CLUSTERED ([ID] ASC)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]) ON [PRIMARY]
Figure 2: Function to Look Up Values in the T-Distribution Tables
CREATE FUNCTION [Calculations].[FindCriticalRegionForTDistributionFunction]
(@DegreesOfFreedom bigint, @SidedTestType bit, @ProbabilityValue decimal(5,4))
RETURNS decimal(7, 4)
AS
BEGIN
DECLARE @CriticalRegion decimal(7, 4)
— this is a little more awkward than I’d like, but hey
SELECT @CriticalRegion = CASE WHEN ProbabilityRangeColumnID = 1 THEN (SELECT ProbabilityRange1
FROM Calculations.TDistributionTable WHERE ID = (CASE WHEN @DegreesOfFreedom
>= 200 THEN 200 WHEN ID = @DegreesOfFreedom THEN @DegreesOfFreedom ELSE NULL END))
WHEN ProbabilityRangeColumnID = 2 THEN (SELECT ProbabilityRange2
FROM Calculations.TDistributionTable WHERE ID = (CASE WHEN @DegreesOfFreedom
>= 200 THEN 200 WHEN ID = @DegreesOfFreedom THEN @DegreesOfFreedom
ELSE NULL END))
WHEN ProbabilityRangeColumnID = 3 THEN (SELECT ProbabilityRange3
FROM Calculations.TDistributionTable WHERE ID = (CASE WHEN @DegreesOfFreedom
>= 200 THEN 200 WHEN ID = @DegreesOfFreedom THEN @DegreesOfFreedom ELSE NULL END))
WHEN ProbabilityRangeColumnID = 4 THEN (SELECT ProbabilityRange4
FROM Calculations.TDistributionTable WHERE ID = (CASE WHEN @DegreesOfFreedom
>= 200 THEN 200 WHEN ID = @DegreesOfFreedom THEN @DegreesOfFreedom ELSE NULL END))
WHEN ProbabilityRangeColumnID = 5 THEN (SELECT ProbabilityRange5
FROM Calculations.TDistributionTable WHERE ID = (CASE WHEN @DegreesOfFreedom
>= 200 THEN 200 WHEN ID = @DegreesOfFreedom THEN @DegreesOfFreedom ELSE NULL END))
WHEN ProbabilityRangeColumnID = 6 THEN (SELECT ProbabilityRange6
FROM Calculations.TDistributionTable WHERE ID = (CASE WHEN @DegreesOfFreedom >= 200 THEN 200 WHEN ID = @DegreesOfFreedom THEN @DegreesOfFreedom ELSE NULL END))
WHEN ProbabilityRangeColumnID = 7 THEN (SELECT ProbabilityRange7
FROM Calculations.TDistributionTable WHERE ID = (CASE WHEN @DegreesOfFreedom >= 200 THEN
200 WHEN ID = @DegreesOfFreedom THEN @DegreesOfFreedom ELSE NULL END))
ELSE NULL END
FROM (SELECT TOP 1 ID AS ProbabilityRangeColumnID
FROM (SELECT ID, ValueRange, ABS(ValueRange – @ProbabilityValue) AS RangeDifference, Lead(ValueRange, 1, 0) OVER (ORDER BY ValueRange) AS Lead
FROM (SELECT ID, ‘ValueRange’ = CASE WHEN @SidedTestType = 0 THEN OneTail
WHEN @SidedTestType = 1 THEN TwoTail
ELSE NULL END
FROM [Calculations].[CriticalValueRangeTable] ) AS T1) AS T2
ORDER BY RangeDifference ASC) AS T3
RETURN @CriticalRegion
END
Figure 3: Grubbs Hypothesis Testing Function
CREATE FUNCTION [Calculations].[GrubbsHypothesisTestSP](
@DegreesofFreedom bigint, @TestType bit = 0, @SignificanceLevel decimal(38,35))
RETURNS decimal(38,32)
AS
BEGIN
DECLARE @CriticalValue decimal(38,32), — *** look this up in a table by the SignificanceLevel I’ve already recalculated according to the formulas, and also the Degrees of Freedom – 2
@ReturnValue decimal(38,32)
SELECT @CriticalValue = [Calculations].[FindCriticalRegionForTDistributionFunction] (@DegreesofFreedom, @TestType, @SignificanceLevel)
SELECT @ReturnValue = Power(Power(@CriticalValue, 2) / (@DegreesOfFreedom – 2
+ Power(@CriticalValue, 2)), 0.5) * ((@DegreesOfFreedom –1) / Power(@DegreesOfFreedom,
0.5))
RETURN @ReturnValue
END
Figure 4: Code for the the Grubbs Test Procedure
CREATE PROCEDURE [Calculations].[GrubbsTestSP]
@DatabaseName as nvarchar(128) = NULL, @SchemaName as nvarchar(128), @TableName as nvarchar(128),@ColumnName AS nvarchar(128), @DecimalPrecision AS nvarchar(50), @Alpha decimal(38,35) = 0.05
AS
DECLARE @SchemaAndTableName nvarchar(400), @SQLString nvarchar(max)
SET @DatabaseName = @DatabaseName + ‘.’
SET @SchemaAndTableName = ISNull(@DatabaseName, ”) + @SchemaName + ‘.’ + @TableName –I’ll change this value one time, mainly for legibility purposes
SET @SQLString = ‘DECLARE @Mean decimal(‘ + @DecimalPrecision + ‘),
@StDev decimal(‘ + @DecimalPrecision + ‘),
@Min decimal(‘ + @DecimalPrecision + ‘),
@Max decimal(‘ + @DecimalPrecision + ‘),
@GrubbsVersion1 decimal(‘ + @DecimalPrecision + ‘),
@GrubbsVersion2 decimal(‘ + @DecimalPrecision + ‘),
@GrubbsVersion3 decimal(‘ + @DecimalPrecision + ‘),
@DegreesofFreedom bigint,
@SignificanceLevel decimal(‘ + @DecimalPrecision + ‘),
@SignificanceLevelOneSided decimal(‘ + @DecimalPrecision + ‘)
SELECT @DegreesofFreedom=Count(‘ + @ColumnName + ‘), @Mean = Avg(CAST(‘ + @ColumnName + ‘ AS Decimal(‘ + @DecimalPrecision + ‘))), @StDev = StDev(CAST(‘ + @ColumnName + ‘ AS Decimal(‘ + @DecimalPrecision + ‘))), @Min = Min(‘ + @ColumnName + ‘), @Max = Max(‘ + @ColumnName + ‘) FROM ‘ + @SchemaAndTableName + ‘ WHERE ‘ + @ColumnName + ‘ IS NOT NULL
— the sample exercise at the NIST webpage uses a straight value of @SignificanceLevel = @Alpha, rather than the two calculations for two- and one-sided tests that are recommended elsewhere on the directions; hence Ive commented them out for now
–-SET @SignificanceLevel = ‘ + CAST(@Alpha AS nvarchar(50)) + ‘ / (2 * @DegreesofFreedom)
–SET @SignificanceLevelOneSided = ‘ + CAST(@Alpha AS nvarchar(50)) + ‘ / (@DegreesofFreedom)
SET @SignificanceLevel = ‘ +
CAST(@Alpha AS nvarchar(50)) + ‘
SET @SignificanceLevelOneSided = ‘ + CAST(@Alpha AS nvarchar(50)) + ‘
SELECT @GrubbsVersion1 = Max(‘ + @ColumnName + ‘ – @Mean) / @StDev, @GrubbsVersion2 = ((@Mean – @Min) / @StDev),
@GrubbsVersion3 = ((@Max – @Mean) / @StDev)
FROM ‘ + @SchemaAndTableName +
‘WHERE ‘ + @ColumnName + ‘ IS NOT NULL
SELECT @GrubbsVersion1 AS GrubbsTwoSided, CAST([Calculations].[GrubbsHypothesisTestSP] (@DegreesOfFreedom, 1, @SignificanceLevel) AS decimal(‘ + @DecimalPrecision + ‘)) AS
CriticalRegionForGrubbsTwoSided,
@GrubbsVersion2 AS GrubbsLowerOneSided, @GrubbsVersion3 AS GrubbsUpperOnesided, CAST([Calculations].[GrubbsHypothesisTestSP] (@DegreesOfFreedom, 0, @SignificanceLevelOneSided) AS decimal(‘ + @DecimalPrecision + ‘)) AS CriticalRegionForGrubbsUpperOneSided‘
–SELECT @SQLString — uncomment this to debug string errors
EXEC (@SQLString)
…………Thankfully, we will be able to reuse the mass of T-SQL in the first three figures in next week’s tutorial, which also requires looking up T-distribution values. The code in Figure 4 will look familiar if you’ve been following this mistutorial series. As always, you’ll have to add the brackets and program in the logic yourself if you allow spaces in your object names; you may also need to add SQL injection and other security code. Also, keep in mind that I’m still using a Calculations schema for these sample routines, so you may need to create one in your database or change the name as needed. The first three parameters allow you to run the procedure against any column in any database for which you have the requisite permissions and access. The @DecimalPrecision also allows you to manually set the precision and scale for the internal calculations of the procedure, in order to avoid arithmetic overflows. There are some slight differences between the parameters of this procedure and those discussed in the last few articles though, such as the fact that the usual @OrderByCode and @PrimaryKeyName are not needed here. The @Alpha parameter allows you to set the significance level of the test to any value you please (including incorrect ones, since I haven’t added any validation code) like the default of 0.05, which corresponds to a 95 percent confidence level. Oddly, Grubbs wrote in the 1969 paper that the confidence levels ought to be at least 99 percent for use with this test, but still used the standard 95 percent in his own example. Similarly, the NIST webpage says to use @Alpha divided by the degrees of freedom for a one-sided test and divided by twice the degrees of freedom for a two-sided test, yet uses a plain significance value of @Alpha = 0.05 in its sample data. Hence the commenting out of the code that would change the @SignificanceLevel to the alternate values. When run against the sample exercise on the NIST page, my code is accurate within about a hundredth of a percentage point, as long as this adjustment is made.
Figure 5: Results for the Grubbs Test Procedure
EXEC Calculations.GrubbsTestSP
@DatabaseName =N’DataMiningProjects’,
@SchemaName= N’Health’,
@TableName = N’DuchennesTable’,
@ColumnName= N’PyruvateKinase’,
@DecimalPrecision= N’12,7′,
@Alpha = 0.05

…………Executing a query like the one above against the Duchennes dataset we’ll be working with in this tutorial series produced the five columns above. The first, third and fourth columns represent the Grubbs Statistics for the two-sided, minimum and maximum tests respectively, while the Critical Regions are derived from the aforementioned code in Figures 1 through 3. The Grubbs Statistics are far beyond the critical regions, so yes, the maximum values in the dataset are beyond the thresholds and thus can be defined as “outliers.” Keep in mind that after testing the procedure against several different columns in different datasets, I’ve only seen slight differences between the two-sided result and the upper one-sided; due to lack of appropriate samples to work through, I cannot say whether or not that can be expected or is an error on my part. The PyruvateKinase column refers to an enzyme that is apparently involved in the devastating Duchennes form of muscular dystrophy, which is the subject of a tiny nine-kilobyte sample dataset made publicly available by Vanderbilt University’s Department of Biostatistics. In the last couple of blog posts I used the first float column of the Higgs Boson Dataset that the University of California at Irvine’s Machine Learning Repository has made available online, which occupies nearly 6 gigabytes of space in the DataMiningProjects database I’ve created to encompass all of the practice datasets I’ll be using in tutorial series to come. Traversing that much space in index scans and seeks turned out to be somewhat costly for the two versions of Z-Scores that I coded in the last two posts, but I haven’t bothered to post Client Statistics from SQL Server Management Studio (SSMS) because the Grubbs’ Test procedure takes only a matter of seconds, even for the massive float columns of the Physics.HiggsBosonTable.
…………The procedure may perform well compared to other outlier detection methods, but its usefulness is limited. I have yet to test it against a table that didn’t turn out to have outliers – which is likely to be the case for most of the large tables that DBAs might run the procedure on. Grubbs’ Test is more useful for the kind of small tables used in hypothesis testing, rather than exploratory data mining and data quality analyses, which are far more common uses cases in the SQL Server user community. Statistical testing of this kind is also prone to several real dangers I’ve touched on in the last few articles and others that I have yet to address. The confidence levels commonly associated with them are pretty much drawn out of thin air; you’ll see 95 percent used most of the time, but only because it was an arbitrary de facto standard long before the UNIVAC. There really isn’t a good justification for it, except for the fact that it has been used for so long. Secondly, probabilities are not guarantees; there is a finite chance that random fluctuations alone could produce a dataset that consisted of nothing but outliers, using any definition and detection method. Worst of all, Grubbs’ Test requires a Gaussian (i.e.”normal”) distribution, i.e. the bell curve. Without goodness-of-fit tests that clearly demonstrate that the data ought to fit the normal distribution, such tests are useless – or worse, deceptive. As Grubbs himself puts it mildly, “Until such time as criteria not sensitive to the normality assumption are developed, the experimenter is cautioned against interpreting the probabilities too literally when normality of the data is not assured.” I don’t yet know how to apply some of the best goodness-of-fit tests (mainly because I’m still having trouble wrapping my head around some of the intricacies of cumulative distribution functions) but that won’t stop me from harping on this point repeatedly: the extent to which statistics are bandied about in many academic disciplines without proper testing today is simply alarming. The one place we can least afford to see them is in medical research, where they become a matter of life and death, but at least half of all studies published today contain at least one statistical error. The most common error appears to be the lack of goodness-of-fit testing; researchers in many fields seem to be in the habit of routinely applying tests that depend on a Gaussian distribution with reckless disregard for their validity. It’s not surprising that this occurs, given that there are so few statistical tests that can be used with the scores of other distributions that data might follow. If researchers everywhere were held to a proper standard of evidence, they might not be able to back up claims for a favorite project or experimental medicine with any statistics at all.
…………This leads straight back to the logical and moral issues that I’ve tried to reiterate throughout this series: there are an awful lot of shenanigans that go on with “lies, damned lies and statistics,” as the old saying goes. Grubbs’ Test is no more vulnerable to misuse than any other measure based on the normal distribution, all of which can be invalid, misleading or worse when the data is not naturally Gaussian. It is sometimes, however, applied recursively by simply deleting outliers until some stopping criteria is reached, which raises the grim possibility of improper handling of unfavorable data points. In some situations, an iterative Grubbs Test is vulnerable to false negatives, in which actual outliers are not detected, or false positives, in which haphazard definitions of stopping criteria lead to the deletion of good data. That brings us back full circle to the confluence of subjective definitions, “moving the goalposts” and inadequate analysis of the causes of aberrance which I discussed at length in the last article. Thankfully, the Generalized Extreme Studentized Deviate Test (GESD) ameliorates some of the standard problems associated with the sequential application of Grubbs’ Test by making a few adjustments; the NIST recommends that either the GESD or the Tietjen-Moore test be applied when looking for more than one outlier, which is almost always going to be the case in a SQL Server database. The math and code for both are also relatively simple. Unfortunately, they are both dependent on a Gaussian distribution, which means they also require goodness-of-fit tests that are often dispensed with in an irresponsible manner. The same limitation applies to Dixon’s Q-Test, which is simple to code, as well as to Chauvenet’s Criterion, which is not. It may also be true of Peirce’s Criterion, which will also be featured later in this series. Interquartile Range is a much more easily coded method of outlier detection which also may be less dependent on the normal distribution. Later in the series, I’ll give a quick recap of the Clustering algorithm in SQL Server Data Mining (SSDM) and supply some eye candy that is much easier on the brain than these fancy equations in Visual Outlier Detection with SQL Server Reporting Services. Towards the end I’ll delve into more difficult methods like Cook’s Distance and the Modified Thompson Tau Test, then Mahalanobis Distance. Many of these more sophisticated methods are of course more difficult to code than GESD, Tietjen-Moore and Dixon’s Q-Test, but they may also be more applicable to distributions besides the bell curve.

![]()

{kind=link}