

 T-SQL Tuesday is a monthly event where SQL Server bloggers write a post based on a subject chosen by the month’s host. You can find a list of all past topics at tsqltuesday.com. This month, it’s Grant Fritchey’s (t|b) turn with his topic Databases and DevOps.
T-SQL Tuesday is a monthly event where SQL Server bloggers write a post based on a subject chosen by the month’s host. You can find a list of all past topics at tsqltuesday.com. This month, it’s Grant Fritchey’s (t|b) turn with his topic Databases and DevOps.
Automation is a key aspect of the DevOps movement. The automation of software deployment has a new weapon in the form of containers. It’s still early days for containers in the Windows world, but with SQL Server 2017 being cross platform, the potential for containerisation of SQL Server is growing.
If we can’t automate the deployment of complicated production infrastructure with these tools they become restricted to test environments. So in this post, I’ll demo a scripted, highly available and containerised instance of SQL Server on Linux using Kubernetes (K8s).
Kubernetes
Kubernetes is to containers what System Center’s Virtual Machine Manager is to VMs. Read more here and here.
SQL Server High Availability on Linux is difficult, just look at the instructions for setting up a failover clustered instance on REL. Kubernetes offers an alternative method for HA.
I’ll be using Minikube (so you can follow along at home), which is the single node version of Kubernetes that is for local development. Install instructions are here or just use Chocolatey to pull the latest version.
choco install minikube
First, create an external virtual switch named external
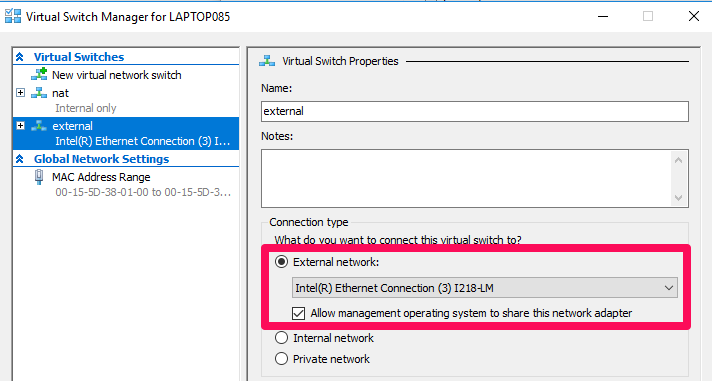
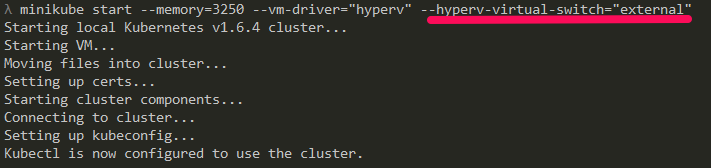
The following command will create a Hyper-V VM for us to run our Linux containers on.
minikube start --memory=3250 --vm-driver="hyperv" --hyperv-virtual-switch="external"
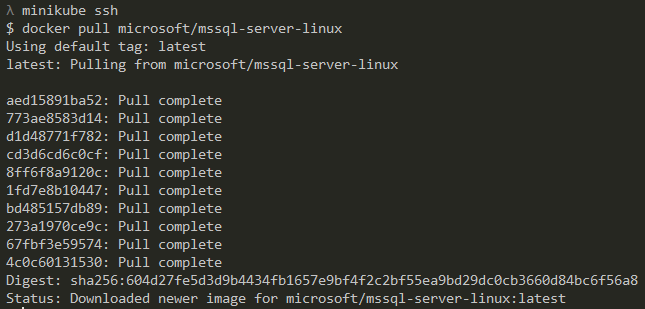
Our VM has the Docker engine running, but it doesn’t have any images yet. We can SSH into the VM and pull the latest SQL Server image with:
minikube ssh docker pull microsoft/mssql-server-linux
Type Exit to quit the SSH session.
Now we can tell Kubernetes to create a deployment with the SQL Server image.
From the Kubernetes docs:
A Kubernetes Pod is a group of one or more Containers, tied together for the purposes of administration and networking. A Kubernetes Deployment checks on the health of your Pod and restarts the Pod’s Container(s) if it terminates.
In reality, it’s rare for there to be more than one container in a pod.
kubectl run mssql --image=microsoft/mssql-server-linux --port=1433 --env ACCEPT_EULA=Y --env SA_PASSWORD=P455word1
![]()
We can view the new pod with:
kubectl get pods

The Kubernetes deployment, that consists of one pod running our SQL Server container, will act as the replacement for our Windows cluster. If the pod fails, Kubernetes will restart it (this would be on another physical node if the hardware failed).
Creating a Service
More from the Kubernetes docs:
By default, the Pod is only accessible by its internal IP address within the Kubernetes cluster. To make the Container accessible from outside the Kubernetes virtual network, you have to expose the Pod as a Kubernetes Service.
kubectl expose deployment mssql --type=LoadBalancer
![]()
Now it’s exposed, we need to find the IP and port before we can connect.
minikube service mssql --url
![]()
We can now connect to the SQL Server instance in our pod. Remember to use a comma in SSMS when stipulating a port.
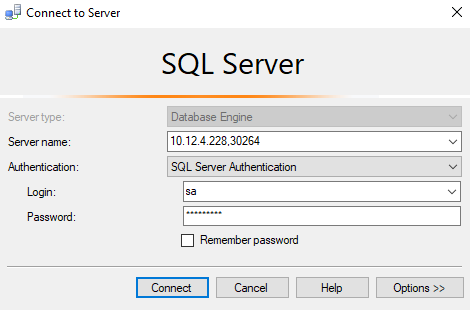
Run the command below to open the Kubernetes dashboard. Here we can monitor and, to a lesser extent, manage our pods.
minikube dashboard
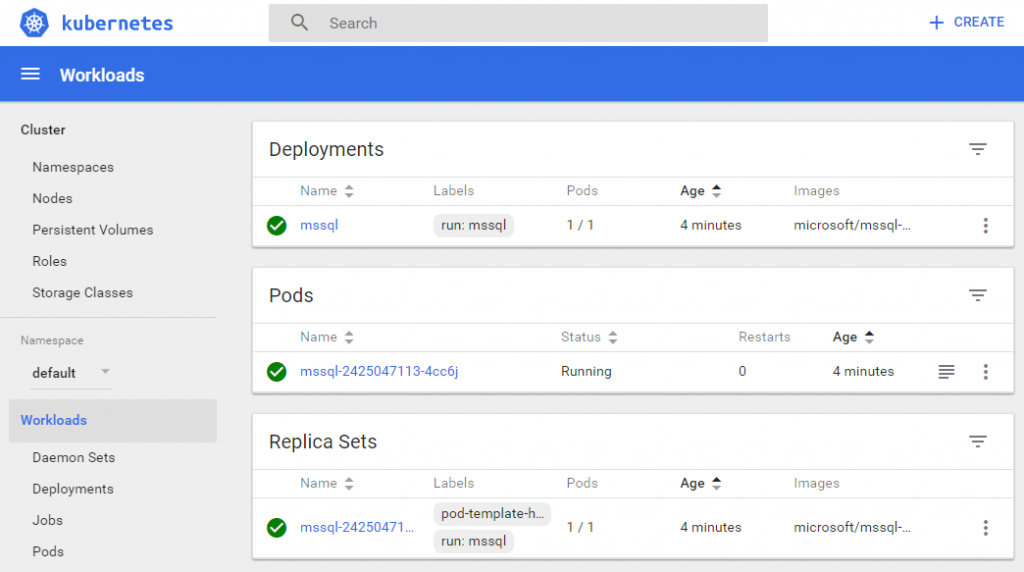
Let’s put Kubernetes to the test by killing our pod. SSH back into the VM and use docker ps get the container ID. Stop the mssql container with the first 4 characters of the ID. There is no need to type the full ID.
minikube ssh docker ps docker stop YourContainerId
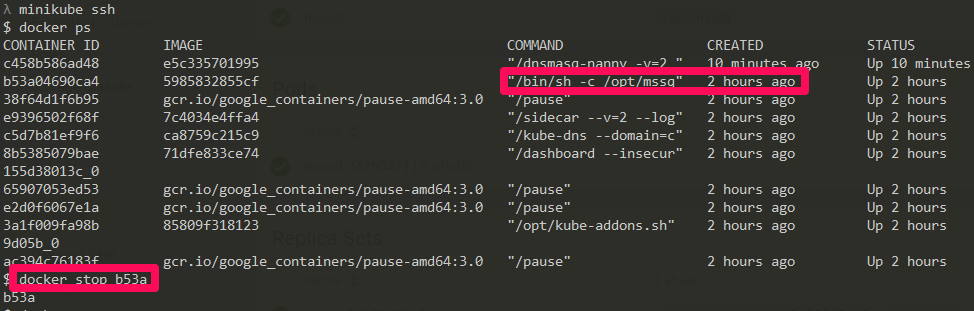
If you can catch the dashboard in time, you’ll see something like this:
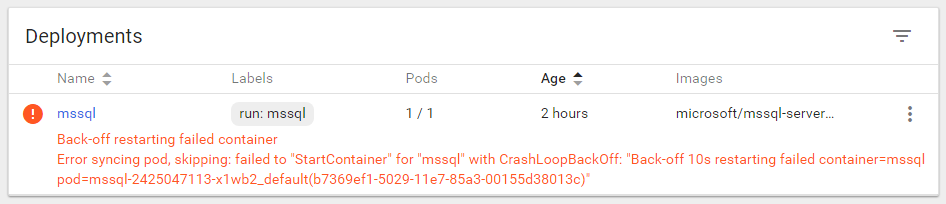
On my laptop, it took Kubernetes roughly 50 seconds to bring up another pod.
Conclusion
With recovery times like 50 seconds, on a default install, Kubernetes can compete with a Fail-over Clustered Instance on Windows. It’s also very easy to add more nodes to a Kubernetes cluster.
So if it’s easy, why not throw it into production when SQL Server 2017 hits RTM? Well here are a couple of reasons:
- Licensing might be “tricky”
- You may think containers are cool, but can your team (or anyone you hire) use them in production?
- SQL Server on Linux is still missing features like AD authentication
- Containers on Windows are in their infancy
- It could all be hype and gone tomorrow
I believe that containers, and the tools to manage them, are more than just hype. They enable Infrastructure as Code which solves one of the biggest issues in IT, the provisioning of production like test environments. It may not be Docker or Kubernetes that we are talking about in the years to come, but containers are here to stay.
This post didn’t cover clustered storage, which is crucial for a cluster, but I’ll be blogging about that very soon.
If you would like to be the host of a T-SQL2sday event, then read these rules and contact Adam Machanic.
The post Orchestrating SQL Server with Kubernetes appeared first on The Database Avenger.
