

One of the most common mistakes I see made when creating tables (and I’ve been guilty of this myself too many times) is allowing SQL Server to cluster the table for them. This is usually the result of SQL Server’s default behavior when creating a primary key: if there is no clustering index on the table, and you don’t specify that the PK is nonclustered, SQL Server will cluster the table on the PK.
For stand-alone tables, this isn’t an issue, and letting the PK be the clustering key as well is usually just fine, especially when it’s a surrogate key in the form of a sequence or identity. It’s narrow, ever-increasing, and unique. No problem here.
The problem arises when the table has subordinate or child tables in which its PK appears as a foreign key, but the subordinate table has its own surrogate key defined as the PK, and since there was no clustered index when we did that, the subordinate’s PK becomes the clustering key as well – and now we are on the road to trouble.
Let’s consider the old standby: SalesOrderHeader and SalesOrderDetail. We create our SalesOrderHeader table with SalesOrderID as an identity, and specify that it is our PK for the table. Then we create the SalesOrderDetail table, specify SalesOrderDetailID as the PK, and add a FK constraint back to SalesOrderHeader. As a final, thoughtful gesture, we create a nonclustered index on SalesOrderDetail.SalesOrderID, figuring that will help us out with joins.
Then we query our SalesOrderHeader table, looking for sales from the most prolific salesperson (I’ve modified the AdventureWorks2012 database for my own nefarious purposes here):
(7825 row(s) affected) Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'SalesOrderDetail'. Scan count 1, logical reads 1246, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'SalesOrderHeader'. Scan count 1, logical reads 689, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
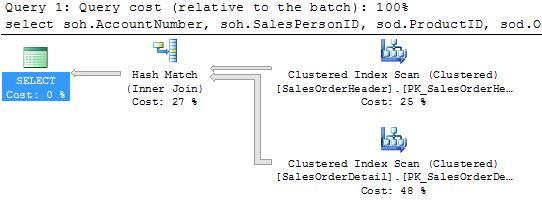
We returned 7825 rows, with two clustered index scans and a Hash Match. Note that the SalesOrderDetail scan was responsible for 48% of the cost here. There’s a nonclustered index on SalesOrderHeader.SalesPersonID, but #277 has entered 473 sales – just over 1.5% of the total – and SQL Server figures it’s cheaper to do the scan. However, there’s no sign of our index on SalesOrderDetail.SalesOrderID.
This is not a very efficient query, and we can only imagine that it will get worse as sales accumulate. What happens when our sales count reaches 100,000? A million? Fifty million? At some point the optimizer will “helpfully” recommend a covering index, which will help a bit, except that now there’s another index to be inserted into, or deleted from, or updated. Assuming 277 continues to rack up sales at 1.5% of the total, there’s no good likely to come from this. Perhaps, we muse, an indexed view will help? A filtered index? Filtered statistics?
All these things may help – for a little while. Sooner or later, as data volume increases, we’ll be back to clustered index scans and Hash Matches and twiddling our thumbs while the query runs, all because we let SQL Server decide what our clustering key was going to be.
But there’s not much data now, and we can still fix things with relatively little effort. So we drop the nonclustered indexes on SalesOrderDetail, drop the PK on SalesOrderDetailID, create a unique clustered index on SalesOrderID and SalesOrderDetailID (in that order), then recreate the PK on SalesOrderDetailID, but specify nonclustered, and then revisit our salesperson query again:
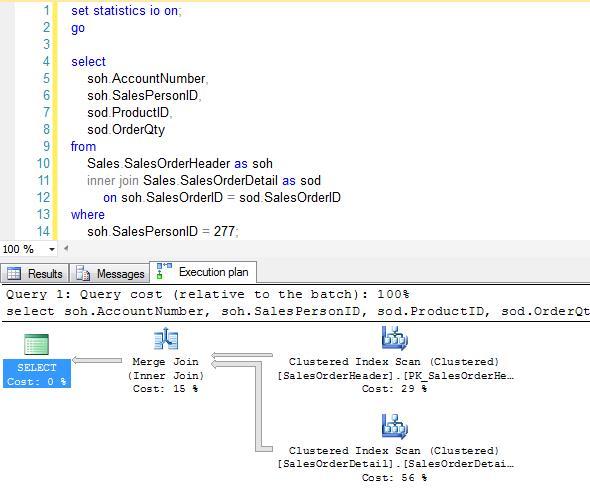
(7825 row(s) affected) Table 'SalesOrderDetail'. Scan count 1, logical reads 1180, physical reads 3, read-ahead reads 1277, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'SalesOrderHeader'. Scan count 1, logical reads 689, physical reads 2, read-ahead reads 685, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (1 row(s) affected)
Doesn’t seem like much has changed, superficially: there’s still two clustered index scans. But we’ve got a Merge Join now instead of a Hash Match, and the IO statistics are different: no work tables (since no Hash Match), and the logical reads for SalesOrderDetail are lower. And while there’s not much difference in execution time at these low data volumes, those work tables begin to add up as we increase the volume. If we decide to join all the rows from both tables (no predicates), the advantage of the Merge Join starts showing up in the execution times.
Even single predicate queries based on the SalesOrderID show an improvement in plan, from a SalesOrderHeader seek and SalesOrderDetail key lookup under the old clustering, to a seek and seek under the new:
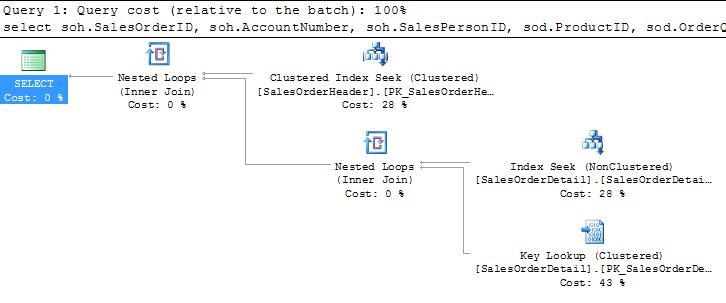
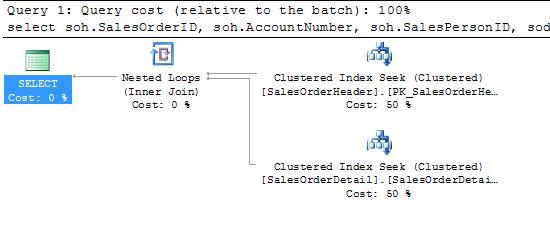
Key lookups can get expensive in a hurry: and given that the optimizer will consider a key lookup if the estimated return is less than a half a percent of the total rows, it’s easy to see how queries like this on very large tables could lead to trouble.
In the AdventureWorks2012 database, Microsoft creates a PK on SalesOrderID and SalesOrderDetailID, and allows the PK to default to the clustering key. I’m not a fan of this idea myself: to me, primary key means “principal means of uniquely identifying a tuple in a relation”, and compound keys for that purpose simply don’t feel right to me. This isn’t to say they’re wrong: if Microsoft is doing it, there has to be virtue in it: just that it’s another one of those points on which DBA’s will agree to disagree.
Whatever design path you take, never forget that when it comes to parent-child tables, it’s all about the joins. Creating your clustering indexes in such a way as to enhance efficient joins, with minimal lookups and reads, will help insure your design scales well as your data grows.
