

By Steve Bolton
…………In the first installment of this amateur self-tutorial series on applying fuzzy set theory to SQL Server databases, I discussed how neatly it dovetails with Behavior-Driven Development (BDD) principles and user stories. This is another compelling reason to take notice of fuzzy sets, beyond the advantages of using a set-based language like T-SQL to implement them, which will become obvious as this series progresses. There aren’t any taxing mental gymnastics involved in flagging imprecision in natural language statements like “hot,” “cloudy” or “wide,” which is strikingly similar to the way user stories are handled in BDD. What fuzzy sets bring to the table is the ability to handle imprecise data that resides in the no-man’s land between ordinal and continuous Content types. In addition to flagging imprecision in natural language and domain knowledge that is difficult to pin down, it may be helpful to look for attributes which represent categories that are ranked in some way (which sets them apart from nominal data, which is not ordered on any scale) but which it would be beneficial to express on a continuous numerical scale, even at the cost of inexactness. Thankfully, mathematicians have already hashed out a whole framework for modeling this notoriously tricky class of data, even though it is as underused as the SQL Server Data Mining (SSDM) components I tried to publicize in a previous mistutorial series. It is also fortunate that we already have an ideal tool to implement it with in T-SQL, which can already handle most of the mathematical formulas devised over the last few decades. As I’ll demonstrate in this article, it only takes a few minutes to implement simple membership functions that grade records based on how much they belong to a particular set. It is only when we begin combining different types of imprecision together and assigning more nuanced interpretations to the grading systems that complexity quickly arises and the math becomes challenging. Although I’m still learning the topic as I go – I find it is much easier to absorb this kind of material by writing about it – I hope to reduce the challenge involved by taking a stab at explaining it, which will at a minimum at least help readers avoid repeating my inevitable mistakes.
…………The first challenge to overcome is intimidation, because the underlying concepts don’t even require a college education to grasp; in fact, some DBAs have probably already worked with forerunners of fuzzy sets unwittingly, on occasions where they’ve added columns that rate a row’s inclusion in a particular set. It doesn’t take much mental juggling to start thinking explicitly about such attributes as measures of membership in a particular set. Perhaps the simplest forms of membership functions are single columns filled with data that has been assigned that kind of meaning, which can even be derived from such sources as subjective grades assigned by end users in exactly the same manner as movie or restaurant ratings. The data can even be permanently static. At the next level of complexity, we could of course store such data in the form of computed columns, regardless of whether it is read-only or not.
…………A couple of really simple restrictions are needed to bring this kind of data into line with fuzzy set theory though. First, since the whole object is to treat ordinal data as if it were continuous, we’d normally use T-SQL data types like float, numeric and decimal – which are the closest we can get, considering that our finite computers can’t truly handle infinitesimal scales. Furthermore, it is probably wise to stick with the convention of using a scale between 0 and 1, since this enables us to integrate it seamlessly with evidence theory, stochastics, decision theory, control theory and neural net weights, all of which are also typically bounded in the same range or quite similar ones; some of the theoretical resources I consulted mentioned in an offhand way that it is possible to use other scales, but I haven’t seen a single instance of it yet in the literature. Ordinal categories are often modeled in SQL Server in text data types like nvarchar, tinyint codes or some type of foreign key, which might have to be retained alongside the membership function storage column; in other instances, our membership function may be scoring on the basis of several attributes in a table or view, or perhaps all of them. Of course, in many use cases we won’t need to store the membership function value at all, so it will have to be calculated on the fly. If we’re simply storing a subjective rating or whatever, we might only need some sort of interface to allow end users to enter their own numbers (on a continuous scale of 0 to 1), in which case there is no need for a membership function per se. If a table or view participates in different types of fuzzy sets, it may be necessary to add more of these membership columns for each of them, unless you want to calculate the values as you go. Simply apply the usual rules of data modeling and principles of performance maximization to determine the strategies that fit your use cases best.
Selecting Membership Functions
That is all kid stuff for most DBAs. The challenges begin when we try to identify which membership function would be ideal for the use cases at hand. Since the questions being asked of the data vary from one problem to the next, I cannot possibly answer that. I suppose that you could say the general rule of thumb with membership functions is that the sky’s the limit, as long as we stay at an altitude between 0 and 1. Later in this series I’ll demonstrate how to use particular classes of functions called T-norms and T-conorms, since various mathematical theorems demonstrate that they’re ideal for implementing unions and intersections, but even in these cases, there are so many available to us that the difficulty consists chiefly in selecting an appropriate match to the problem you’re trying to solve. There might be more detailed guidelines available from more recent sources, but my favorite reference for the math formulas, George J. Klir and Bo Yuan’s classic Fuzzy sets and Fuzzy Logic: Theory and Applications, provides some suggestions. For example, membership values can be derived from sample data through LaGrange interpolation and two methods I have used before, least-squares curve fitting and neural networks.[1] They also discuss how to aggregate the opinions of multiple experts using both direct and indirect methods of collection, in order to ascertain the meaning of fuzzy language terms. The specifics they provide get kind of involved, but it is once again not at all difficult to implement the premises in a basic way; a development team could, for example, reach a definition of the inherently fuzzy term “performance” by scoring their opinions, then weighting them by the authority of their positions.[2] The trick is to pick a mathematical operation that pools them altogether into a single value that stays on a scale of 0 to 1, while still capturing the meaning in a way that is relevant to the problem at hand.
…………Klir and Yuan refer to this as an application of the newborn field of “knowledge engineering,”[3] which has obvious connections to expert systems. Since fuzzy set theory is still a wide-open field there’s a lot of latitude for inventing your own functions; there might be an optimal function that matches the problem at hand, but no one may have discovered it yet. In situations like these, my first choice would be neural nets, since I saw spectacular evidence long ago of how they can be ideal for modeling unknown functions (which pretty much sparked my interest in data mining). Before trying one of these advanced approaches, however, it might be wise to think hard about what mathematical properties you require of your outputs and then consult a calculus book or other math reference to try to find a matching function. While trying to teach myself calculus all over again recently, I was reintroduced to the whole smorgasbord of properties that distinguish mathematical functions from each other, like differentiability, integrability, monotonicity, analycity, concavity, subadditity, superadditivity, discontinuity, splines, super- and subidempotence and the like. You’ll encounter these terms on every other page in fuzzy set math references, which can be differentiated (pun intended?) into broad categories like function magnitude, result, shape and mapping properties. One thing I can help with is to caution that it’s often difficult or even impossible to implement ones (like the popular gamma function) which require calculations of permutations or combinations. It doesn’t matter whether you’re talking about T-SQL, Visual Basic, C# or some computer language implemented outside of the Microsoft ecosystem: it only takes very small input values before you reach the boundaries of the highest data types. This renders certain otherwise useful data mining and statistical algorithms essentially useless in the era of Big Data. An exclamation point in a math formula ought to elicit a groan, because the highest value you might be able to plug into a factorial function in SQL Server is about 170.
A Trivial Example with Two Membership Functions
I’ll provide an example here of moderate difficulty, in between the two extremes of advanced techniques like least squares (or God forbid, the gamma function and its relatives) on the one hand and cheesy screenshots of an ordinary table that just happens to have a float column scored between 0 and 1 on the other. As we’ll see in the next few tutorials on fuzzy complements, unions, intersections and the like, when calculating set memberships on the fly we usually end up using a lot of CASE, BETWEEN and MIN/MAX statements in T-SQL, but that won’t be the case in the example below because the values are derived from a stored procedure and stored in two temporary tables. To demonstrate how seamlessly fuzzy set techniques can be integrated with standard outlier detection techniques, I’ll recycle the code from my old tutorial Outlier Detection with SQL Server, part 2.1: Z-Scores and use it as my membership function.
…………There’s a lot of code in Figure 1, but it’s really easy to follow, since all we’re doing is running the Z-Scores procedure on a dataset on the Duchennes form of muscular dystrophy I downloaded from Vanderbilt University’s Department of Biostatistics a couple of tutorial series ago, which now occupies about 9 kilobytes of space in a sham DataMiningProjects database. There’s probably a more efficient way of going about this, but the results are stored in a table variable and the @RescalingMax, @RescalingMin and @RescalingRange variables and the ReversedZScore column are then used to normalize the Z-Score on a range of 0 to 1 (the GroupRank column was needed for the stored procedure definition in the original Z-Scores tutorial, but can be ignored in this context). To illustrate how we can combine fuzzy set approaches together in myriad combinations, I added an identical table that holds Z-Scores for a second column from the same dataset, which is rescaled in exactly the same way. In the subquery SELECT I merely multiply the two membership values together to derive a CombinedMembershipScore. What this essentially does is give us a novel means of multidimensional outlier detection.
Figure 1: Using Z-Scores for Membership Functions
DECLARE @RescalingMax decimal(38,6), @RescalingMin decimal(38,6), @RescalingRange decimal(38,6)
DECLARE @ZScoreTable1 table
(ID bigint IDENTITY (1,1),
PrimaryKey sql_variant,
Value decimal(38,6),
ZScore decimal(38,6),
ReversedZScore as CAST(1 as decimal(38,6)) – ABS(ZScore),
MembershipScore decimal(38,6),
GroupRank bigint
)
DECLARE @ZScoreTable2 table
(ID bigint IDENTITY (1,1),
PrimaryKey sql_variant,
Value decimal(38,6),
ZScore decimal(38,6),
ReversedZScore as
CAST(1 as decimal(38,6)) – ABS(ZScore),
MembershipScore decimal(38,6),
GroupRank bigint
)
INSERT INTO @ZScoreTable1
(PrimaryKey, Value, ZScore, GroupRank)
EXEC Calculations.ZScoreSP
@DatabaseName = N’DataMiningProjects‘,
@SchemaName = N’Health‘,
@TableName = N’DuchennesTable‘,
@ColumnName = N’CreatineKinase‘,
@PrimaryKeyName = N’ID’,
@DecimalPrecision = ’38,32′,
@OrderByCode = 8
INSERT INTO @ZScoreTable2
(PrimaryKey, Value, ZScore, GroupRank)
EXEC Calculations.ZScoreSP
@DatabaseName = N’DataMiningProjects‘,
@SchemaName = N’Health‘,
@TableName = N’DuchennesTable‘,
@ColumnName = N’LactateDehydrogenase‘,
@PrimaryKeyName = N’ID’,
@DecimalPrecision = ’38,32′,
@OrderByCode = 8
— RESCALING FOR COLUMN 1
SELECT @RescalingMax = Max(ReversedZScore), @RescalingMin= Min(ReversedZScore) FROM @ZScoreTable1
SELECT @RescalingRange = @RescalingMax – @RescalingMin
UPDATE @ZScoreTable1
SET MembershipScore = (ReversedZScore – @RescalingMin) / @RescalingRange
— RESCALING FOR COLUMN 2
SELECT @RescalingMax = Max(ReversedZScore), @RescalingMin= Min(ReversedZScore) FROM @ZScoreTable2
SELECT @RescalingRange = @RescalingMax – @RescalingMin
UPDATE @ZScoreTable2
SET MembershipScore = (ReversedZScore – @RescalingMin) / @RescalingRange
SELECT ID, PrimaryKey, Value, ZScore1, ZScore2, MembershipScore1, MembershipScore2, CombinedMembershipScore
FROM (SELECT T1.ID, T1.PrimaryKey, T1.Value, T1.ZScore AS ZScore1, T2.ZScore as ZScore2,
T1.MembershipScore MembershipScore1, T2.MembershipScore AS MembershipScore2, T1.MembershipScore * T2.MembershipScore AS CombinedMembershipScore
FROM @ZScoreTable1 AS T1
INNER JOIN @ZScoreTable2 AS T2
ON T1.ID = T2.ID) AS T3
WHERE CombinedMembershipScore IS NOT NULL
ORDER BY CombinedMembershipScore DESC
— if we want to store the values in the original table, we can use code like this:
UPDATE T4
SET T4.MembershipScore1 = T3.MembershipScore1, T4.MembershipScore2 = T3.MembershipScore2, T4.CombinedMembershipScore =
T3.CombinedMembershipScore
FROM DataMiningProjects.Health.DuchennesTable AS T4
INNER JOIN (SELECT T1.PrimaryKey, T1.MembershipScore AS MembershipScore1, T2.MembershipScore AS MembershipScore2, T1.MembershipScore * T2.MembershipScore AS CombinedMembershipScore
FROM @ZScoreTable1 AS T1
INNER JOIN @ZScoreTable2 AS T2
ON T1.ID = T2.ID) AS T3
ON T4.ID = T3.PrimaryKey
Figure 2: Sample Results from the Duchennes Practice Data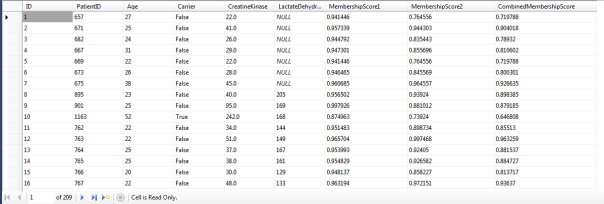
…………Figure 2 gives a glimpse of what the original DuchennesTable might look like if we wanted to store these values rather than calculate them on the fly, which can be accomplished by adding the three float columns on the right to the table definition and executing the UPDATE code at the end of Figure 1. In natural language, we might say that “the first record is 0.941446th of a member in the set around the average Creatine Kinase value” but “the fifth record is only 0.764556th of a member of the set near the mean Lactate Dehydrogenase value.” We could even model deeper levels of imprecision by creating categories like “near” for the high membership values in each column and “outlier” for the lowest ones, then define their boundaries in terms of fuzzy sets. This might be an ideal use for triangular and trapezoidal numbers, which can be worth the expense in extra code, as I’ll explain a few articles from now. We’re also modeling a different type of imprecision in another sense, because we know instinctively that there ought to be some way of gauging whether or not a record’s an outlier when both columns are taken into account; perhaps nobody knows precisely what the rules for constructing such a metric might be, but the CombinedMembershipScore at least allows us to get on the board.
…………Please keep in mind that I’m only using Z-Scores here because it’s familiar to me and is ideal for illustrating how fuzzy sets can be easily adapted to one particular use case, outlier detection. If we needed to make inferences about how well the data fit a gamma or exponential distribution, we might as well have used the corresponding goodness-of-fit tests and applied some rescaling techniques to derive our membership values; if we needed to perform fuzzy clustering, we could have plugged in a Manhattan distance function or one of its relatives. Fuzzy set memberships are often completely unrelated to stochastics and should not be interpreted as probabilities unless you specific intend to model them. The usefulness of fuzzy sets is greatly augmented when we move beyond mere set membership by tweaking the meaning a little, so that they can be interpreted as degrees of evidence, reliability, risk, desirability, or the like, which allow us to plug into various other well-developed mathematical theories. All functions can be differentiated by their return types, number of return and input values, allowable data types and ranges, mathematical properties and the like (not to mention performance costs), but in fuzzy set theory the issue of meaning has a somewhat more prominent role. In some cases, it may even be desirable to use multiple membership functions to determine membership in one fuzzy set, as in my crude example above. These myriad shades of meaning and potential for combinations of them lead to a whole new level of complexity, which may nonetheless be worthwhile to wade through for certain imprecision modeling problems.
A Taxonomy of Fuzzy Sets (that Doesn’t Tax the Brain)
I originally figured that I’d have to organize this series according to a taxonomy of different types of fuzzy sets, but it’s actually fairly simply to sketch the outlines of that otherwise advanced topic. Instead of delving into all of the complex math, it’s a lot easier for a layman to dream up all of the combinations of all the places in a set they can apply fuzziness, different means of encoding it and so on. The important thing to keep in mind is that there’s probably a term out there for whatever combination you’re using and that somewhere along the line, mathematicians have probably already figured out most of the logical implications decades ago (thereby saving a lot of the grunt work and reinventing the wheel, assuming that you can interpret their writing and the really thick formulas that often accompany them). The easiest ones to explain are real-valued and interval sets, in which the membership functions are determined on the real number line (which is all we ever encounter in SQL Server) or by a range of values on it.[4] Type-2 Fuzzy Sets illustrate the concept of tacking on further fuzziness perfectly – all we do take an interval-valued set and then assign grades to its boundaries as well. Fuzzy set theorists Yingjie Yang and Chris Hinde state that “A type-2 fuzzy set describes its memberships using type-1 fuzzy sets, but it needs precise crisp values to describe its secondary memberships.”[5] As the levels and number of values needed to define these sets proliferates, the performance costs do as well, so one has to be sure in advance that the extra complexity is useful in modeling real-world data. As Klir and Yuan put it, “Fuzzy sets of type 2 possess a great expressive power, and, hence, are conceptually quite appealing. However, computational demands for dealing with them are even greater than those for dealing with interval-valued sets. This seems to be the primary reason why they have almost never been utilized in any applications.”[6] I’d wager that’s still true, given the fact that the applications of ordinary fuzzy sets to data mining, data warehousing and relational databases have barely been scratched since the mathematicians invented these things years ago.
…………Rough sets also involve fuzzy values on intervals in a sense, but they model approximate distinctions between objects. Say, for example, you classify all of the objects in a child’s bedroom and want to see which qualify as part of a set labeled Toys. A sports car might be considered an adult toy to a certain degree, depending on such factors as whether or not the owner uses it for purposes other than occasional joy rides. The plastic dinosaurs and megafauna in a Prehistoric Playset are certainly toys, as are Fisher Price’s wooden people (well, cheap plastic these days). Medicine definitely wouldn’t belong to the set (at least according to these singing pills). Would one of these classic glow-in-the-dark Godzilla models from the ‘70s qualify? Well, that’s not quite clear, since it’s an object only a child would really appreciate, but they’re unlikely to actually play with it as a toy very often, since it’s designed to stay on display. They could conceivably take them off the shelf and pit them against the Fisher Price people; in this instance, the set membership might be defined by criteria as fuzzy as the whims of a child’s imagination, but we have tools to model it, if a need should arise. The definition of the attribute is in question, not whether a particular row belongs to a set, which is the case with ordinary fuzzy membership functions.
…………In Soft Sets, the characteristics that define the set are themselves fuzzy. I haven’t attempted to model those yet, but I imagine it may require comparisons between tables and views and placing weights on how comparable their different columns are to each other, rather than the rows. Here’s a crude and possibly mistaken example I came up with off the top of my head: in Soft Sets you might have a table with columns for Height, Width and Age and another with columns for Height, Width and Time, in which the first two columns of each are completely related to each and therefore are assigned weights of one, whereas Age and Time are only tangentially related and therefore might be assigned a weight somewhere between 0 and 1. Near sets apparently address a problem tangential to rough and soft sets, by quantifying the quantity and quality of resemblances between objects that might belong to a fuzzy set. Once we’ve been introduced to these concepts, they can obviously be combined together into an endless array of variants, which go by such mouthfuls as “rough intuitionistic Level-2 fuzzy near sets.” Just keep in mind that it is more common to encounter such structures in the real world in everyday language than it is to know the labels and their mathematical properties. It is also easier than it sounds to implement them in practice, if we’re using set-based tools like T-SQL that are ideal for the job.
…………I probably won’t spend much time in this series on even more sophisticated variants that might nonetheless be useful in modeling particular problems. Shadowed sets used multidimensional projections to qualify the lack of knowledge of whether or not a data point belongs to a fuzzy set. Neural nets are a cutting-edge topic I hope to tackle on this blog in a distant future (my interest in data mining was piqued way back in the 1990s when I saw some I cooked up at home do remarkable things) but it is fairly easy to describe Neuro-Fuzzy Sets, in which we’re merely using neural nets to perform some of the functions related to fuzzy sets. The combinations that can be derived from are limited only by one’s imagination; there are already neural nets in use in industry today that use fuzzy functions for activation and fuzzy sets whose membership values are derived from neural nets, and so forth. Undetermined and Neutrosophic Logic are variants of fuzzy logic that can be applied to fuzzy sets if we need to model different types of indeterminacy, which is a topic I’ll take up in a future article on how fuzzy sets can be put to good use in uncertainty management.
…………Blurry sets are a recent innovation designed to incorporate the kind of combinations of fuzziness we’ve just mentioned, but without sacrificing the benefits of normal logic – which might be of great benefit in the long run, since the value of some of recently developed logical systems is at best unproven.[7] Some will probably be substantiated in the long run, but some seem to be motivated by the sort of attention-getting shock value that can make academicians famous overnight these days (some of them seem to be implementations and formal defenses of solipsism, i.e. one of the defining characteristics of schizophrenia). Q-Sets are apparently an even more advanced variants developed for use in the strange world of quantum physics; since making Schrödinger’s cat disappear isn’t among most SQL Server users’ daily duties, I’ll leave that one out for now. I’ll probably also steer away from discussing more advanced types of fuzzy sets that include multiple membership functions, which aren’t referenced often in the literature and apparently are implemented only in rare circumstances.. Intuitionistic Sets have two, one for membership or non-membership, while Vague Sets also use two, except in that case one assesses the truth of the evidence for a record’s membership and the other its falsehood; I presume truth tables and the like are then built from the two values. A novel twist on this theme is the use of multiple membership functions to model the fact that the programmer is uncertain of which membership functions to use in defining fuzzy sets.[8] Multisets are often lumped in with the topic of fuzzy sets, but since they’re just sets that allow duplicate values, I don’t see much benefit in discussing them here. Genuine sets take fuzziness to a new level in an entirely different way, by generalizing the concept of fuzzy set in the same manner that fuzzy sets generalize ordinary “crisp” sets, but I won’t tack on another layer of mathematical complexity at this point, not when the potential for using the established methods of generalization has barely been scratched.
False Mysticism and the Fuzzy Mystique
This wide-open field is paradoxically young in terms of mathematical intellectual history, but overripe for implementation, given that many productive uses for it were derived decades ago but haven’t percolated down from academia yet. Taking a long view of the history of math, it seems that new waves of innovation involve the addition of new dimensions to existing objects. Leonhard Euler introduced complex numbers in the 18th Century, then theoreticians like Bernhard Riemann and Charles Hinton contributed the concepts of higher-dimensional space and its curvature in the 19th. Around the same time, Georg Cantor was working out set theory and such mind-blowing structures as high-cardinality infinities and transfinities. More recently, Benoit Mandelbrot elaborated the theory of fractional dimensions, which are now cornerstones in chaos theory and modern art, where they go by the better-known term of fractals. This unifying principle of mathematical innovation stretches back as far as ancient Greece, when concepts like infinity, continuous scales and the like were still controversial; in fact, the concept of zero did not reach the West until it was imbibed from Arab sources in the Middle Ages. Given that zero was accepted so late in history, it is thus not at all surprising that negative numbers were often derided by Western mathematicians as absurdities well into the 18th and 19th Centuries, many centuries after their discovery by Chinese and Indian counterparts.[9] A half-conscious prejudice against the infinite regress of non-repeating digits in pi and Euler’s number is embedded in the moniker they still go by today, “irrational numbers.” The same culprit is behind the term “imaginary number” as well. Each of these incredibly useful innovations was powered by the extension of scales into previously uncharted territory; each was also met by derision and resistance at first, as were fuzzy sets to a certain extent after their development by 20th Century theoreticians like Max Black and Lofti A. Zadeh.
…………Many of these leaps forward were also accompanied by hype and as sort of unbalanced intellectual intoxication, which is the main risk in using these techniques. Fuzzy sets are unique, however, in that some of the pioneers were conscious of the possibility of leveraging the term “fuzzy” for attention; Zadeh openly acknowledges that the term has its uses in terms of publicity power, although he did not originally invent the term for that purpose. The strategy has backfired to a certain extent, however, by drawing the wrong kind of attention. “Fuzzy” is a term that immediately conjures up many alternative images, many of which don’t seem conducive to a high-powered, mission-critical production environment – like teddy bears, static, 1970s cop shows and something out of the back of George Carlin’s fridge.
…………Many of the taxonomic terms listed above also carry a kind of shock value to them; in other branches of academia this usually signifies that the underlying theory is being overstated or is even the product of crackpots with tenure, but in this case there is substantial value once the advertising dross has been stripped away. In fact, I’d wager that if more neutral terms like “graded set” or “continuously-valued set” were used in place of “fuzzy,” these techniques would be commonplace today in a wide variety of industries, perhaps even database management; in this case, the hype has boomeranged by stunting the adoption of an otherwise indispensable set of tools. As McNeill points out, some of the researchers employed in implementing fuzzy sets in various industries (including the development of the space shuttle) back in the early ‘90s had to overcome significant institutional resistance from “higher-ups” who “fretted about image.”[10] They are right to fret within reason, because these tools can certainly be misapplied; in fact, I’ve seen brilliant theorists who grasp the math a lot better than I do abuse it in illogical ways (for the sake of being charitable, I don’t want to call them out by name). Some highly regarded intellectuals don’t recognize any boundaries to the theory, for all of reality is fuzzy in their eyes – which is the mark of fanaticism, and certain to stiffen any institutional resistance on the other side. Every mathematical innovation in history has not only been accompanied by knee-jerk opposition from Luddites on one side, but also unwarranted hype and irrational exuberance on the other; fuzzy sets are as susceptible to misuse by bad philosophers and fanatics as higher dimensions, chaos theory and information theory have been for decades, so it is not unwise to tread carefully and maintain intellectual sobriety when integrating fuzzy sets into any development process.
…………Perhaps the best way to overcome this kind of institutional resistance and receive backing for these techniques is to be up front and demonstrate that you recognize the hype factor, plus have clear litmus tests for discerning when and when not to apply fuzzy set theory. Two of these are the aforementioned criteria of searching for data that resides in between ordinal and continuous data in the hierarchy of Content types and sifting through natural language terms for imprecision modeling. It is also imperative to develop clear standards for differentiating between legitimate and illegitimate uses of fuzzy sets, to prevent the main risk: “fuzzifying” data that it is inherently crisp. It is indeed possible to add graded boundaries to any mathematical objects (some of which we’ll explore later in this series), but in many cases, there is no need to bother. Fuzzy logic in the wrong doses and situations can even lead to fallacious conclusions. In fact, applying fuzziness to inherently crisp objects and vice-versa is one of the fundamental strategies human beings have employed since time immemorial to deceive both themselves and others. Here’s a case in point we’ve all seen: you tell your son or daughter they can’t have a snack, but you catch them eating crackers; invariably, their excuse involves taking advantage of the broad interval inherent in the term “snack,” a set which normally, but not always, included crackers. Of course, when people grow up they sometimes only get more skilled at blurring lines through such clever speech (in which case they often rise high in politics, Corporate America and the legal profession). Here’s an important principle to keep in mind: whenever you see a lot of mental energy expended to tamper with the definitions of things, but find the dividing lines less clear afterwards, then it’s time to throw a red flag. The whole point of fuzzy sets is not to obscure clear things, but to clear up the parts that remain obscure. Fuzziness is in exactly the same boat as mysticism, which as G.K. Chesterton once said, is only useful when it explains mysteries:
“A verbal accident has confused the mystical with the mysterious. Mysticism is generally felt vaguely to be itself vague—a thing of clouds and curtains, of darkness or concealing vapours, of bewildering conspiracies or impenetrable symbols. Some quacks have indeed dealt in such things: but no true mystic ever loved darkness rather than light. No pure mystic ever loved mere mystery. The mystic does not bring doubts or riddles: the doubts and riddles exist already…The mystic is not the man who makes mysteries but the man who destroys them. The mystic is one who offers an explanation which may be true or false, but which is always comprehensible—by which I mean, not that it is always comprehended, but that it always can be comprehended, because there is always something to comprehend.”[11]
…………Fuzzy sets are not meant to mystify; they’re not nebulous or airy, but designed to squeeze some clarity out of apparently nebulous or airy data and logic. They are akin to spraying Windex on a streaky windshield; if you instead find your vision blocked by streaks of motor oil, it’s time to ask who smeared it there and what their motive was. Fuzziness isn’t an ingredient you add to a numerical recipe to make it better; it’s a quality inherent in the data, which is made clearer by modeling the innate imprecision that results from incomplete measurement, conflicting evidence and many other types of uncertainty. The point is not to make black and white into grey, but to shine a light on it, so that we can distinguish the individual points of black and white that make up grey, which is just a composite of them. These techniques don’t conjure up information; they only ensure that what little information is left over after we’ve defined the obvious crisp sets doesn’t go to waste. Fuzziness can actually arise from a surfeit of detail or thought, rather than a deficit or either; the definition of an object may be incomplete because so many sense impressions, images, stray thoughts, academic theories and whatnot are attached to its meaning that we can neither include them all nor leave any out.
…………As we shall see in future articles on uncertainty management, the manner in which the meaning of set membership can be altered to incorporate evidence theory and the like is indeed empowering, but calls for a lot of mental rigor to resist unconscious drifts in definition. It’s an all-too human problem that can occur to anyone, particular when mind-blowing topics are under discussion; it’s even noticeable at times in the writings of brilliant quantum physicists, who sometimes unconsciously define their terms slightly differently at the beginning of a book than at the end, in ways that nonetheless make all the difference between Schrödinger’s Cat being alive or dead. “Definition drift” also seems to be a Big Problem in Big Analysis for the same reason. It likewise seems to occur in texts on fuzzy sets, where term “fuzz” is often accurately described on one page as a solution to innate imprecision, but on the next, is unconsciously treated as if it were a magic potion that ought to be poured on everything. Another pitfall is getting lost in all of the bewildering combinations of fuzziness I introduced briefly in the taxonomy, but the answer to that is probably to just think of them in terms of ordinary natural language and only use the academic names when sifting through the literature for appropriate membership functions and the like. Above all, avoiding modeling crisp sets that have inherently Boolean yes-or-no membership values as fuzzy sets, because as the saying goes, you can’t be “a little bit pregnant.” Continuous scales can certainly be added to any math object, but if the object being modeled is naturally precise, then it is at best a waste of resources that introduces the risk of fallacious reasoning and at worst, an opening for someone with an axe to grind to pretend a particular scale is much more imprecise than it really is. One dead giveaway is the use of short scales in comparison to the length of the original crisp version. For example, this is the culprit when quibbling erupts over such obviously crisp sets as “dead” and “alive,” on the weak grounds that brain death takes a finite amount of time, albeit just a fraction of a person’s lifespan. It might be possible to develop a Ridiculousness Score by comparing the difference in intervals between those few moments, which occur on an almost infinitesimal scale, against an “alive” state that can span 70-plus years in human beings or the “dead,” which is always infinite. I haven’t seen that done in the literature, but in two weeks, I’ll demonstrate how the complements of fuzzy sets can be used to quantify just how imprecise our fuzzy sets are. The first two installments of this series were lengthy and heavy on text because we needed a solid grounding in the meaning of fuzzy sets before proceeding to lessons in T-SQL code, but the next few articles will be much shorter and immediately beneficial to anyone who wants to put it into action.
[1] pp. 290-293, Klir, George J. and Yuan, Bo, 1995, Fuzzy Sets and Fuzzy Logic: Theory and Applications. Prentice Hall: Upper Saddle River, N.J.
[2] IBID., pp. 287-288, 292-293.
[3] IBID., p. 281.
[4] For a quick introduction to the various fuzzy set types, see the Wikipedia article Fuzzy Sets at http://en.wikipedia.org/wiki/Fuzzy_set. I consulted it to make sure that I wasn’t leaving out some of the newer variants that came out since Klir and Yuan and some of the older fuzzy set literature I’ve read, much of which dates from the 1990s. I lost some of the citations to the notes I derived these three paragraphs from (so my apologies go out to anyone I might have inadvertently plagiarized) but nothing I said here can’t be looked up quickly on Wikipedia, Google or any recent reference on fuzzy sets.
[5] Hinde, Chris and Yang, Yingjie, 2000, A New Extension of Fuzzy Sets Using Rough Sets: R-Fuzzy Sets, pp. 354-365 in Information Sciences, Vol. 180, No. 3. Available online at the web address https://dspace.lboro.ac.uk/dspace-jspui/bitstream/2134/13244/3/rough_m13.pdf
[6] p. 17, Klir and Yuan.
[7] Smith, Nicholas J. J., 2004, Vagueness and Blurry Sets, pp 165-235 in Journal of Philosophical Logic, April 2004. Vol. 33, No. 2. Multiple online sources are available at http://philpapers.org/rec/SMIVAB
[8] See Pagola, Miguel; Lopez-Molina, Carlos; Fernandez, Javier; Barrenechea, Edurne; Bustince, Humberto , 2013, “Interval Type-2 Fuzzy Sets Constructed From Several Membership Functions: Application to the Fuzzy Thresholding Algorithm,” pp. 230-244 in IEEE Transactions on Fuzzy Systems, April, 2013. Vol. 21, No. 2. I haven’t read the paper yet (I simply can’t afford access to many of these sources) but know of its existence.
[9] See Rogers, Leo, 2014, “The History of Negative Numbers,” published online at the NRICH.com web address http://nrich.maths.org/5961.
[10] pp. 261-262, McNeill.
[11] Chesterton, G.K., 1923, St Francis of Assisi. Published online at the Project Gutenberg web address http://gutenberg.net.au/ebooks09/0900611.txt

![]()
