

Azure Data Factory V2 allows developers to branch and chain activities together in a pipeline. We define dependencies between activities as well as their their dependency conditions. Dependency conditions can be succeeded, failed, skipped, or completed.
This sounds similar to SSIS precedence constraints, but there are a couple of big differences.
- SSIS allows us to define expressions to be evaluated to determine if the next task should be executed.
- SSIS allows us to choose whether we handle multiple constraints as a logical AND or a logical OR. In other words, do we need all constraints to be true or just one.
ADF V2 activity dependencies are always a logical AND. While we can design control flows in ADF similar to how we might design control flows in SSIS, this is one of several differences. Let’s look at an example.

The pipeline above is a fairly common pattern. In addition to the normal ADF monitoring that is available with the product, we may log additional information to a database or file. That is what is happening in the first activity, logging the start of the pipeline execution to a database table via a stored procedure.
The second activity is a Lookup that gets a list of tables that should be loaded from a source system to a data lake. The next activity is a ForEach, executing the specified child activities for each value passed along from the list returned by the lookup. In this case the child activity includes copying data from a source to a file in the data lake.
Finally, we log the end of the pipeline execution to the database table.
Activities on Failure
This is all great as long as everything works. What if we want something else to happen in the event that one of the middle two activities fail?
This is where activity dependencies come in. Let’s say I have a stored procedure that I want to run when the Lookup or ForEach activity fails. Your first instinct might be to do the below.
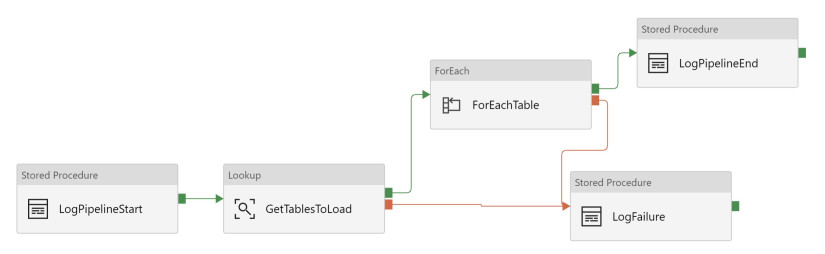
The above control flow probably won’t serve you very well. The LogFailure activity will not execute unless both the Lookup activity and the ForEach activity fails. There is no way to change the dependency condition so that LogFailure executes if the Lookup OR the ForEach fails.
Instead, you have a few options:
1). Use multiple failure activities.
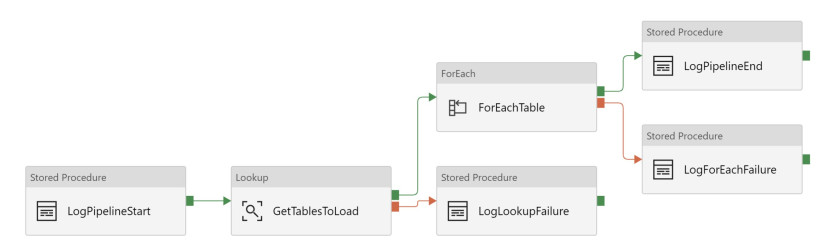
This is probably the most straight forward but least elegant option. In this option you add one activity for each potential point of failure. The stored procedure you execute in the LogLookupFailure and LogForEachFailure activities may be the same, but you need the activities to be separate so there is only one dependency for execution.
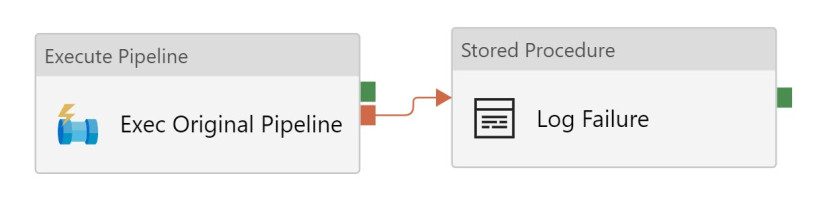
2) Create a parent pipeline and use an execute pipeline activity. Then add a single failure dependency from a stored procedure to the execute pipeline activity. This works best if you don’t really care in which activity your original/child pipeline failed and just want to log that it failed.
3) Use an If Condition activity and write an expression that would tell you that your previous activity failed. In my specific case I might set some activity dependencies to completed instead of success and replace the LogPipelineEnd stored procedure activity with the If Condition activity. If we choose a condition that indicates failure, our If True activity would execute the failure stored procedure and our If False activity would execute the success stored procedure.

Think of it as a dependency, not a precedence constraint.
It’s probably better to think of activity dependencies as being different than precedence constraints. This becomes even more obvious if we look at the JSON that we would write to define this rather than using the GUI. MyActivity2 depends on MyActivity1 succeeding. If we add another dependency in MyActivity2, it would depend both on that new one and the original dependency. Each additional dependency is added on.
{
"name": "MyPipeline",
"properties":
{
"description": "pipeline description",
"activities": [
{
"name": "MyActivity1",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
}
},
{
"name": "MyActivity2",
"type": "Copy",
"typeProperties": {
},
"linkedServiceName": {
},
"dependsOn": [
{
"activity": "MyActivity1",
"dependencyConditions": [
"Succeeded"
]
}
]
}
],
"parameters": {
}
}
}Do you have another way of handling this in Data Factory V2? Let me know in the comments.
If you would like to see Data Factory V2 change to let you choose how to handle multiple dependencies, you can vote for this idea on the Azure feedback site or log your own idea to suggest a different enhancement to better handle this in ADF V2.
