

Don’t be fooled by the title of this post: while counting the number of rows in a table is a trivial task for you, it is not trivial at all for SQL Server.
Every time you run your COUNT(*) query, SQL Server has to scan an index or a heap to calculate that seemingly innocuous number and send it to your application. This means a lot of unnecessary reads and unnecessary blocking.
Jes Schultz Borland blogged about it some time ago and also Aaron Bertrand has a blog post on this subject. I will refrain from repeating here what they both said: go read their blogs to understand why COUNT(*) is a not a good tool for this task.
The alternative to COUNT(*) is reading the count from the table metadata, querying sys.partitions, something along these lines:
SELECT SUM(p.rows)
FROM sys.partitions p
WHERE p.object_id = OBJECT_ID('MyTable')
AND p.index_id IN (0,1); -- heap or clustered index
Many variations of this query include JOINs to sys.tables, sys.schemas or sys.indexes, which are not strictly necessary in my opinion. However, the shortest version of the count is still quite verbose and error prone.
Fortunately, there’s a shorter version of this query that relies on the system function OBJECTPROPERTYEX:
SELECT OBJECTPROPERTYEX(OBJECT_ID('MyTable'),'cardinality')
Where does it read data from? STATISTICS IO doesn’t return anything for this query, so I had to set up an Extended Events session to capture lock_acquired events and find out the system tables read by this function:
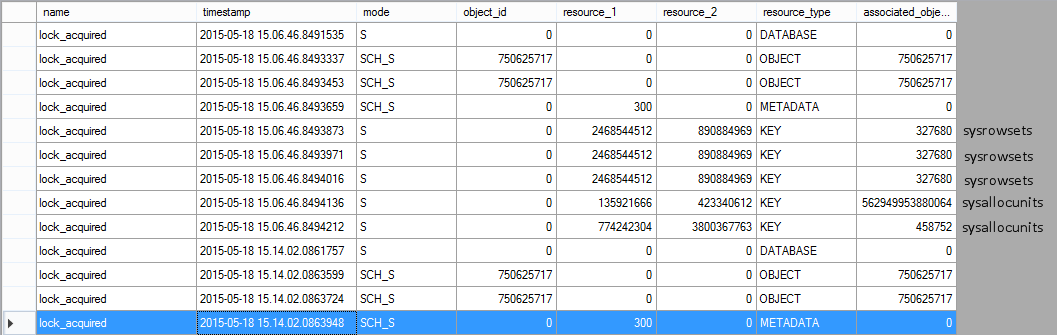
Basically, it’s just sysallocunits and sysrowsets.
It’s nice, short and easy to remember. Enjoy.

![]()
