

Let’s take a break from our SQL Server 2017 Reporting Services Basics Series and jump to Azure Data Factory (v2). The latest installment on our SSRS Series is about adding a simple parameter to the report, which you can find here.
Azure Data Factory (ADF) is a data integration service for cloud and hybrid environments (which we will demo here). ADF provides a drag-and-drop UI that enables users to create data control flows with pipeline components which consist of activities, linked services, and datasets. of course, there’s an option to set up components manually for more control. More info on ADF can be found here.
ADF is basically a fully-managed Azure service that provides a platform for orchestrating data movement or Extraction, Transformation, and Loading (ETL) of data from sources to target databases or analytics services. If you’re thinking of SSIS, that would be a similar concept.
In this post, we’ll learn how to copy data from our local instance of SQL Server into an Azure SQL Database by using Azure Data Factory (v2).
First thing first, if you do not have access to an Azure Subscription, sign up for a trial account here. Then, create the following services:
- Azure SQL Database
- Azure Data Factory (v2)
- Local Instance of SQL Server 2017
- WideWorldImporters Database (in your local instance)
Choosing a Pipeline Template
From your Azure Portal, navigate to your Resources and click on your Azure Data Factory. In the ADF blade, click on Author & Monitor button.

That will open a separate tab for the Azure Data Factory UI. For this demo, we’re going to use a template pipeline.

From the Template Gallery, select Copy data from on-premise SQL Server to SQL Azure.

That will open the panel for setting up the pipeline. Since this is the first time we’re copying a local SQL Server into Azure SQL Database on this ADF, we need to set up the connection between our local database and ADF.
Create the Datasource
From the panel, in the Datasource field, click the dropdown and select New. You can also click the link to the documentation for this template which gives you information about capabilities, prerequisites, and other info of this pipeline.

Create A Linked Service
Clicking New
In the Connect via Integration Runtime, select New.
“But what is Integration Runtime?”, you ask:
The Integration Runtime (IR) is the compute infrastructure used by Azure Factory to provide data integration capabilities across different network environments. Azure Integration Runtime can be used to connect to data stores and compute services in public network with public accessible endpoints. Use a self-hosted Integration Runtime for Private/On-Premise Networks.
Azure Data Factory Integration Runtime Info
In the Integration Runtime Setup panel, select Self-Hosted.

Click Next. Let’s name our runtime LocalDBAzureDBRuntime. Add a description if you want. The runtime Type, Self-Hosted, should already be selected by the system. Click Next again.
The next panel will provide two options to install the run time – Express or Manual. It also provides a couple of authentication keys to use if you want to add more nodes.
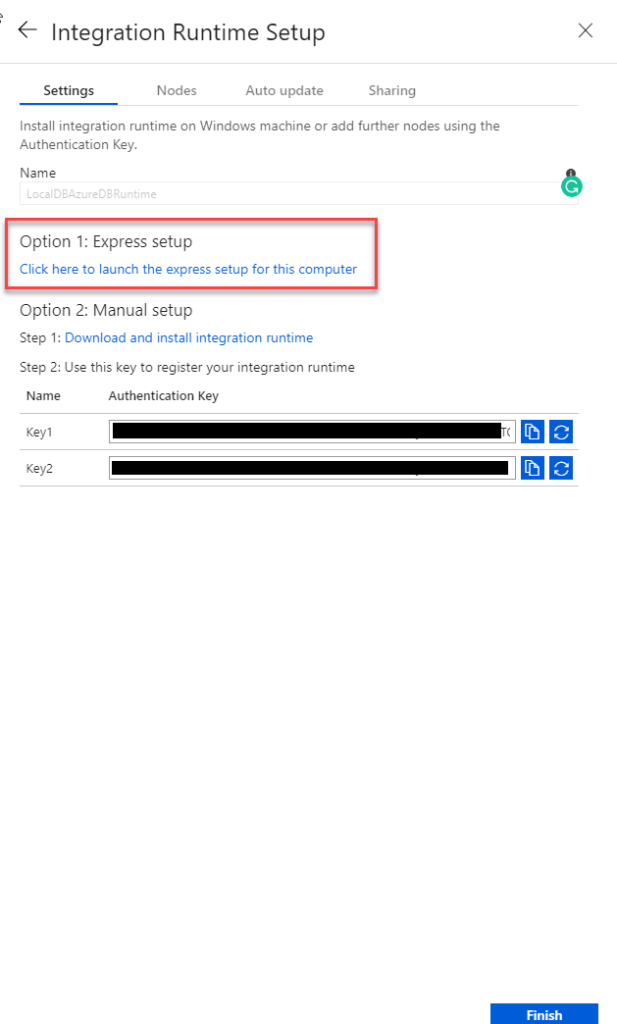
Let’s select Express setup. The link will download an executable. Save it to a convenient location. Run the executable.
The installer will download, install, and register all the necessary components for the runtime. It will also install a configuration manager that we can use to set up, diagnose, and update the runtime. When you get the successful installation message, click Close.

Setting up the Linked Service to Local SQL Server
Next, we need to change settings of the runtime. Find and open the Microsoft Integration Runtime Configuration Manager.

Click the Settings tab. On the Status, there’s a link that says Change. Click that. For the purpose of this demo, let’s select the basic option. Of course, you may want to encrypt the service if this is a production server.

Click OK. That will restart the runtime. Wait until it reconnects to the cloud. You can test the connections on both ends – local SQL Server and Azure Database – in the Diagnostics tab.
Go back to the New Linked Service panel to complete the

Click Finish.
Create the Destination Table
Now before we set up the destination Azure SQL Database, let’s connect to the Azure Database via SQL Server Management Studio (SSMS) and create a new table called StockGroupLineProfit.

CREATE TABLE StockGroupLineProfit (
StockGroupName VARCHAR (255)
, LineProfit FLOAT ) ;Let’s go back to the template setup and select the DataDestination. I have already set up my Azure SQL Database in advance. Select the Azure SQL Database. Set a new one if you haven’t done so.
Click Use This Template.
In the pipeline designer UI, set the Timeout of the General properties to 30 minutes. That’s enough time for the service to copy the amount of data that we’re going to set in the pipeline.
Set The Pipeline Data Source
Let’s create a new Source. Let’s name it LocalSQLWideWorldImporters. For the Connection, let’s select the Linked Service that we created above.

Let’s go back to the Source setting of our pipeline. Under the Source Dataset, select Query and input the following query.
SELECT sg.StockGroupName , SUM( il.LineProfit ) AS LineProfit FROM Sales.InvoiceLines il JOIN Warehouse.StockItems si ON il.StockItemID = si.StockItemID JOIN Warehouse.StockItemStockGroups sis ON si.StockItemID = sis.StockItemID JOIN Warehouse.StockGroups sg ON sis.StockGroupID = sg.StockGroupID GROUP BY sg.StockGroupName ;
If that T-SQL Code is familiar, it is because it’s the same query we used for our SSRS Report here.

Preview the data so we can have an idea of what we are loading to our Azure SQL Database.

In the Sink tab, let’s create a new sink dataset. Click New. Select
Let’s name our sink dataset AzureStockGroup. For the linked service, I am selecting the Azure SQL Database that I have already set up prior. You have to create a new service if you haven’t done so. This is our target or destination Azure SQL Database. For the Table, select the table that we just created via SSMS, StockGroupLineProfit.
In the Schema tab of the sink setup, add the following columns:
- StockGroupName (of type String)
- LineProfit (of type Decimal)
The preview of the destination should be empty at this point.

Now that both the data source and destination for the pipeline are set up, go back to the pipeline designer. Select the Mapping tab. The source/destination mapping should now show up; if not, click the Import Schemas button.

Publish the Pipeline
To publish the pipeline and the linked services that we just created, click Publish All button at the top of the designer.
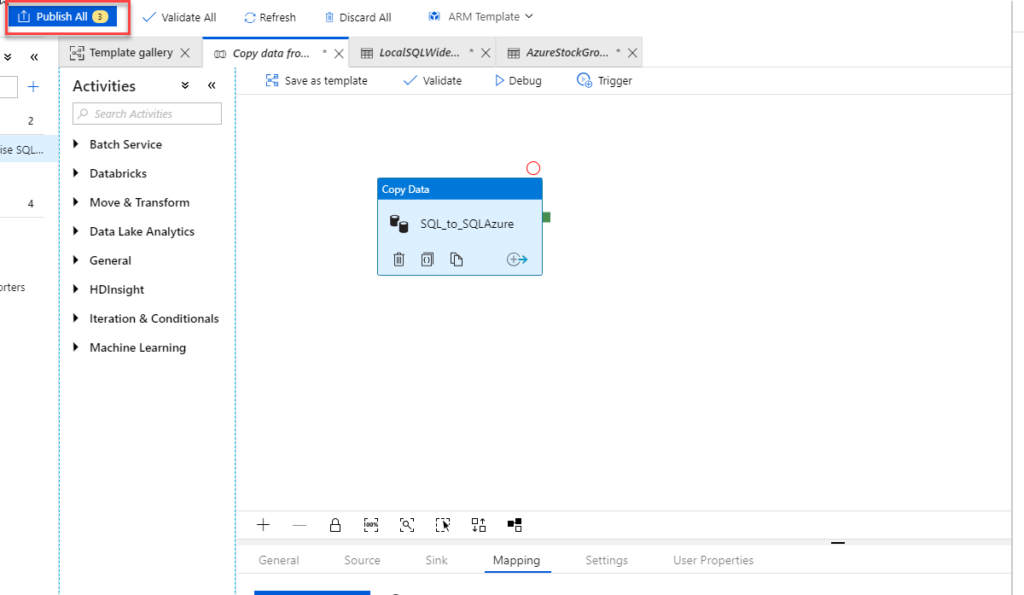
You should get a notification on the status of the published objects.

Run the Pipeline
Let’s click Debug in the pipeline designer. What debug does here is to actual run the pipeline and copy from the data set we defined in our data source and into our destination. Wait until the Succeeded message appears.

And, if we query our Azure SQL Database, we should now have the data in our destination table.

Enjoy orchestrating your data using Azure Data Factory!
The post Copy Data From On-Premise SQL Server To Azure Database Using Azure Data Factory appeared first on SQL, Code, Coffee, Etc..

![]()
