

[read this post on Mr. Fox SQL blog]
When it comes to enabling data compression in SQL Server I suspect most people don’t do a lot of testing as to the impacts of either enabling compression and its ongoing maintenance. I assume most are interested in its ongoing performance for queries, and you know that’s damn fair enough too!
If you read the Microsoft Data Compression Whitepaper (and I mean whos got time to do that!) then it has some interesting technical tidbits burried deep in there which affect the impacts of applying and managing data compression.
https://technet.microsoft.com/en-us/library/dd894051(v=sql.100).aspx
Here are some of the ones of interest…
SQL Server uses statistics on the leading column to distribute work amongst multiple CPUs, thus multiple CPUs are not beneficial when creating, rebuilding, or compressing an index where the leading column of the index has relatively few unique values or when the data is heavily skewed to just a small number of leading key values – only limited effective parallelism will be achieved in this case.
And this…
Compressing or rebuilding a heap with ONLINE set to ON uses a single CPU for compression or rebuild. However, SQL Server first needs to scan the table—the scan is parallelized, and after the table scan is complete, the rest of the compression processing of the heap is single-threaded.
And this…
When a heap is compressed, if there are any nonclustered indexes on the heap, they are rebuilt as follows:
(a) With ONLINE set to OFF, the nonclustered indexes are rebuilt one by one.
(b) With ONLINE set to ON, all the nonclustered indexes are rebuilt simultaneously.
You must account for the workspace required to rebuild the nonclustered indexes, because the space for the uncompressed heap is not released until the rebuild of the nonclustered indexes is complete.
That first one is a cracker – it hit me once when compressing a SQL Server table (600M+ rows) on a 64 core Enterprise SQL Server. After benchmarking several other data compression activities I thought I had a basic “rule of thumb” (based on GB data size and number of rows)… of which just happened to be coincidence!
This also begs the question of why would you use low selectivity indexes? Well I can think of a few cases – but the one which stands out the most is the identification of a small number of rows within a greater collection – such as an Index on TYPE columns (ie; [ProcessingStatusFlag] CHAR(1) = [P]rocessed, nprocessed, [W]orking, [F]ailed, etc)
… AND SO – lets do some testing to validate this puppy!
Validating the Performance of Applying Compression
Setup the Test Table and Load Some Data
CREATE TABLE dbo.CompressionTable
(
MySelectiveID INTEGER NOT NULL,
MyNonSelectiveID INTEGER NOT NULL,
MyPageFiller VARCHAR(7950) NOT NULL
)
GO
INSERT INTO dbo.CompressionTable
SELECT TOP 1000000
ROW_NUMBER() OVER (ORDER BY o1.object_id)
, 0
, REPLICATE('X', 7900)
FROM master.sys.objects o1
CROSS JOIN master.sys.objects o2
CROSS JOIN master.sys.objects o3
ORDER BY 1
GO
SELECT count(DISTINCT MySelectiveID) FROM dbo.CompressionTable
SELECT count(DISTINCT MyNonSelectiveID) FROM dbo.CompressionTable
GO
The data in the first column [MySelectiveID] is highly selective (941192 unique rows) and the data in the second column [MyNonSelectiveID] only has a single value.
Now lets build a PAGE compressed clustered index on the table in turn first on the SELECTIVE column and then on the NON-SELECTIVE column and see what happens.
SET STATISTICS IO ON SET STATISTICS TIME ON GO CREATE CLUSTERED INDEX IX_CompressionTable ON dbo.CompressionTable ( MySelectiveID, MyNonSelectiveID ) WITH (DATA_COMPRESSION = PAGE, ONLINE = ON) GO DROP INDEX IX_CompressionTable ON dbo.CompressionTable GO CREATE CLUSTERED INDEX IX_CompressionTable ON dbo.CompressionTable ( MyNonSelectiveID, MySelectiveID ) WITH (DATA_COMPRESSION = PAGE, ONLINE = ON) GO
Statistics for Clustered Index on the SELECTIVE column
Table ‘CompressionTable’. Scan count 4, logical reads 9921742.
SQL Server Execution Times:
CPU time = 93673 ms, elapsed time = 119562 ms.
Statistics for Clustered Index on the NON-SELECTIVE column
Table ‘CompressionTable’. Scan count 1, logical reads 6399967.
SQL Server Execution Times:
CPU time = 69859 ms, elapsed time = 139028 ms.
The data shows that the SELECTIVE index build is 17% faster than the NON-SELECTIVE index build.
Graphical Show Plans for the Clustered Index Builds for both types shows the SELECTIVE build process uses parallelism, and the NON-SELECTIVE build does not.
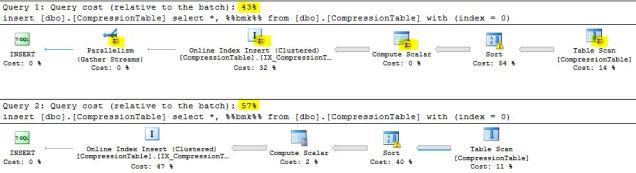
Performance Gap Increases for Larger Machines
As the size of the machine running SQL increases, the performance gap between selective and non-selective columns becomes more significant. So as higher specification machines are deployed (such as 8, 16, 32, 64 cores/threads) the performance of low selectivity indexes may begin to cause noticeable delays in maintenance.
Rerunning a larger row test on an Azure D14 (16 cores, 112GB RAM, SQL 2016 CTP3.3, Enterprise) has provided the statistics below;
- SELECTIVE = 16 x scans, completed in 231746 ms (elapsed)
- NON-SELECTIVE = 1 x scan, completed in 834116 ms (elapsed)
The SELECTIVE index is now 360% faster than the NON-SELECTIVE.
Key Summary
The findings show some interesting things.
- The performance of building a new (compressed) clustered index is absolutely dependent on the selectivity of the leading column in the index.
- An index with a selective column will use all cores (assuming full MAXDOP), whereas an index with a non-selective column will only use a single core.
- Assuming full MAXDOP, higher specification machines more readily show the performance gap, whereas low spec machines will be only marginally different.
- All subsequent index rebuild and maintenance operations on a selective index will continue to be significantly faster and run in parallel, whereas any non-selective index will not. (The leading column selectivity is like a go fast/slow switch!)
- I could not reliably reverse engineer the point where the query optimiser swaps from single threaded to parallel operations based on the selectivity of the leading column. If the non-selective column has say 2 distinct values the optimiser still used a single thread. Even at 5 distinct values it was still single threaded. However when I jumped out to 20 values parallelism kicked in. (Why? One to work out another day!)
- The performance differences seem to be more evident in clustered indexes (tables) than non-clustered indexes — this is likely as there is more data to deal with in clustered indexes.
If you have indexes that fit this model then I suggest giving it a test yourself to see how you may be impacted – because as I always say, your mileage may vary!
So there you have it – the data does not lie!
NOTE – The core of my tests were performed on SQL Server 2014 Enterprise (12.0.4100.1) with 8GB and 4 cores.
Disclaimer: all content on Mr. Fox SQL blog is subject to the disclaimer found here
