

I did a post the other day on comparing two tables. It was meant as a general overview but I got a fair number of comments and requests for more specifics. So here we go.
- TABLEDIFF.exe
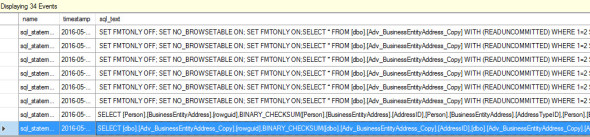
I had one comment that TABLEDIFF uses REBAR functionality. So let’s try an XE session and see.
First we set up a test table to compare with a few differences.
SELECT * INTO Adv_BusinessEntityAddress_Copy FROM AdventureWorks2014.Person.BusinessEntityAddress WHERE AddressID NOT BETWEEN 15600 AND 15700 UPDATE Adv_BusinessEntityAddress_Copy SET ModifiedDate = DATEADD(day,50,ModifiedDate) WHERE AddressID > 29865
Set up a basic simple XE event trace that checks only sp_statement_completed and sql_statement_completed events.
CREATE EVENT SESSION [SQL Statements] ON SERVER ADD EVENT sqlserver.sp_statement_completed( ACTION(sqlserver.sql_text)), ADD EVENT sqlserver.sql_statement_completed( ACTION(sqlserver.sql_text)) WITH (MAX_MEMORY=4096 KB,EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,MAX_DISPATCH_LATENCY=30 SECONDS,MAX_EVENT_SIZE=0 KB,MEMORY_PARTITION_MODE=NONE,TRACK_CAUSALITY=OFF,STARTUP_STATE=OFF) GOHere is the code for the tablediff. I did mention there were a lot of parameters didn’t I?
tablediff.exe -sourceserver "(local)\sql2014cs" -sourcedatabase AdventureWorks2014 -sourcetable "BusinessEntityAddress" -sourceschema "Person" -destinationserver "(local)\sql2014cs" -destinationdatabase "Test" -destinationtable "Adv_BusinessEntityAddress_Copy"

Honestly I’m not seeing any evidence here that what we are seeing is REBAR. I ran the same test using profiler with the same results. Only 34 rows in the output and it’s a ~20k row table. Now it could be that I’m looking at the wrong events or that with larger tables that it will break it up into chunks. End result I still consider this an option but use with care on larger tables.
- Roll your own
Now this can get a bit complicated but it’s easily the most versatile of any comparison methods. You can compare only certain columns by specifying just those in the field list and/or using a WHERE clause only compare certain portions of the table. A single division or country for example.
In the comments I did have it pointed out that using EXCEPT simplifies things quite a bit (and it does) and I was asked for an example. Even with EXCEPT it’s not overly simple and we still need several queries. Using the same two tables:
This query checks to make sure the schemas of the two tables are close enough to compare. I’m using INFORMATION_SCHEMA. I know some people don’t like it but for this it’s the easiest and will work just fine.
SELECT COLUMN_NAME COLLATE SQL_Latin1_General_CP1_CS_AS COLUMN_NAME, ORDINAL_POSITION, IS_NULLABLE COLLATE SQL_Latin1_General_CP1_CS_AS IS_NULLABLE, DATA_TYPE COLLATE SQL_Latin1_General_CP1_CS_AS DATA_TYPE, CHARACTER_MAXIMUM_LENGTH, CHARACTER_OCTET_LENGTH, NUMERIC_PRECISION, NUMERIC_PRECISION_RADIX, NUMERIC_SCALE, DATETIME_PRECISION, CHARACTER_SET_CATALOG COLLATE SQL_Latin1_General_CP1_CS_AS CHARACTER_SET_CATALOG, CHARACTER_SET_SCHEMA COLLATE SQL_Latin1_General_CP1_CS_AS CHARACTER_SET_SCHEMA, CHARACTER_SET_NAME COLLATE SQL_Latin1_General_CP1_CS_AS CHARACTER_SET_NAME, COLLATION_CATALOG COLLATE SQL_Latin1_General_CP1_CS_AS COLLATION_CATALOG, COLLATION_SCHEMA COLLATE SQL_Latin1_General_CP1_CS_AS COLLATION_SCHEMA, COLLATION_NAME COLLATE SQL_Latin1_General_CP1_CS_AS COLLATION_NAME FROM AdventureWorks2014.INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME = 'BusinessEntityAddress' AND TABLE_SCHEMA = 'Person' EXCEPT SELECT COLUMN_NAME, ORDINAL_POSITION, IS_NULLABLE, DATA_TYPE, CHARACTER_MAXIMUM_LENGTH, CHARACTER_OCTET_LENGTH, NUMERIC_PRECISION, NUMERIC_PRECISION_RADIX, NUMERIC_SCALE, DATETIME_PRECISION, CHARACTER_SET_CATALOG, CHARACTER_SET_SCHEMA, CHARACTER_SET_NAME, COLLATION_CATALOG, COLLATION_SCHEMA, COLLATION_NAME FROM Test.INFORMATION_SCHEMA.COLUMNS WHERE TABLE_NAME = 'Adv_BusinessEntityAddress_Copy' AND TABLE_SCHEMA = 'dbo'
Since that returned no rows we can now start to compare the actual data. First we use EXCEPT to check for rows in the source table that don’t have exact matches in the destination table. This is going to include both the rows missing from the destination table and those that exist but are different. I’m going to dump all of the output into a temp table #FirstPass. Next we go the other direction. All rows from the destination table that aren’t in the source table and unfortunately all of the rows that are different, again. This time I’m going to put the data into a temp table #SecondPass.
SELECT * INTO #FirstPass FROM AdventureWorks2014.Person.BusinessEntityAddress EXCEPT SELECT * FROM Adv_BusinessEntityAddress_Copy SELECT * INTO #SecondPass FROM Adv_BusinessEntityAddress_Copy EXCEPT SELECT * FROM AdventureWorks2014.Person.BusinessEntityAddress
The problem is that both #FirstPass and #SecondPass have the differences not just the missing rows. So let’s pull those out and while we are at it get the missing rows separated out. To do that we need to know at least one unique key. In this case the primary key of Person.BusinessEntityAddress is BusinessEntityID, AddressID, AddressTypeID.
SELECT * INTO #SourceOnly FROM #FirstPass WHERE NOT EXISTS (SELECT 1 FROM #SecondPass WHERE #FirstPass.BusinessEntityID = #SecondPass.BusinessEntityID AND #FirstPass.AddressID = #SecondPass.AddressID AND #FirstPass.AddressTypeID = #SecondPass.AddressTypeID) SELECT * INTO #DestinationOnly FROM #SecondPass WHERE NOT EXISTS (SELECT 1 FROM #FirstPass WHERE #FirstPass.BusinessEntityID = #SecondPass.BusinessEntityID AND #FirstPass.AddressID = #SecondPass.AddressID AND #FirstPass.AddressTypeID = #SecondPass.AddressTypeID) SELECT * INTO #DifferencesOnly FROM #FirstPass WHERE EXISTS (SELECT 1 FROM #SecondPass WHERE #FirstPass.BusinessEntityID = #SecondPass.BusinessEntityID AND #FirstPass.AddressID = #SecondPass.AddressID AND #FirstPass.AddressTypeID = #SecondPass.AddressTypeID) UNION ALL SELECT * FROM #SecondPass WHERE NOT EXISTS (SELECT 1 FROM #FirstPass WHERE #FirstPass.BusinessEntityID = #SecondPass.BusinessEntityID AND #FirstPass.AddressID = #SecondPass.AddressID AND #FirstPass.AddressTypeID = #SecondPass.AddressTypeID)
As you can see while not overly difficult this does require a number of seperate queries. Also I put both versions of the different rows into the #DifferencesOnly temp table. You may or may not want to do that.
Filed under: Microsoft SQL Server, Problem Resolution, SQLServerPedia Syndication, T-SQL Tagged: problem resolution, T-SQL 






![]()
