

[read this post on Mr. Fox SQL blog]
Continuing on with my Partitioning post series, this is part 7.
The partitioning includes several major components of work (and can be linked below);
- partitioning large existing non-partitioned tables
- measuring performance impacts of partitioned aligned indexes
- measuring performance impacts of DML triggers for enforcing partitioned unique indexes
- rebuilding tables that are already partitioned (ie. apply a new partitioning scheme)
- implementing partial backups and restores (via leveraging partitions)
- implementing partition aware index optimisation procedures
- Calculating table partition sizes in advance
This blog post deals with calculating partitioning sizes in advance.
Sometimes (just sometimes) you need to calculate the size your table partitions upfront before you actually go to the pain and effort of partitioning (or repartition) a table. Doing this helps with pre-sizing the database files in advance instead of having them auto-grow many many times over in small increments as you cut data over into the partitions.
As a quick aside…
- The negative performance impacts of auto-shrink are universally well known (er, for DBA’s that is!), however I rarely hear people talk about the less universally well known negative performance impacts of auto-grow quite so much.
- Auto-Growing your database files in small increments can cause physical fragmentation in the database files on the storage subsystem and cause reduced IO performance. If you are interested you can read about this here https://support.microsoft.com/en-us/kb/315512
Now – back to what I was saying about pre-sizing table partitions…!
I prepared a SQL script which given some parameters can review an existing table and its indexes (whether they are already partitioned or not) and tell you what your partition sizing breakdown would be should that table be partitioned with a given partition function.
I wrote it just for what I needed but it could be expanded more if you are feeling energetic. The script is at the end of this post.
And so, lets get into the nitty gritty of this estimation script!
Some Key Points;
- It will output the table and index information and pre/post compressing sizing as it would be distributed against the desired partition function.
- It works with any table definition, any data type and any partition function – as long as they all meet the normal partitioning syntax.
- It uses the $PARTITION function to apply to the proposed partition coloumn, so it must read the actual real live table. It uses WITH (NOLOCK) to minimise impacts
- It uses the procedure sp_estimate_data_compression_savings to estimate compression reduction
- It assumes all NC indexes will be aligned to the future partition function and calculates them as such
- It doesent forcast future partition sizing based on historical sizing, it only works on data that is already present (ie if your data goes to 2015, but your function extends to 2017 then partitions between 2015-2017 will be calculated as 0KB size). That would be a nice feature (anyone want a challenge?) but its also easy to do it via Excel
- To give you a feeling of elapsed time, I have run this on a 656GB / 2.1b row table which took 3 hours on a 4 core 32GB SQL 2014 virtual box.
The Parameters;
- @PartitionTableName = name of the schema.table to review
- @PartitionKeyName = name of the coloumn on the table on which to partition
- @PartitionFunctionName = name of the partition function on which run the test. You must create the partition function in your database that you want to test, but you dont need to create the partition scheme
- @PartitionCompression = type of compression you want to apply; NONE / ROW / PAGE / NULL. If NULL then compression testing will be ignored
- @MaxDOP = Specify how many CPU’s you want to apply when running
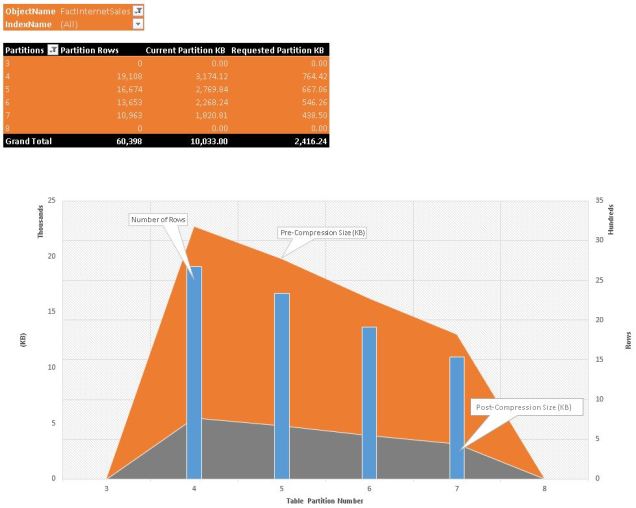
Pivot the Output Data in Excel;
Finally whats nice is that you can cut paste the result into Excel and PIVOT the data into some nice visualisations to show what your future partitioning scheme would look like. The example below is from sample tables in my other posts.
The Partition Distribution Estimation SQL Script
USE [AdventureWorksDW2014] GO -- Create the Desired Partition Function CREATE PARTITION FUNCTION pf_FactInternetSales (int) AS RANGE RIGHT FOR VALUES(0, 5000, 10000, 15000, 20000, 25000, 30000, 35000) GO -- Execute the Partition Distribution Procedure /*================================================================================ TITLE: Table Partition Distribution Estimator -------------------------------------------------------------------------------- HISTORY: -------------------------------------------------------------------------------- Date: Developer: Description: -------------------------------------------------------------------------------- 2015-05-10 Mr. Fox SQL (Rolf Tesmer) Created -------------------------------------------------------------------------------- NOTES: -------------------------------------------------------------------------------- Disclaimer: https://mrfoxsql.wordpress.com/notes-and-disclaimers/ ================================================================================*/ BEGIN SET nocount ON -- ******************************************************************************** -- Declare user variables DECLARE @PartitionTableName SYSNAME = 'dbo.FactInternetSales' -- The name of the table in format SCHEMA.OBJECT , @PartitionKeyName SYSNAME = 'CustomerKey' -- The name of the table key partitioning coloumn on which to partition the table / indexes , @PartitionFunctionName SYSNAME = 'pf_FactInternetSales' -- The name of the partition function on which to test the partitioning , @PartitionCompression SYSNAME = 'PAGE' -- The type of compression; NONE / ROW / PAGE / NULL. If NULL then compression testing will be ignored , @MaxDOP INT = 0 -- Use all processors -- ******************************************************************************** print 'Stage 0: Preparing Procedure. [' + convert(varchar(25), getdate(), 121) + ']' -- Declare system variables DECLARE @ObjectSchemaName SYSNAME , @ObjectID INT , @ObjectName SYSNAME , @FullSQLString NVARCHAR(4000) = '' , @IndexMBSize BIGINT , @TableMBSize BIGINT , @TableRows BIGINT -- drop temp tables IF EXISTS (SELECT 1 FROM tempdb.sys.objects WITH (NOLOCK) WHERE NAME LIKE '#TableData%') DROP TABLE #TableData IF EXISTS (SELECT 1 FROM tempdb.sys.objects WITH (NOLOCK) WHERE NAME LIKE '##RangeRows%') DROP TABLE ##RangeRows IF EXISTS (SELECT 1 FROM tempdb.sys.objects WITH (NOLOCK) WHERE NAME LIKE '#CompressionSavings%') DROP TABLE #CompressionSavings -- create work tables CREATE TABLE #CompressionSavings ( ObjectName SYSNAME NOT NULL , SchemaName SYSNAME NOT NULL , IndexID INT NOT NULL , PartitionNumber INT NOT NULL , size_with_current_compression_setting BIGINT NOT NULL , size_with_requested_compression_setting BIGINT NOT NULL , sample_size_with_current_compression_setting BIGINT NOT NULL , sample_size_with_requested_compression_setting BIGINT NOT NULL ) -- set variables SET @ObjectSchemaName = OBJECT_SCHEMA_NAME(OBJECT_ID(@PartitionTableName)) SET @ObjectName = OBJECT_NAME(OBJECT_ID(@PartitionTableName)) SET @ObjectID = OBJECT_ID(@PartitionTableName) -- get compression data for table if (@PartitionCompression is not NULL) begin print 'Stage 1: Gathering Compression Settings for Table. [' + convert(varchar(25), getdate(), 121) + ']' INSERT INTO #CompressionSavings ( ObjectName , SchemaName , IndexID , PartitionNumber , size_with_current_compression_setting , size_with_requested_compression_setting , sample_size_with_current_compression_setting , sample_size_with_requested_compression_setting ) EXECUTE dbo.SP_ESTIMATE_DATA_COMPRESSION_SAVINGS @schema_name = @ObjectSchemaName , @object_name = @ObjectName , @index_id = NULL , @partition_number = NULL , @data_compression = @PartitionCompression end -- Get existing data for table and indexes print 'Stage 2: Gathering Index Settings for Table. [' + convert(varchar(25), getdate(), 121) + ']' SELECT DISTINCT s.NAME AS 'schema' , o.NAME AS 'table' , CASE o.type WHEN 'v' THEN 'View' WHEN 'u' THEN 'Table' ELSE o.type END AS objecttype , i.object_id , i.NAME AS indexname , i.index_id AS IndexID , i.type , i.type_desc , p.data_compression_desc AS current_data_compression_desc , @PartitionCompression AS requested_data_compression_desc , i.is_unique , i.ignore_dup_key , i.is_primary_key , i.is_unique_constraint , i.fill_factor , i.is_padded , i.is_disabled , i.is_hypothetical , i.allow_row_locks , i.allow_page_locks , i.has_filter , pst.row_count , pst.CurrentKB , comp.CompressedKB INTO #TableData FROM sys.indexes i INNER JOIN sys.objects o ON o.object_id = i.object_id INNER JOIN sys.schemas s ON o.schema_id = s.schema_id INNER JOIN sys.partitions p ON i.object_id = p.object_id AND i.index_id = p.index_id INNER JOIN (SELECT object_id , index_id , SUM(row_count) AS row_count , CAST((SUM(used_page_count) * 8.0) AS NUMERIC(18, 2)) AS CurrentKB FROM sys.dm_db_partition_stats GROUP BY object_id , index_id) AS pst ON i.index_id = pst.index_id AND i.object_id = pst.object_id LEFT JOIN (SELECT @ObjectID AS object_id , IndexID AS index_id , SUM(size_with_requested_compression_setting) AS CompressedKB FROM #CompressionSavings GROUP BY IndexID) AS comp ON i.index_id = comp.index_id AND i.object_id = comp.object_id WHERE s.NAME = @ObjectSchemaName AND o.NAME = @ObjectName ORDER BY s.NAME , o.NAME , i.NAME -- distribute REAL table row counts by the partition function print 'Stage 3: Gathering Repartitioning Statistics for Table. [' + convert(varchar(25), getdate(), 121) + ']' SET @FullSQLString = '' SELECT @FullSQLString = ' SELECT p.boundary_id AS PartitionNumber , COUNT(o.' + @PartitionKeyName + ') AS RangeRows , CAST(0 AS NUMERIC(7, 4)) AS RangePct , RangeDesc INTO ##RangeRows FROM ' + @PartitionTableName + ' o WITH (NOLOCK) RIGHT JOIN ( SELECT pf.boundary_id , ISNULL(CAST(l_prv.value AS VARCHAR(MAX)) + CASE WHEN pf.boundary_value_on_right = 0 THEN '' < '' ELSE '' <= '' END , ''- '' + CHAR(236) + '' < '') + ''X'' + ISNULL ( CASE WHEN pf.boundary_value_on_right = 0 THEN '' <= '' ELSE '' < '' END + CAST(r_prv.value AS NVARCHAR(MAX)), '' < '' + CHAR(236)) AS RangeDesc FROM ( SELECT pf.function_id , boundary_id , boundary_value_on_right , value FROM sys.partition_range_values prv INNER JOIN sys.partition_functions pf ON prv.function_id = pf.function_id WHERE pf.NAME = ''' + @PartitionFunctionName + ''' UNION ALL SELECT MAX(pf.function_id) , MAX(boundary_id) + 1 , MAX(CAST(boundary_value_on_right AS INT)) , NULL FROM sys.partition_range_values prv INNER JOIN sys.partition_functions pf ON prv.function_id = pf.function_id WHERE pf.NAME = ''' + @PartitionFunctionName + ''' ) pf LEFT JOIN sys.partition_range_values r_prv ON r_prv.function_id = pf.function_id AND r_prv.boundary_id = pf.boundary_id LEFT JOIN sys.partition_range_values l_prv ON l_prv.function_id = pf.function_id AND l_prv.boundary_id + 1 = pf.boundary_id ) AS p ON p.boundary_id = $PARTITION.' + @PartitionFunctionName + '(o.' + @PartitionKeyName + ') GROUP BY p.boundary_id, RangeDesc ORDER BY PartitionNumber OPTION (MAXDOP ' + cast(@MaxDOP as varchar(3)) + ');' --PRINT @FullSQLString EXECUTE dbo.SP_EXECUTESQL @FullSQLString -- update Range PCT with overall rows pct allocation print 'Stage 4: Calculating Partition Data Distributions for Table. [' + convert(varchar(25), getdate(), 121) + ']' SELECT @TableRows = SUM(row_count) FROM #TableData WHERE type IN (0, 1) -- HEAP or CLUSTER IF (@TableRows IS NULL OR @TableRows = 0) SET @TableRows = 1 UPDATE ##RangeRows SET RangePct = CAST(RangeRows AS NUMERIC(23, 4)) / CAST(@TableRows AS NUMERIC(23, 4)) -- Return table and index breakdowns based on the pct allocation print 'Stage 5: Returning Final Repartitioning Information for Table. [' + convert(varchar(25), getdate(), 121) + ']' SELECT @ObjectSchemaName AS SchemaName , @ObjectName AS ObjectName , td.indexname AS IndexName , td.type_desc AS IndexTypeDesc , rr.PartitionNumber , rr.RangePct AS PartitionRangePct , rr.RangeDesc AS PartitionRangeDesc , rr.RangeRows AS PartitionRangeRows , td.current_data_compression_desc AS CurrentCompressionTypeDesc , (rr.RangePct * td.CurrentKB) AS CurrentPartitionRangeKB , td.requested_data_compression_desc AS RequestedCompressionTypeDesc , (rr.RangePct * td.CompressedKB) AS RequestedPartitionRangeKB FROM ##RangeRows rr CROSS JOIN #TableData td ORDER BY SchemaName , ObjectName , IndexName , partitionnumber END GO
Disclaimer: all content on Mr. Fox SQL blog is subject to the disclaimer found here
