

Microsoft’s Azure Databricks is an advanced Apache Spark platform that brings data and business teams together. In this introductory article, we will look at what the use cases for Azure Databricks are, and how it really manages to bring technology and business teams together.
Databricks
Before we delve deeper into Databricks, it is good to have a general understanding of Apache Spark.
Apache Spark is an open-source, unified analytics engine for big data processing, maintained by the Apache Software Foundation. Spark and its RDDs were developed in 2012 in response to limitations of MapReduce.
Key factors that make Spark ideal for big data processing are:
- Speed – up to 100X faster
- Ease of use – code in Java, Scala, Python, R and SQL
- Generality – use SQL, streaming and complex analytics

Databricks – the company – was founded by creators of Apache Spark. Databricks provides a web-based platform for working with Spark, with automated cluster management and IPython-style notebooks. It is aimed at unifying data science and engineering across the Machine Learning (ML) life cycle from data preparation, to experimentation and deployment of ML applications. Databricks, by virtue of its big data processing capabilities, also facilitates big data analytics. Databricks, as the name implies, thus lets you build solutions using bricks of data.
Azure Databricks
Azure Databricks combines Databricks and Azure to allow easy set up of streamlined workflows and an interactive work space that lets data teams and business collaborate. If you’ve been following data products on Azure, you’d be nodding your head along, imagining where Microsoft is going with this 
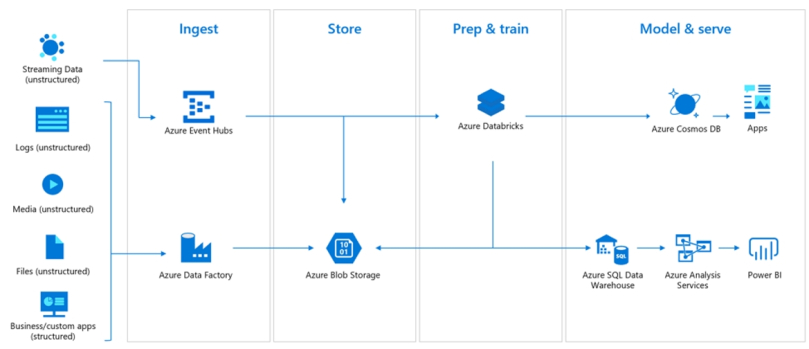
Azure Databricks enables integration across a variety of Azure data stores and services such as Azure SQL Data Warehouse, Azure Cosmos DB, Azure Data Lake Store, Azure Blob storage, and Azure Event Hub. Add rich integration with Power BI, and you have a complete solution.
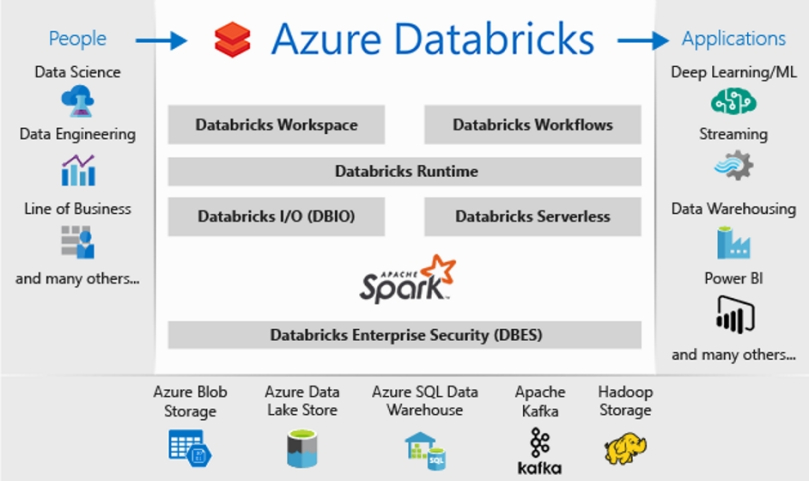
Why use Azure Databricks?
By now, we understand that Azure Databricks is an Apache Spark-based analytics platform that has big data processing capabilities and brings data and business teams together. How exactly does it do that, and why would someone use Azure Databricks?
- Fully managed Apache Spark clusters: With the serverless option, create clusters easily without having to set up your own data infrastructure. Dynamically auto-scale clusters up and down, and auto-terminate inactive clusters after a predefined period of inactivity. Share clusters with your teams, reduce time spent on infrastructure management and improve iteration time.
- Interactive workspace: Streamline data processing using secure workspaces, assign relevant permissions to different teams. Mix languages within a notebook – use your favorite out of R, Python, Scala and SQL. Explore, model and execute data-driven applications by letting Data Engineers prepare and load data, Data Scientists build models, and business teams analyze results. Visualize data in a few clicks using familiar tools like Matplotlib, ggplot or take advantage of the rich integration with Power BI.
- Enterprise security: Use SSO through Azure Active Directory integration to run complete Azure-based solutions. Roles-based access control enables fine-grained user permissions for notebooks, clusters, jobs, and data.
- Schedule notebook execution: Build, train and deploy AI models at scale using GPU-enabled clusters. Schedule notebooks as jobs, using runtime for ML that comes preinstalled and preconfigured with deep learning frameworks and libraries such as TensorFlow and Keras. Monitor job performance and stay on top of your game.
- Scale seamlessly: Target any amount of data or any project size using a comprehensive set of analytics technologies including SQL, Streaming, MLlib and GraphX. Configure number of threads, select number of cores and enable autoscaling to dynamically scale processing capabilities leveraging a Spark engine that is faster and performant through various optimizations at the I/O layer and processing layer (Databricks I/O).
Of course, all of this comes at a price. If this article has piqued your interest, hop over to Azure Databricks homepage and avail the 14 day free trial!
Suggested learning path:
- Read more about Azure Databricks – https://docs.microsoft.com/en-us/azure/azure-databricks/what-is-azure-databricks
- Create a Spark cluster and run a Spark job on Azure Databricks – https://docs.microsoft.com/en-us/azure/azure-databricks/quickstart-create-databricks-workspace-portal#clean-up-resources
- ETL using Azure Databricks – https://docs.microsoft.com/en-us/azure/azure-databricks/databricks-extract-load-sql-data-warehouse
- Stream data into Azure Databricks using Event Hubs – https://docs.microsoft.com/en-us/azure/azure-databricks/databricks-stream-from-eventhubs
- Sentiment analysis on streaming data using Azure Databricks – https://docs.microsoft.com/en-us/azure/azure-databricks/databricks-sentiment-analysis-cognitive-services
I hope you found the article useful. Share your learning experience with me. My next article will be on Real-time analytics using Azure Databricks.
Resources:
https://azure.microsoft.com/en-au/services/databricks/
https://databricks.com/product/azure
https://docs.microsoft.com/en-us/azure/azure-databricks/what-is-azure-databricks
https://docs.microsoft.com/en-us/azure/azure-databricks/quickstart-create-databricks-workspace-portal#clean-up-resources
https://databricks.com/blog/2019/02/07/high-performance-modern-data-warehousing-with-azure-databricks-and-azure-sql-dw.html
