

As I was testing whether or not the new “Variation Selector Sensitive” ( _VSS ) Collations in SQL Server 2017 would assist in the following question on DBA.StackExchange:
SELECT query: filter unable to distinguish between two different characters
I ran into what initially looked to be an unfortunate situation. I wanted to see the full list of newly added Collations, so I ran the following query:
SELECT col.[name] FROM sys.fn_helpcollations() col WHERE col.[name] LIKE N'%[_]140[_]%';
That query returns the following list of 68 Collations:
Japanese_Bushu_Kakusu_140_BIN Japanese_Bushu_Kakusu_140_BIN2 Japanese_Bushu_Kakusu_140_CI_AI Japanese_Bushu_Kakusu_140_CI_AI_KS Japanese_Bushu_Kakusu_140_CI_AI_KS_VSS Japanese_Bushu_Kakusu_140_CI_AI_KS_WS Japanese_Bushu_Kakusu_140_CI_AI_KS_WS_VSS Japanese_Bushu_Kakusu_140_CI_AI_VSS Japanese_Bushu_Kakusu_140_CI_AI_WS Japanese_Bushu_Kakusu_140_CI_AI_WS_VSS Japanese_Bushu_Kakusu_140_CI_AS Japanese_Bushu_Kakusu_140_CI_AS_KS Japanese_Bushu_Kakusu_140_CI_AS_KS_VSS Japanese_Bushu_Kakusu_140_CI_AS_KS_WS Japanese_Bushu_Kakusu_140_CI_AS_KS_WS_VSS Japanese_Bushu_Kakusu_140_CI_AS_VSS Japanese_Bushu_Kakusu_140_CI_AS_WS Japanese_Bushu_Kakusu_140_CI_AS_WS_VSS Japanese_Bushu_Kakusu_140_CS_AI Japanese_Bushu_Kakusu_140_CS_AI_KS Japanese_Bushu_Kakusu_140_CS_AI_KS_VSS Japanese_Bushu_Kakusu_140_CS_AI_KS_WS Japanese_Bushu_Kakusu_140_CS_AI_KS_WS_VSS Japanese_Bushu_Kakusu_140_CS_AI_VSS Japanese_Bushu_Kakusu_140_CS_AI_WS Japanese_Bushu_Kakusu_140_CS_AI_WS_VSS Japanese_Bushu_Kakusu_140_CS_AS Japanese_Bushu_Kakusu_140_CS_AS_KS Japanese_Bushu_Kakusu_140_CS_AS_KS_VSS Japanese_Bushu_Kakusu_140_CS_AS_KS_WS Japanese_Bushu_Kakusu_140_CS_AS_KS_WS_VSS Japanese_Bushu_Kakusu_140_CS_AS_VSS Japanese_Bushu_Kakusu_140_CS_AS_WS Japanese_Bushu_Kakusu_140_CS_AS_WS_VSS Japanese_XJIS_140_BIN Japanese_XJIS_140_BIN2 Japanese_XJIS_140_CI_AI Japanese_XJIS_140_CI_AI_KS Japanese_XJIS_140_CI_AI_KS_VSS Japanese_XJIS_140_CI_AI_KS_WS Japanese_XJIS_140_CI_AI_KS_WS_VSS Japanese_XJIS_140_CI_AI_VSS Japanese_XJIS_140_CI_AI_WS Japanese_XJIS_140_CI_AI_WS_VSS Japanese_XJIS_140_CI_AS Japanese_XJIS_140_CI_AS_KS Japanese_XJIS_140_CI_AS_KS_VSS Japanese_XJIS_140_CI_AS_KS_WS Japanese_XJIS_140_CI_AS_KS_WS_VSS Japanese_XJIS_140_CI_AS_VSS Japanese_XJIS_140_CI_AS_WS Japanese_XJIS_140_CI_AS_WS_VSS Japanese_XJIS_140_CS_AI Japanese_XJIS_140_CS_AI_KS Japanese_XJIS_140_CS_AI_KS_VSS Japanese_XJIS_140_CS_AI_KS_WS Japanese_XJIS_140_CS_AI_KS_WS_VSS Japanese_XJIS_140_CS_AI_VSS Japanese_XJIS_140_CS_AI_WS Japanese_XJIS_140_CS_AI_WS_VSS Japanese_XJIS_140_CS_AS Japanese_XJIS_140_CS_AS_KS Japanese_XJIS_140_CS_AS_KS_VSS Japanese_XJIS_140_CS_AS_KS_WS Japanese_XJIS_140_CS_AS_KS_WS_VSS Japanese_XJIS_140_CS_AS_VSS Japanese_XJIS_140_CS_AS_WS Japanese_XJIS_140_CS_AS_WS_VSS
As you scroll through the list, does anything appear to be missing? Go ahead, take another look. I’ll wait ?? . Figure it out? Yep, that’s right: none of those Collations end in “_SC“. Collations ending in “_SC” were added in SQL Server 2012 and support the full UTF-16 character set. Without the “_SC” ending, built-in functions and comparisons / sorting only fully support the base UCS-2 character set (i.e. the first 65,536 Unicode Code Points). You can, of course, store and view all Unicode Code Points, even Supplementary Characters, in non-“_SC” Collations, but they will be interpreted as being two separate “unknown” characters instead of as being one single character.
Test 1
To illustrate this point, the following query shows: the two surrogate Code Points (not actual characters by themselves, but when used in pairs of any of the assigned combinations, produce a single character), the resulting Supplementary Character, and how the LEN function interprets that sequence in both non-“_S” and “_SC” Collations.
SELECT NCHAR(0xD83D) AS [HighSurrogate],
NCHAR(0xDC31) AS [LowSurrogate],
NCHAR(0xD83D) + NCHAR(0xDC31) AS [Supplementary
ͨ ͪ ͣ ͬ ͣ ͨ ͭ ͤ ͬ],
LEN(NCHAR(0xD83D) + NCHAR(0xDC31)
COLLATE Latin1_General_100_CI_AS) AS [Non-SC-Aware],
LEN(NCHAR(0xD83D) + NCHAR(0xDC31)
COLLATE Latin1_General_100_CI_AS_SC) AS [SC-Aware];
As you can see below, the individual surrogate Code Points display as the question mark in a dark diamond, yet combined they display as the “Cat Face” emoji ( U+1F431 ): 🐱. You can also see that a non-“_SC” Collation counts the Surrogate Pair as 2 characters instead of 1 like the “_SC” Collation does.

Test 2
With that in mind, I created the following query to test each Collation that is neither a SQL Server Collation nor one of the “_SC” Collations:
DECLARE @SQL NVARCHAR(MAX) = N'';
SELECT @SQL += N'IF (LEN(NCHAR(0xD83D) + NCHAR(0xDC31) COLLATE '
+ col.[name] + N') = 1) PRINT ''' + col.[name] + N''';'
+ NCHAR(0x000D) + NCHAR(0x000A)
FROM sys.fn_helpcollations() col
WHERE col.[name] NOT LIKE N'SQL[_]%'
AND col.[name] NOT LIKE N'%[_]SC'
--EXEC SQL#.Util_Print @SQL
EXEC (@SQL);
That query concatenates each Collation name into an IF statement that prints the name of the Collation only if the LEN function returns “1” when supplied the “cat face” character. The first three generated lines are:
IF (LEN(NCHAR(0xD83D) + NCHAR(0xDC31) COLLATE Albanian_BIN) = 1) PRINT 'Albanian_BIN'; IF (LEN(NCHAR(0xD83D) + NCHAR(0xDC31) COLLATE Albanian_BIN2) = 1) PRINT 'Albanian_BIN2'; IF (LEN(NCHAR(0xD83D) + NCHAR(0xDC31) COLLATE Albanian_CI_AI) = 1) PRINT 'Albanian_CI_AI'; ...
The results of that query (the one that produced all of those IF statements) were 64 out of the 68 new Collations. The only Collations not returned were the four binary Collations (ending in either “_BIN” or “_BIN2“), and they weren’t expected to return since they, by their very nature, do not support Supplementary Characters.
Test 3
As a final test, we can make use of the fact that the old, deprecated (meaning: do not use!) datatypes of TEXT and NTEXT do not support Supplementary Characters. What does “support” mean? Non-Supplementary Character Aware Collations merely do not see the Surrogate Pair as a single Code Point, and that is mostly an issue for just the built-in functions. But, you could still store and retrieve Supplementary Characters without any issues.
With these two deprecated datatypes (again, you should not be using them if you are using SQL Server 2005 or newer), you aren’t allowed to use Supplementary Character Aware Collations. Attempting to do so will result in an error. Executing the following:
CREATE TABLE #Test_SC (Col1 NTEXT COLLATE Latin1_General_100_CI_AS_SC);
returns:
Msg 4188, Level 16, State 1, Line XXXXX
Column or parameter ‘Col1’ has type ‘ntext’ and collation ‘Latin1_General_100_CI_AS_SC’.
The legacy LOB types do not support Unicode supplementary characters whose codepoints are U+10000 or greater. Change the column or parameter type to varchar(max), nvarchar(max) or use a collation which does not have the _SC flag.
Can we use the new Japanese Collations with the old LOB datatypes? They don’t have the “_SC” flag, which is what the error says we need to avoid. Let’s try:
CREATE TABLE #Test_SC (Col1 NTEXT COLLATE Japanese_XJIS_140_CI_AS);
returns:
Msg 4188, Level 16, State 1, Line XXXXX
Column or parameter ‘Col1’ has type ‘ntext’ and collation ‘Japanese_XJIS_140_CI_AS’.
The legacy LOB types do not support Unicode supplementary characters whose codepoints are U+10000 or greater. Change the column or parameter type to varchar(max), nvarchar(max) or use a collation which does not have the _SC flag.
The error clearly states that SQL Server considers this Collation, even without the “_SC” flag in the name, to be Supplementary Character Aware. It also appears that the error message needs to be updated ?? .
Additional Evidence
I also noticed something interesting when reviewing the available Windows Collations when installing SQL Server 2017. If you select the “Windows” Collations radio-button, and then select one of the new, non-binary “Japanese_*_140” Collations, the lower-left check-box for “Supplementary Characters” will be checked and disabled (i.e. greyed-out / read-only) as shown below:
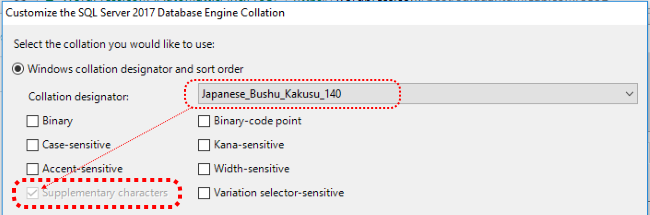
While this alone is not as conclusive as the actual behavior of the Collations as shown in the three tests above, it’s nice to see that it is consistent with the findings of those three tests.
Conclusion
While there is no mention of this behavior either on the Collation and Unicode Support page (under “Supplementary Characters” or “Japanese Collations added in SQL Server 2017”) or even the What’s new in Database Engine – SQL Server 2017 page, it appears that Microsoft is taking the approach that all new Collations inherently support Supplementary Characters. This is actually very much appreciated as there is no reason to ever not support Supplementary Characters. It just would have been nice to have had that noted somewhere in the official documentation.
I suppose I can submit an edit for the “Collation and Unicode Support” page.
UPDATE (2017-11-06)
As of 2017-10-31, edits that I submitted via Pull Request (PR) #175 to correct the two documentation pages noted above (in the Conclusion) have been merged into the main branch and are viewable to the public. If you want to see the specific changes I made to each page, click on the link for the PR and then go to the “Files changed” tab.
