

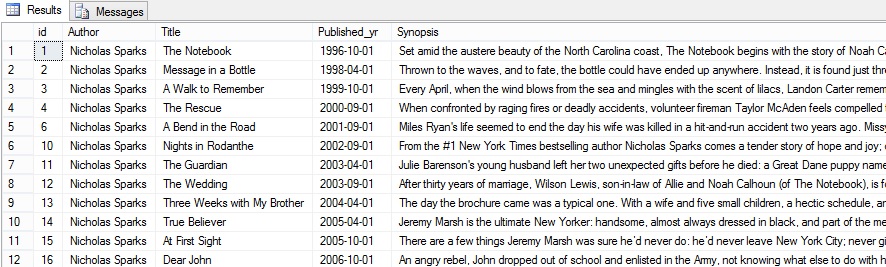
However consider the scenario where I wish to check if Jeremy is one of the characters in the books based on the synopsis given. My query would look something like this
Full-Text Terminologies
A special token-based index built and maintained by the Full Text Engine for SQL server. It is used to track occurrences of words or word-forms in columns containing unstructured text. Full-Text index structures are different from normal B-tree index structures. It’s an inverted, stacked, compressed index structure based on individual tokens from the text being indexed. Only one Full-Text index can be created per table. It does require a unique key to be set for each row for the given table. It helps to keep this key as small as possible. This could be a primary key. This structure is elaborated in the following link
https://technet.microsoft.com/en-us/library/ms142505(v=sql.105).aspx
It’s a logical container for Full-Text indexes. A database can have one or more full-text catalogs. The indexes are aggregated as a collection in terms of catalog purely for administration and maintenance purpose. It is used to set common property values for all the indexes it stores.
4) Word Breakers
5) StopWords and StopList
https://technet.microsoft.com/en-us/library/ms142551(v=sql.105).aspx
C) Incremental Timestamp-Based Population - This requires that the indexed table has a column of timestamp data type. If such a column does not exists SQL server will treat it as a full population operation. If the column exists SQL Server will update the modified rows based on the value of the time-stamped column.
https://technet.microsoft.com/en-us/library/ms142575(v=sql.105).aspx
7) Thesaurus
Thesaurus comprises of synonyms or word expansions for any given word. Each language has its own set of defined synonyms. This is an XML file stored in file system. This broadens our search criteria to find similar words at querying time.
<SQL_Server_data_files_path>\<VersionSpecificInstance>\MSSQL\FTDATA\
C:\Program Files\Microsoft SQL Server\MSSQL11.MSSQLSERVER\MSSQL\FTData
Beginning in SQL Server 2008, full-text search supports more than 50 diverse languages, such as English, Spanish, Chinese, Japanese, Arabic, Bengali, and Hindi. Once can check the list of supported full-text languages using the following query
Full-Text Index Architecture
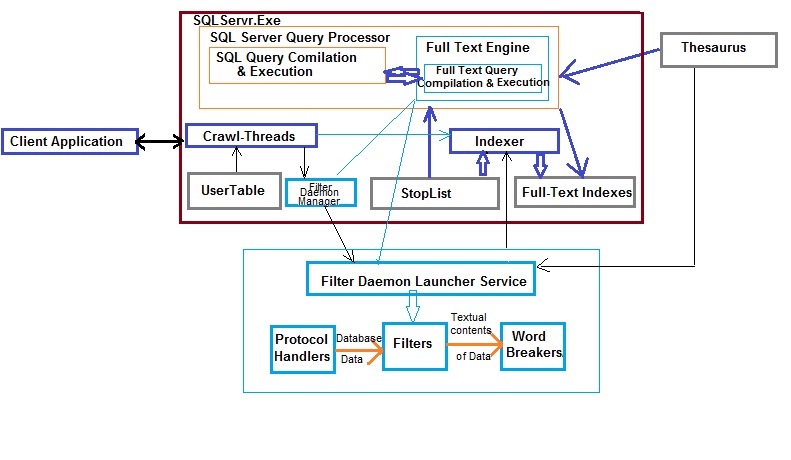
2) Query is passed to the SQL server engine comprising of SQL Server Query Processor and Full-Text Engine along with various other components
3) The Full-Text searches are sent to Full-Text Engine during both the stage Compilation and Execution. SQL Server Query Processor is responsible for parsing, binding, optimization and execution.The Full-Text Engine receives the Full-Text part of the queries from the query processor. It works in conjunction with the SQL server query processor.
4) In order to full the requests a Full-Text engine calls for the Indexer. The indexer is responsible for evaluating the StopList and populating Full-Text Indexes which form a part of the database from SQL server 2008 onwards. Prior to this they were stored separately on file systems. StopList will also contain stopwords which are ignored during query evaluation.
5) Thesaurus is used during Full-Text query compilation and execution. Its external to the SQL server database. This file is also used by the Filer Daemon Launcher Service which is again external to the SQLservr.Exe
6) Filter Daemon Manager is responsible for monitoring the Filer Daemon Launcher Service or Host Service.Its external to the SQL Server Engine.Inside SQL server engine the user tables are evaluated during full-text index population or crawl process by the indexer. This data is also used by the Filter Daemon Manager process which passes this information to the Host Service.
7) The Filter Daemon Host is responsible for accessing, filtering, and word breaking data from tables, as well as for word breaking and stemming the query input: It comprises of
a) The protocol handler which is responsible for pulling SQL server data from memory and passing the database data to the filter.
c)The word-breakers delimit the result-set. These word-breakers are also passed to the indexer by the Filter Daemon Launcher Service. Just like the stoplist the word-breaker are ignored
- Tokenized daata from full-text crawl threads
- Delimited result-set from the Filter Daemon Host Service
- Stop-list words that are to be excluded
9) During the querying process the Full-Text Engine uses the full-text indexes generated by the indexer. The word-breakers and thesaurus are first referenced to generate all forms of query predicate. The query processor then looks-up for all these forms in the full-text indexes. The Full-Text Engine is also responsible for the optimization process much like a standard query optimization process to retrieve the data.
10) The SQL query execution results and Full-Text query execution results are combined and the final result-set is sent across the client.
