


Advent of Code 2018 – Day 2
As I explained in yesterday’s post, I’m participating in this year’s Advent of Code challenge, with the twist of doing the challenges in T-SQL. In case you don’t know what “Advent of Code” is, Eric Wastl (t) created it for the purpose of, as Eric describes it:
Advent of Code is a series of small programming puzzles for a variety of skill levels. They are self-contained and are just as appropriate for an expert who wants to stay sharp as they are for a beginner who is just learning to code. Each puzzle calls upon different skills and has two parts that build on a theme.
The full explanation of “Advent of Code” is at https://adventofcode.com/2018/about. You can see my other posts in the “Advent of Code” category.
2018 Advent of Code recap
We started of with someone going back in time and altering Santa’s past. You went back in time to correct it, but the device to fix the problems hadn’t been calibrated before sending you on your way. You calibrated the device on Day 1.
Day 2, Part 1 – Loading the file
Today, you made it to your first destination. You overhear workers talking about workers have lost everything for a new prototype Santa suit. You overhear that the fabric would be in the warehouse, in two boxes with similar Box IDs. So you sneak into the warehouse and scan all the likely Box IDs. This list becomes your input file for Day 2, and it looks like this:

Day 2 Input File
Your first task is to create a checksum to compare against the scanning device. For each Box ID, you need to determine if there are any letters that repeat exactly twice in that Box ID, and if there are any that repeat exactly 3 times. Your checksum for the file is the number of times a Box ID has two letters repeated, times the number of times that a Box ID has three letters repeated. For both of these conditions, you are only concerned with whether this pattern occurs in that specific Box ID, not the number of times that it occurs.
Analyzing this, you will need to split each line apart into separate rows for each letter, count the number of times that each letter occurs, and then determine if there are any letters that occur exactly two or three times in that string. Finally, sum up those values for all of the rows, and multiply the values together.
The first thing to do is to load the file and split it apart into a separate row for each box ID. We will split the Box ID apart letter by letter, and then put it back together. Additionally, we will store a unique number for each Box ID, and the length of that Box ID. The code for accomplishing this is:
SELECT ca1.ItemNumber,
ca2.Item,
LEN(ca2.Item) AS DataSize
FROM OPENROWSET(BULK 'D:\AdventOfCode\2018\Input\Day02.txt', SINGLE_CLOB) dt(FileData)
CROSS APPLY dbo.Split(dt.FileData, CHAR(13)) ca1
CROSS APPLY (VALUES(REPLACE(ca1.Item, CHAR(10), ''))) ca2(Item);The results of this query look like:
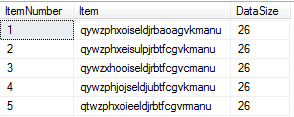
File Load
Day 2, Part 1 – Counting letters per Box ID
Next, we need to split each Box ID into the separate letters. A “Tally Table” (a table of sequential numbers starting with 1), and the SUBSTRING function to get each letter will do this. This part of the code is:
WITH Tens (N) AS (SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1),
Hundreds(N) AS (SELECT 1 FROM Tens t1, Tens t2),
Millions(N) AS (SELECT 1 FROM Hundreds t1, Hundreds t2, Hundreds t3),
Tally (N) AS (SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM Millions),
cte1 AS
(
SELECT ca1.ItemNumber,
ca2.Item,
LEN(ca2.Item) AS DataSize
FROM OPENROWSET(BULK 'D:\AdventOfCode\2018\Input\Day02.txt', SINGLE_CLOB) dt(FileData)
CROSS APPLY dbo.Split(dt.FileData, CHAR(13)) ca1
CROSS APPLY (VALUES(REPLACE(ca1.Item, CHAR(10), ''))) ca2(Item)
), cte2 AS
(
-- get the letters for each row
SELECT cte1.ItemNumber,
cte1.Item,
SUBSTRING(cte1.Item, ca.N, 1) AS Ltr
FROM cte1
CROSS APPLY (SELECT TOP (DataSize) N FROM Tally ORDER BY N) ca
)
SELECT *
FROM cte2;The “Tens” Common Table Expression (CTE) creates ten rows of a digit. The “Hundreds” CTE just CROSS JOINs the “Tens” CTE together twice, created 100 rows. The “Millions” CTE CROSS JOINs the “Hundreds” CTE together three times, creating one million rows. The “Tally” CTE uses the ROW_NUMBER() function to assign a sequential number for each of those one million rows, starting with 1 and going to, you guessed it, 1 million.
The “cte1” CTE is the file load that we did earlier. In “cte2”, the “tally” CTE is essentially joined to the file load cte (“cte1”) for each row. The TOP (DataSize) limits the number of values returned, to get just the numbers from 1 to the number of characters. Then the SUBSTRING function gets one character at a time, starting with the first character and going through the last character.
This query has the following results:
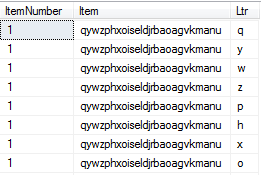
Extract Each Letter
Next we need to count each letter in each Box ID, and to pivot the results back into one row for each Box ID. The COUNT() function, with the GROUP BY clause, counts each letter by Box ID. The pivot utilizes the MAX function with an embedded CASE statement to determine if that Box ID has any occurrences of a letter occurring 2 or 3 times. This query is:
WITH Tens (N) AS (SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1),
Hundreds(N) AS (SELECT 1 FROM Tens t1, Tens t2),
Millions(N) AS (SELECT 1 FROM Hundreds t1, Hundreds t2, Hundreds t3),
Tally (N) AS (SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM Millions),
cte1 AS
(
SELECT ca1.ItemNumber, ca2.Item, LEN(ca2.Item) AS DataSize
FROMOPENROWSET(BULK 'D:\AdventOfCode\2018\Input\Day02.txt', SINGLE_CLOB) dt(FileData)
CROSS APPLY dbo.Split(dt.FileData, CHAR(13)) ca1
CROSS APPLY (VALUES(REPLACE(ca1.Item, CHAR(10), ''))) ca2(Item)
), cte2 AS
(
-- get the letters for each row
SELECT cte1.ItemNumber,
cte1.Item,
SUBSTRING(cte1.Item, ca.N, 1) AS Ltr
FROMcte1
CROSS APPLY (SELECT TOP (DataSize) N FROM Tally ORDER BY N) ca
), cte3 AS
(
-- count the letters in each row
SELECT ItemNumber, Ltr, COUNT(*) AS Counter
FROMcte2
GROUP BY ItemNumber, Ltr
--ORDER BY ItemNumber, COUNT(*) DESC
), cte4 AS
(
-- pivot these back into one row per ItemNumber,
-- with columns for whether it has 1 (or more) letter repeated 3 times,
-- and 1 (or more) letter repeated 2 times.
SELECTItemNumber,
MAX(CASE WHEN Counter = 3 THEN 1 ELSE 0 END) AS Has3,
MAX(CASE WHEN Counter = 2 THEN 1 ELSE 0 END) AS Has2
FROMcte3
GROUP BY ItemNumber
)
SELECT *
FROM cte4;The results of this query are:

Counting Letters
Day 2, Part 1 – Calculating the checksum
To calculate the checksum, we just need to add up the Has3 and Has2 columns, and then multiply those calculations against each other:
WITH Tens (N) AS (SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1),
Hundreds(N) AS (SELECT 1 FROM Tens t1, Tens t2),
Millions(N) AS (SELECT 1 FROM Hundreds t1, Hundreds t2, Hundreds t3),
Tally (N) AS (SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM Millions),
cte1 AS
(
SELECT ca1.ItemNumber,
ca2.Item,
LEN(ca2.Item) AS DataSize
FROM OPENROWSET(BULK 'D:\AdventOfCode\2018\Input\Day02.txt', SINGLE_CLOB) dt(FileData)
CROSS APPLY dbo.Split(dt.FileData, CHAR(13)) ca1
CROSS APPLY (VALUES(REPLACE(ca1.Item, CHAR(10), ''))) ca2(Item)
), cte2 AS
(
-- get the letters for each row
SELECT cte1.ItemNumber,
cte1.Item,
SUBSTRING(cte1.Item, ca.N, 1) AS Ltr
FROM cte1
CROSS APPLY (SELECT TOP (DataSize) N FROM Tally ORDER BY N) ca
), cte3 AS
(
-- count the letters in each row
SELECT ItemNumber,
Ltr,
COUNT(*) AS Counter
FROM cte2
GROUP BY ItemNumber, Ltr
), cte4 AS
(
-- pivot these back into one row per ItemNumber,
-- with columns for whether it has 1 (or more) letter repeated 3 times,
-- and 1 (or more) letter repeated 2 times.
SELECT ItemNumber,
MAX(CASE WHEN Counter = 3 THEN 1 ELSE 0 END) AS Has3,
MAX(CASE WHEN Counter = 2 THEN 1 ELSE 0 END) AS Has2
FROM cte3
GROUP BY ItemNumber
)
-- multiply these two numbers together to get the CheckSum
--SELECT SUM(Has3), SUM(Has2)
SELECT SUM(Has3) * SUM(Has2) AS CheckSum
FROM cte4;And this provides us with the Checksum. Part 2 unlocks after entering this value.
Day 2, Part 2 – Finding the correct boxes
To find the two boxes, we need to find two Box IDs with a similar ID. The definition of “similar” is that the Box ID values are the same except for one letter, and that letter is in the same position for both Box IDs. For this puzzle, we need to return the common letters of those two Box IDs.
To find the similar Box IDs, I create a row for each letter position of each Box ID. That row will have all of the letters before and after this position… all of the letters except for this position. Then I simply count the number of rows that have the same set of letters for that position. The code to accomplish this is very similar to the prior code above:
WITH Tens (N) AS (SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1),
Hundreds(N) AS (SELECT 1 FROM Tens t1, Tens t2),
Millions(N) AS (SELECT 1 FROM Hundreds t1, Hundreds t2, Hundreds t3),
Tally (N) AS (SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM Millions),
cte1 AS
(
SELECT ca1.ItemNumber, ca2.Item, LEN(ca2.Item) AS DataSize
FROM OPENROWSET(BULK 'D:\AdventOfCode\2018\Input\Day02.txt', SINGLE_CLOB) dt(FileData)
CROSS APPLY dbo.Split(dt.FileData, CHAR(13)) ca1
CROSS APPLY (VALUES(REPLACE(ca1.Item, CHAR(10), ''))) ca2(Item)
), cte2 AS
(
SELECT ca.N,
-- get the letters before "N"
CASE WHEN N > 1
THEN SUBSTRING(cte1.Item, 1, N-1)
ELSE ''
END +
-- get the letters after "N"
CASE WHEN N < cte1.DataSize
THEN SUBSTRING(cte1.Item, N+1, cte1.DataSize)
ELSE ''
END AS CommonLtrs
FROM cte1
-- for each row, just use the #s for the # of letters in that row
CROSS APPLY (SELECT TOP (DataSize) N FROM Tally ORDER BY N) ca
)
SELECT *
FROM cte2
GROUP BY N, CommonLtrs
HAVING COUNT(*) > 1;The “cte2” CTE gets the letter position and all letters before and after that position. The final SELECT does the grouping and returns the rows with common letters.
Summary
And here we have a T-SQL solution for Day 2 of the Advent of Code challenge. The key tasks that we can learn from today are:
- Loading a file.
- Split a string on a delimiter.
- Assigning a sequential number to a set of rows in a specific order.
- Construction of a virtual TALLY table.
- Using a TALLY table to extract each character from a string.
- PIVOTing data from rows to columns.
- Use of the GROUP BY and HAVING clauses while performing an aggregation.
The post Advent of Code 2018 – Day 2 (Inventory Management) appeared first on Wayne Sheffield.
