

When first learning SQL Server, I had the brilliant idea of defining every column on my table as VARCHAR(8000). After all, the VARCHAR datatype only consumes as much storage space as the string itself (plus two bytes), so even if I defined the max length of a column as 8000, I wouldn’t be wasting storage space if my data was smaller than that.
My development life would be easier too since I wouldn’t have to think about the kind of data I was storing in my columns; I could define everything as VARCHAR(8000) once and never have to go back to make any changes. Brilliant!
While I was correct about not wasting storage space, it turns out the idea of making every column VARCHAR(8000) is a terrible idea.
What follows is a (partial) list of reasons to avoid defining every column in your table as VARCHAR(8000).
1. Documentation
When columns are defined accurately with specific data types and lengths, they help provide understanding about the data they contain.
For example, imagine you see following column in a table:
ZipCode VARCHAR(10)If your database is full of U.S. data, this column definition provides enough information to make some pretty good assumptions:
- With a length of 10, we can expect some of the data to be in the 5 digit zip code + 4 digit extended zip code format (eg. 12345-6789)
- Choosing VARCHAR instead of CHAR means there are probably some entries that contain 5 digit zip codes and some with 5+4 digit zip codes (and a dash)
We can’t be 100% confident about our assumptions until we verify them by profiling the data itself, but a lot of times having decent guesses is good enough.
2. Validation
Your application (hopefully) has some good client and server side validation built in. Those validations don’t always work so it never hurts to have some extra validation on the database side of things as well.
Imagine the zip code field is directly next to the “Delivery Instructions” box on our app’s “Shipping Details” page. It’s not a stretch to think that a user will someday accidentally type in the special delivery instructions (“Please leave the package behind the house next to the giant pineapple bush”) into the zip code field instead of the instructions field.
If your ZipCode field is defined as VARCHAR(8000), that set of delivery instructions will make its way into the database in the completely wrong column.
Have fun cleaning up that dirty data. If instead the field was correctly defined as ZipCode VARCHAR(10), the insert would fail and you would prevent that erroneous data from entering your database.
3. Indexing
Ever try to index a column (or set of columns) that total more than 1700 bytes (or 900 bytes in older versions)?

SQL Server will let you create indexes that contain keys that may potentially be greater than 1700 bytes, but as soon as you try to insert large data into those indexes you will be greeted with this wall of error:

Of course there are some tricks you can use to index those wide key combinations, but you don’t want to use those unless you absolutely have to.
4. Inaccurate Estimates
Imagine we have 1000 rows of data in our table with a VARCHAR(8000) column:
CREATE TABLE #Varchar8000Test
(
Id int identity PRIMARY KEY,
BigColumn varchar(8000)
);
INSERT INTO #Varchar8000Test VALUES ('a');
GO 1000You’ll notice that each of those rows’ BigColumn fields only contain 3 bytes of data (1 for “a” + 2 for varchar overhead). That’s about 3 KB total for the whole table of data (plus whatever the int column takes up)
You would therefore think that SQL Server would know and use this information when executing a query :
SELECT * FROM #Varchar8000Test ORDER BY BigColumn
OPTION(MAXDOP 1)However it doesn’t:
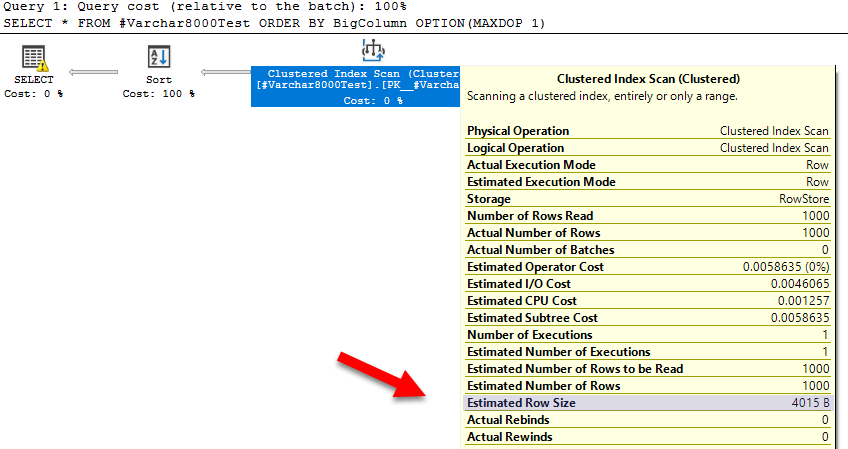
SQL Server estimates that each row is ~4 KB! This is because SQL Server doesn’t sample the data to estimate the average row size for VARCHAR columns, it uses half of the defined length.
This carries over to other parts of the query plan too, like memory grants:
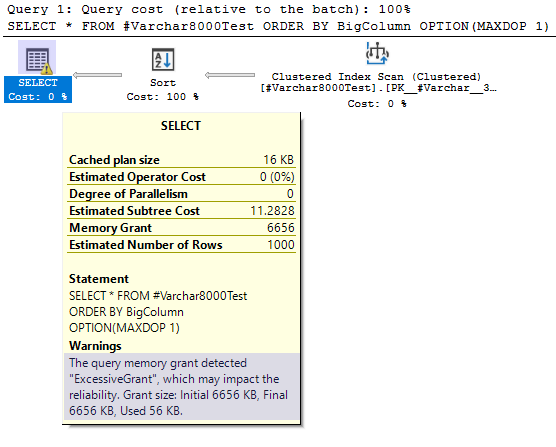
Fitting this whole table into memory should only take about ~7 KB (3 KB for our BigColumn data), but SQL Server reserves significantly more than that. In this example an excess of 6 MB isn’t a huge deal, but if you are working with a table with many more rows, those excessive memory grants can use up hundreds of megabytes or even gigabytes of memory unnecessarily.
…and more!
This list is only a start: there are plenty of additional reasons why defining every column on your table as VARCHAR(8000). My goal with this post wasn’t to create a comprehensive list, but rather to provide enough compelling reasons to have dissuaded my novice self a few years ago from even considering this as an option.
