

Introduction
XML . . . what a word it has been. Nobody imagined that a technology will break through all the frontiers and inject itself in all the fields with great success. XML has been the front runner for providing easy and secure mode for data transfer, data storage and data manipulation. All the major applications these days including various web groups are also going for XML. Blogs using RSS are the new trends these days which are provided by the websites. These are nothing but an extension to XML. (For more reading on RSS: http://www.codeproject.com/tips/RSS.asp)
How XML is used? Its rules or way of creating XML files is discussed, including the basic XPATH syntax, which is used to query XML files.
Why use XML?
- XML is a markup language much like HTML.
- Widely accepted and adopted standard.
- Independent of vendor, platform & applications.
- Many essential and emerging standards are based on XML.
- Designed to describe data and to focus on what data is.
- XML is free and extensible.
- Tags are not predefined. You have to define your own tags.
- Document Type Definition (DTD) or an XML Schema to describe the data.
- Multi-Script capable.
- Plain-text source files.
- Support for database interactions.
XML and HTML
- XML was designed to carry data.
- XML is not a replacement for HTML.
- XML was designed to describe data and to focus on what data is. HTML was designed to display data and to focus on how data looks.
- HTML is about displaying information, while XML is about describing information.
XML Document Object Model
The DOM provides a representation of a complete XML document stored in memory, providing random access to the contents of the entire document. The document itself is considered a single node that contains all of the other nodes, including a node representing the root element, which, in turn, contains all of the element, attribute, and text nodes in the document.
To be specific, DOM is:
- Designed to be language and platform independent.
- Consists of a set of interfaces.
- Documents are composed of Nodes.
- Nodes can be elements, attributes, comments, etc.
- Ordered and unordered collections are supported.
- Parsing documents not included.
Consider the sample XML file (Sample.xml)
<?XML version="1.0" ENCODING="ISO-8859-1"?>
<ARTICLES>
<ARTICLE ID=‘AAA01’>
<TITLE>Test XML</TITLE>
<DATE>14th May, 2005</DATE>
<AUTHOR>
<FNAME>Vasant</FNAME>
<LNAME>Raj</LNAME>
</AUTHOR>
<SUMMARY>XML is pretty easy. </SUMMARY>
<CONTENT>XML is simple.</CONTENT>
</ARTICLE>
</ARTICLES>
The DOM structure for the individual ARTICLE element will be: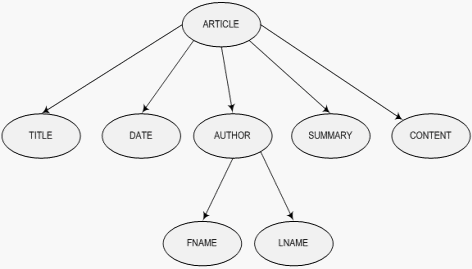
The DOM programming interfaces
enable applications to traverse the tree and manipulate its nodes. Each node is
defined as a specific node type as Element, Attribute, Comment, CData, Text,
etc. Attributes are considered special because they are not treated as nodes,
but are treated more like properties of
elements.
XML Syntax
Consider Sample.xml.
The first line in the document - the XML declaration - defines the XML version and the character encoding used in the document.
The next line describes the root element of the document (like it was saying: "this document is a article") i.e., “ARTICLE”.
The next lines describe the child elements of the root (TITLE, DATE, AUTHOR, SUMMARY, and CONTENT).
Each element can also have child’s i.e. AUTHOR has FNAME and LNAME.
Elements can also have attributes i.e. ARTICLE has ID as attribute.
XML text can also be loaded from a text string.
The syntax for writing comments in XML is similar to that of HTML.
<!-- This is a comment -->
Important instructions
XML elements must follow these naming rules:
- Names can contain letters, numbers, and other characters.
- Names must not start with a number or punctuation character.
- Names must not start with the letters xml (or XML or Xml…)
- Names cannot contain spaces.
XML elements must have a closing tag. With XML, it is illegal to omit the closing tag.
XML tags are case sensitive.
XML elements must be properly nested.
XML documents must have a root element.
Attribute values must always be quoted. ID=’AAA01’ is correct & ID=AAA01 is wrong.
With XML, white space is preserved.
XML tags may have a functional meaning, depending on the nature of the application.
If you use attributes as containers for data, you end up with documents that are difficult to read and maintain. Try to use elements to describe data. Use attributes only to provide information that is not relevant to the data.
WHY CDATA?
You might need to use Escape characters:
<CONTENT>if TotalViews < 10 then<CONTENT> is wrong
<CONTENT>if TotalViews < 10 then<CONTENT> is correct
Everything inside a CDATA section is ignored by the parser.
If your text contains a lot of "<" or "&" characters the XML element can be defined as a CDATA section.
Its syntax is "<![CDATA[" and ends with "]]>"
<CONTENT><![CDATA[ if TotalViews < 10 then ]]></CONTENT>
XML Namespaces
Since element names in XML are not fixed, very often a name conflict will occur when two different documents use the same names describing two different types of elements.
The namespace attribute is placed in the start tag of an element and has the following syntax:
xmlns:namespace-prefix="namespace"
When a namespace is defined in the start tag of an element, all child elements with the same prefix is associated with the same namespace.
<Test:COLUMN xmlns:Test="One">
<Test:NAME>FirstName</Test:NAME>
</Test:COLUMN>
<NewTest:COLUMN xmlns:NewTest="Two">
<NewTest:NAME>FirstName</NewTest:NAME>
</NewTest:COLUMN>
You can also define a default namespace for all the child
elements.
Syntax is:
<element xmlns="namespace">
Example:
<COLUMN xmlns="Two">
<NAME>FirstName</NAME>
</COLUMN>
XPATH
XML Path Language (XPath) is a general-purpose query notation for addressing and
filtering the elements and text of XML documents. XPath expressions can address
parts of an XML document.
For example, the query "find the <ARTICLE> elements that have a ID attribute
with the value of 'AAA01', and that are contained in the <ARTICLES> element at
the document root" can be expressed as in XPath expression as
"/ARTICLES/ARTICLE[@ID='AAA01']".
The expression ARTICLES/ARTICLE will return a node-set of the <ARTICLE> elements
contained in the <ARTICLES> elements, if such elements are declared in the
source XML document.
XPATH Expressions
XPath expressions can match specific patterns, return the results, and perform additional operations and can also search through the document tree.
XPath expressions are constructed using the operators and special characters.
Few of them are listed below:
- "/" Child operator; selects immediate children of the left-side collection.
- "//" Recursive descent; searches for the specified element at any depth.
- "." Indicates the current context.
- ".." The parent of the current context node.
- "*" Wildcard; selects all elements regardless of the element name.
- "@" Attribute; prefix for an attribute name.
- ":"Namespace separator; separates the namespace prefix from the element or attribute name.
XPATH Examples
ARTICLES/ARTICLE/DATE - All <DATE> elements within an <ARTICLES> <ARTICLE> structure.
ARTICLES/*/DATE - All <DATE> elements that are in sub-structure of <ARTICLES> element.
ARTICLE[DATE = "05/16/2005"] - All <DATE> elements which has at least one <DATE> child-element child with the value "05/16/2005".
ARTICLE/* - All children of <ARTICLE> element.
Test:COLUMN - <COLUMN> element from the “Test” namespace.
Test:* - All elements in “Test” namespace.
ARTICLE/@ID - The ID attribute of <ARTICLE> elements.
ARTICLE[@ID = "1234"] - All <ARTICLE> elements which has attribute ID with value "1234".
XML File Structure
How the XML file is structured is important,
and its very crucial in determining the size of your file. The structure should
be able to describe the data easily. Also, XML file structure depends on needs
of the application for which it is used. A particular XML file can be structured
in different formats i.e., using elements only or using the attributes instead
of elements. More time has to be given for the design of the XML file and
finally select the best suitable structure for the application.
Example: Consider a sample XML below. Also see the variations possible.
These are only few of them, there can be many.
<DATASOURCE Name="Users">
<ROW>
<COLUMN
Name="ID"><![CDATA[1]]></COLUMN>
<COLUMN Name="FirstName"><![CDATA[Vasant]]></COLUMN>
<COLUMN Name="LastName"><![CDATA[Raj]]></COLUMN>
</ROW>
<ROW>
<COLUMN
Name="ID"><![CDATA[2]]></COLUMN>
<COLUMN Name="FirstName"><![CDATA[Anant]]></COLUMN>
<COLUMN Name="LastName"><![CDATA[Raj]]></COLUMN>
</ROW>
</DATASOURCE>
Variation 1:
<DATASOURCE Name="Users">
<ROW>
<COLUMN Name="ID" Value="1"/>
<COLUMN Name="FirstName"
Value="Vasant"/>
<COLUMN Name="LastName"
Value="Raj"/>
</ROW>
<ROW>
<COLUMN Name="ID" Value="2"/>
<COLUMN Name="FirstName"
Value="Anant"/>
<COLUMN Name="LastName"
Value="Raj"/>
</ROW>
</DATASOURCE>
Variation 2:
<DATASOURCE Name="Users">
<ROW ID="1" FIRSTNAME="Vasant" LASTNAME="Raj"/>
<ROW ID="2" FIRSTNAME="Anant" LASTNAME="Raj"/>
</DATASOURCE>
Conclusion
XML, as a language has become a powerful tool for our day-to-day
transactions. More features should be explored, which allows you to make XML
implementation of your data successful and meaningful. XSLT, which allows you to
convert your XML file into another file without changing the original file is
widely used for data representation. XSLT will be discussed in upcoming
articles.
