

You may recall in my previous article on an alternative use case for PolyBase, I mentioned that Polybase actually offers a surprisingly flexible Disaster Recovery and backup replacement for otherwise very expensive on-premise solutions. That is what we will cover here.
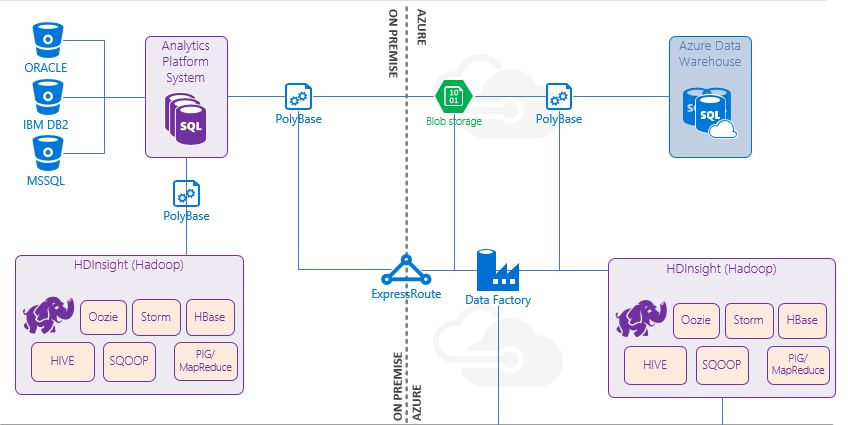
PolyBase Use Case Architecture
A lot of what I speak about refers specifically to the Analytics Platform System (APS), however PolyBase has been announced and confirmed as a feature that will be coming out in SQL Server 2016. So I feel this specific architecural implementation could be more relevant in the future to a wider audience.
PolyBase has been a fixed feature in APS, since it was rebranded from PDW to APS, with the inclusion of an optional HDInsights region built in to the appliance.
I feel that it is worth taking some time to explain the performance that is delivered from the true MPP architecture of an on premise APS (and now Azure Data Warehouse as well), mainly because it speaks volumes towards why this particular use case is a feasible option.
There are plenty of case studies (my company being one) and just as many white papers available on the Internet that go on and on about performance improvements for data warehousing workloads when running on an APS. I was a skeptic when we initially started our search for a dedicated data warehouse solution. However I can say from personal experience that we have seen query performance upliftments in the region of x70 (7 hour queries running under 5 minutes). We have the "smallest" appliance you can purchase which is a 1/3 rack, and due to the linear performance upliftment with APS, if we had to upgrade to a 2/3 we would see that same 7 hour query finish in under 2 minutes.
Due to this ground breaking performance, we have the luxury of no longer backing up every single data base at immense on premise storage costs, but rather investing in proper script version control (persisted in the cloud). The only data we are backing up and storing is the raw source data. With all this raw performance it is easier to re-run a set of analytics (as long as the source data is in tact) than it is to backup and restore the data. Literally re-building everything is faster than the traditional alternative. As long as our scripts are properly versioned and catalogued, there is nothing we cannot recreate in a few hours.
Architectural Blueprint
Our on premise APS consumes close on 2 billion rows of data monthly from various sources. Due to the nature of business and the current IoT/Big Data buzz words we see a lot of unstructured data also coming in from an existing Hadoop Cluster hosted on premise. The biggest advantage of PolyBase is the ability to query unstructured data directly from SQL without having to learn Hive or Sqoop or any of those tools.
Using normal T-SQL syntax we can now unlock business value from unstructure data in a hadoop cluster. Using PolyBase we can also export that same data into Azure Blob Storage. Which traditionally is quite a tedious process of setting up an import task on Azure. Once the data is in Azure Blob Storage, we can expose that data to the entire Azure stack, this includes Azure Data Warehouse.
APS constitutes a fairly significant infrastructure investment for most companies, so prior to Azure Data Warehouse the only DR option was to own two appliances at great cost. With Azure Data Warehouse we can now deliver the same performance on the Azure stack, and only incurring cost when/if we ever find ourselves in a DR situation.
As all our raw data is already in the Azure Blob Storage, and being consumed by other Azure services for advanced analytics (Machine Learning, Data Factories etc ...) , we are able to reload all our data using PolyBase into an Azure Data Warehouse at about 300GB/min. Starting with the most important data first, we could be operational on our data warehouse in under 30 minutes for DR and fully failed over in about 2 hours.
As for backups, with ExpressRoute in place, we are capable of restoring an entire database, if it is accidentally deleted or needs to be unarchived in less than 30 minutes as well. Although this is slower than restoring a backup of the database, it saves the cost of having to invest in an on-premise storage solution to house these backups. There is however nothing stopping you from storing the APS backup directly in Azure storage either and consuming it like a normal backup. There is potential to improve the restoring of backups (perhaps using StorSimple) but for our specific scenario, 30 minutes is well with in acceptable time frames.
PolyBase T-SQL Samples
All this code is executed directly in the APS (SQL 2016 with PolyBase will differ slightly). Here is the code for creating the External Data Source to Azure Blob Storage :
CREATE EXTERNAL DATA SOURCE Azure_Test
WITH (TYPE = HADOOP,
LOCATION = 'wasbs://test@test.blob.core.windows.net/'
)
CREATE EXTERNAL FILE FORMAT Custom_Delimiter_FF
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (
FIELD_TERMINATOR = '~|~',
DATE_FORMAT = 'yyyy/MM/dd'
),
DATA_COMPRESSION = 'org.apache.hadoop.io.compress.GzipCodec'
)
CREATE EXTERNAL TABLE dbo.Blob_Testing
WITH
(
LOCATION = '/files/AzureTesting',
DATA_SOURCE = Azure_Test,
FILE_FORMAT = Custom_Delimiter_FF
)
AS SELECT * FROM [DATABASE].[DBO].[DEMO_1]CREATE TABLE Azure_Testing_ReImport WITH (DISTRIBUTION = HASH (ID) ) AS SELECT * FROM dbo.Blob_Testing
CREATE TABLE Azure_Testing_Join WITH (DISTRIBUTION = HASH (ID)) AS SELECT TOP * FROM Table1 WHERE ID IN (SELECT ID FROM dbo.Blob_Testing)
So as you can see, it uses standard T-SQL that we all know and love. With a few caveats, but most of those are specific to the APS and not SQL2016 PolyBase (CTAS, DISTRIBUTION and HASH). I personally believe this is one of the most exciting features that we will see in SQL 2016 and I really think it is going to bring the Hybrid cloud solutions which combines structured and unstructured data, that until now has felt very disjointed, to a whole new audience.
I have only covered some of the very rudimental elements of PolyBase in this article and some of the applications are very specific to APS, but I am currently testing PolyBase in SQL2016 and will write a follow up article specifically for a SMP SQL 2016 implementation of PolyBase.
The implementation and execution of PolyBase into a hadoop cluster is literally that easy and even junior SQL users can pick up the syntax quite easilt, because once your data is in Azure, you can utilise the full might of the Azure stack for unparalleled analytical work loads.
I hope that this article has at least sparked some interest and maybe some great ideas with some of you.