

There are two words which, unfortunately, make DBA’s eyes roll with boredom more than any other words. They are “source” and “control”. Source control has long been viewed as a thing for developers and, again unfortunately, not even for SQL developers, just other developers.
Source control is not just for developers but is something that offers real benefits to everyone who codes and supports SQL Server databases. In this article we will look at just one aspect of how using source control for your databases can help to troubleshoot issues by using the version history, specifically how it can help DBA’s.
A SQL Server database as a whole contains different classes of “things”. A database can contain:
- Data
- A schema, which itself is rules about that data such as constraints, storage of that data i.e. the data types that constrain the data and the way data is stored.
- Code to handle the data so stored procedures, functions and even views.
What a database does not contain is a history of how the schema and code came to be in the state that it is in. When working on operational systems knowing how the current state came to be is vital.
Why is it vital to have a history of the current state of a database?
The main reason is that databases rarely contain the schema and code that is expected. This sounds strange especially where we have change control processes. However, even with processes in place, we can still get into situations where the schema and code are not as expected. Here are a few examples.
Firstly different types of people modify databases. One of the great things about working with SQL Server is the information that is available to help when there are performance issues. As long as you know where to look there are simple ways to find out what is and what isn’t performing as it should. For example, if a stored procedure is running slowly you can narrow down exactly which statement is slow, find out which tables and indexes the procedure is using, and look at ways to improve the performance. Unless the stored procedures are encrypted, you can happily modify the T-SQL or change the structure of the table or indexes with nothing more than the correct permissions. This work is often carried out by the DBA’s, sometimes without even the developers' knowledge. This is especially true if the database was developed by a vendor or a 3rd party.
In another example, changes to databases, even in 2015, are still often manually executed by DBA’s. With any manual process there is always room for mistakes. Because of this, scripts can sometimes be missed or parts of scripts can be run instead of the whole script leaving the database in a state that is not as the developers or DBAs expect.
Finally it is not just DBAs who can make mistakes, sometimes developers do not include everything that they should in a release, or inversely, they may include too much.
There are other genuine reasons why the state of a database becomes unknown so knowing it can happen we should look to use tooling to help us. Source control is that tool and although a good change control process helps, it cannot cover all cases especially where mistakes occur such as not running a part of a script. Instead we can use the history of change control to track what changes have happened to a schema and to the code in a database over time. If we take an analogy from the medical world, physicians do not just look at the current state of a patient but the history of the patient, what else have they had wrong with them and how that could affect the patient today – we have the tools available to us today so why wouldn’t we use them?
Still not convinced?
Let’s take a look at a fictional example. The lead DBA in a company is responsible for the database that runs the payroll system. There was a code release after the previous payroll run and too much data has been changed to restore from a backup. During the reconciliation checks that are made just before actually paying the employees, the system finds that a number of employees are due to be paid significantly more than they should be, which has halted the run.
To complete the payroll run, the DBA needs to find out why some employees are being paid much more than they should actually be. This is a time sensitive issue because employees rely on being paid on specific dates, and any delays will cause hardship for some. Because the issue has been found after hours, the on-call DBA has been told to get it fixed before the morning, which is, of course, before the time when the developers arrive at the office.
The DBA knows which tables and procedures are involved in calculating the salary and scripts out the definitions in SSMS:
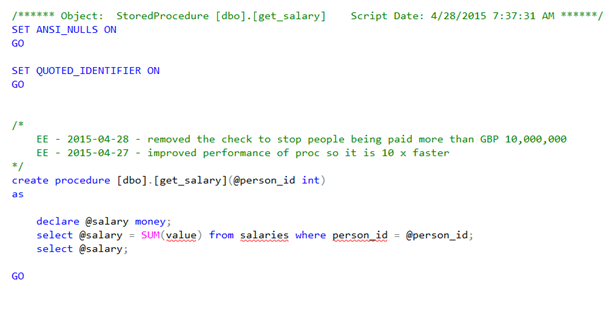
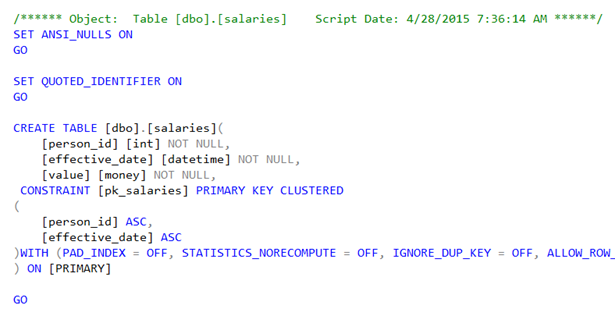
In this case the answer looks obvious because the stored procedure to get someone’s salary calculates a sum of their historical salaries instead of just getting the latest value. The DBA goes to the deployment folder for the last release and this exact version of the stored procedure is in the script, so it is not a case of the DBA running an incorrect script or missing part of the script. The code is as the DBA expects it to be.
If the code is as the DBA expects it to be, is this how the code used to look before the last release? The DBA could restore an old backup of the database, but that would take time, especially if the restore process takes a long time. If there are the previous change scripts available, the DBA could go through those scripts, searching for the stored procedure. Neither of those options are particularly interesting when you are working with a tight deadline.
At this point the DBA can probably fix the issue, but personally, with something this sensitive, I would certainly want to know how this change came to be before implementing a fix. It could be that the code is exactly as expected but something else has gone wrong. Perhaps the stored procedure shouldn’t have been called at all. The DBA really needs to understand the wider picture as it is possible this code has been in use for years, and there is something else wrong.
It is also important to remember that if the stored procedure was 1000+ lines long then the cause would not be so obvious.
If we look at the stored procedure code we do have the history of what changed. The comment header has two comments that give a description of the last changes to the stored procedure. However, the problem with relying on comments is that they really cannot and should not be trusted. Firstly people forget to put in comments. Secondly people make mistakes and can accidentally move pieces of code around, delete code or add extra code. If someone accidentally pastes some code into a procedure without noticing then they will not comment why it is there.
If we exclude mistakes as a possibility, then using a code review and examining comments could be used, but because humans make mistakes, we cannot rely on comments 100% of the time.
So it is 4 am in the morning, and the accounts department need to process the payroll by 6 am, otherwise no one will get paid. The developers are fast asleep. What is causing the payroll reconciliation to find an error and stop?
This is where you really need to use source control and be comfortable using that to find out what has actually happened to the code, rather than just looking at what the comments might or might not say.
So let's take a look at how we can use the history in source control to find out what happened. Each source control system is different. TFS even has a web front end so you do not have to download a repository or any source control tools.
In this example I am using the Visual Studio online version, where you can navigate to the code tab and drill down until you find the “get_salary” stored procedure. You can see the history of the file and which check-ins have had an impact on the “get_salary” stored procedure.
If we look at the last check-in, we see that there are three changes that occurred together:
- A new stored procedure
- A change to the sqlproj file which is caused by adding the new procedure
- The stored procedure which has had its contents changed.
We can see all of these changes below.
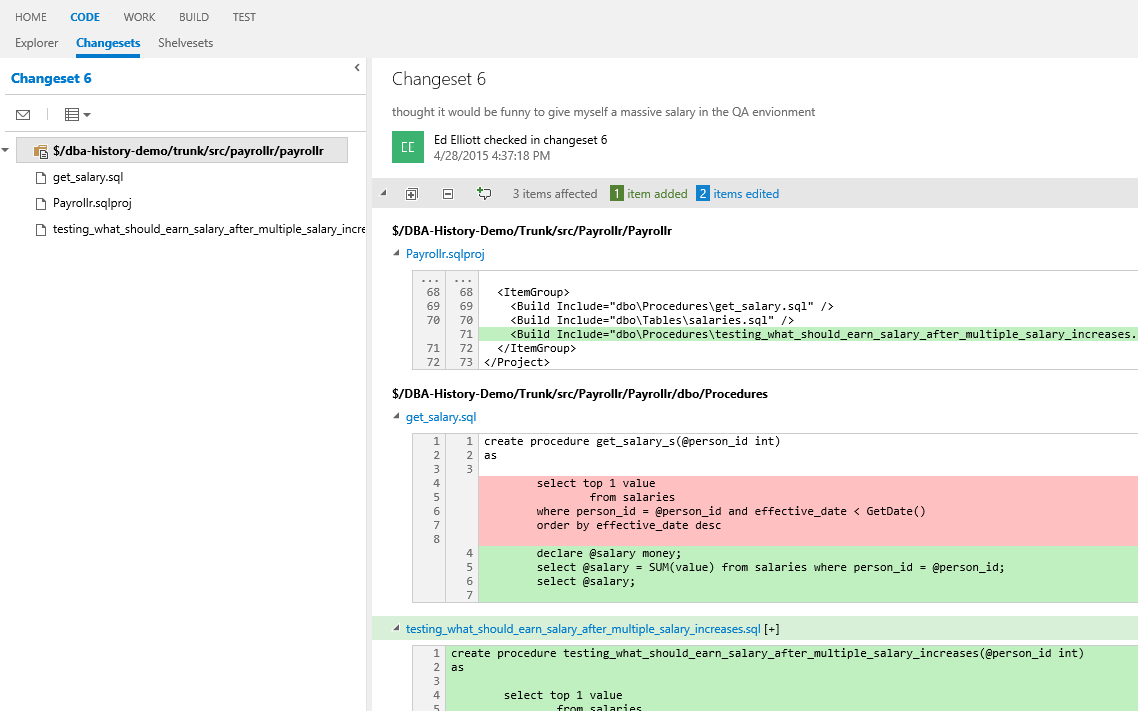
Here we see the check-in comments. For me, these are similar to standard comments. Although useful, they do risk being incorrect due to people making mistakes.
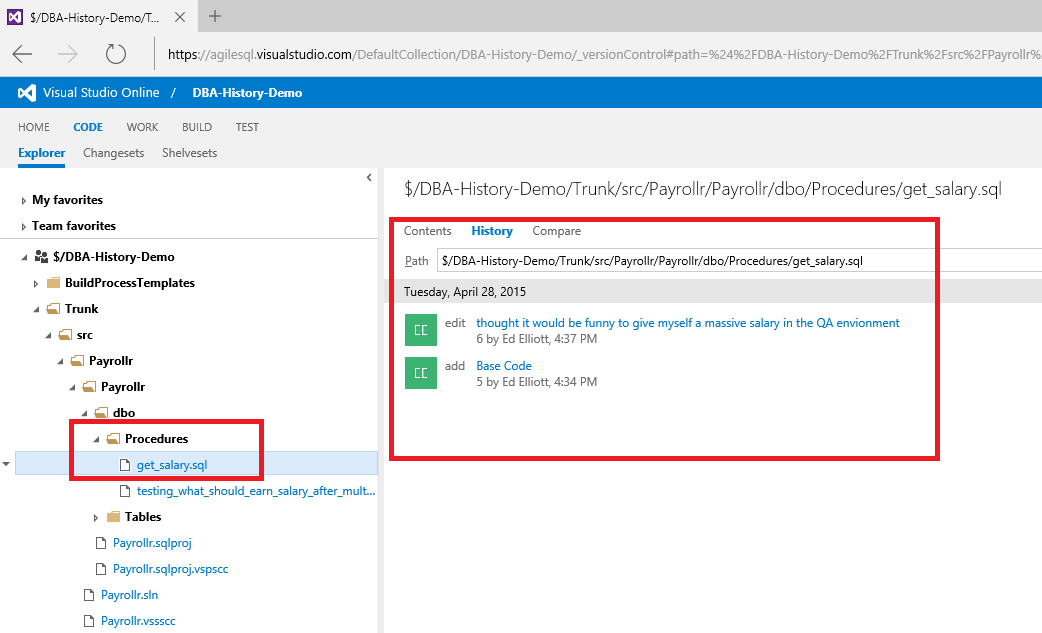
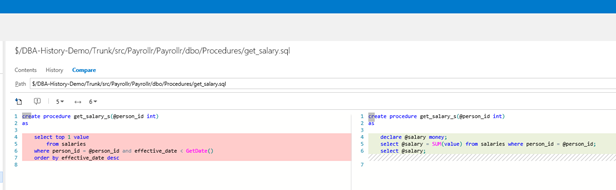
The website also lets us view changes on a file by file basis. To see the details of the changes, just click on the file in the tree on the left hand side and then “Compare” to see the differences.
What we see in this case is that there is a new test stored procedure to generate dummy higher salaries which has the code we would expect to be in the actual procedure that got released to production. It is highly likely that the developer copied and pasted the original stored procedure and simply changed the one wrong one. This should have really been covered by unit and integration tests, but that is for another article!
If you do not have TFS then you should find out how to view the history in the source control system you use. All source control systems let you view history but they all have their own set of tools to do it.
Using the source control history is how to find out how your code got into the state it is currently in, not comments at the top of a stored procedure. If we also have app code that has changed we can easily see what that was like at the check-in, maybe the app and db code are in the same solution, which makes it really simple. Even the database and app code are in different solutions or source control systems if you have a date and time you can use when the file you were interested in was changed, to figure out what the app code was doing just look at the files as they existed at that time.
