

In data warehousing, date dimension is the most frequently used dimension. Consequently, when building a cube for a data warehouse in Analysis Services, we almost always have to create a date dimension. In this article I'd like to discuss things that we are likely to come across when creating a date dimension in Analysis Services, such as having several date dimensions and handling unknown rows. I'm going to refer to Analysis Services as SSAS, which stands for SQL Server Analysis Services. In this article I'm referring to SSAS 2005 and SSAS 2008, not SSAS 2000.
Role Play Dimension
In SSAS, we can have the same dimension added into the cube several times as different names. This is known as a 'role play' dimension. A dimension that has been attached to a cube is called a 'cube dimension'.
The purpose of having a role play dimension is to have identical dimensions in the cube. These cube dimensions have the same attributes, the same members, the same hierarchies, the same sorting order, the same properties, the same default member, and the same display folders. Everything is the same, except the name and the relationship to the measure groups in the cube, i.e. referenced or direct, materialized or not.
For example, in retail banking, for checking account cube we could have transaction date dimension and effective date dimension. Both dimensions have date, month, quarter and year attributes. The formats of attributes are the same on both dimensions, for example the date attribute is in 'dd-mm-yyyy' format. Both dimensions have members from 1993 to 2010. Both dimensions have Year-Month-Date hierarchy.
When we change something, for example adding 2011 dates, both transaction date dimension and effective date dimension will be affected. This way we can be sure that they will always be identical. On the other hand, if we create the transaction date dimension and effective date dimension from 2 separate date dimensions (say transaction date is from date1 and effective date is from date2) then when we change the date1 dimension (say adding a new level), only transaction date will be affected.
Multiple Named Queries
Data Source View (DSV) is a layer on an Analysis Services project where we can specify the tables and views that we use to build a cube, and the relationship between the tables/views. Instead of specifying a table or a view, we can also specify a SQL select statement that queries a table or a view, or several tables/views. This select statement is called a Named Query.
On the DSV, we can create several named queries from the same date dimension table on the relational database. The reason for doing this is to enable us select a different range of data, i.e. different sets of rows. For example, in a credit card cube, for the start date dimension we may want to select different date range compared to the expiry date dimension. Perhaps the start date starts from 1996 but the end date starts from 1998. For insurance industry, for each policy or risk we have written date, accounted date, inception date, effective date and expiry date. These dates may have different ranges.
The second reason for having separate named queries on the DSV for date dimensions is to enable us to have different sets of columns. For example, for written date, transaction date and effective date the business may need year, quarter, month and date attributes. Where as for snapshot month they only need month and year.
The third reason for having separate named queries in the DSV for date dimensions is to enable us to set different formats for each attribute, as well as different hierarchy structures. Some date dimension may require '2008 July' and '2008-Q1' without any hierarchy but another date dimension may require just the month name and quarter name (e.g. 'July' and 'Q1') and a hierarchy to connect the two.
Normally for each named query on the DSV we create one dimension. But in some cases we may need to create 2 or more date dimensions from a single named query on the DSV. The reason for this is to enable us to configure the dimension properties differently, such as unknown member, default member, error configuration and display folder. And also, we can specify dimensional security differently.
Before we continue, let's recap:
- From one date dimension table we can create several named queries.
- From one named query we can create several dimensions.
- From one dimension we can create several cube dimensions.
Unknown member
An 'unknown row' is a row on the dimension table to which the orphaned fact rows are assigned. The unknown row usually has a surrogate key value of 0 or -1. For example, the date dimension table contains dates from 1/1/1980 to 12/31/2020. If on the source of the fact table we have a date of 1/1/1970, which is not on the dimension table, the date surrogate key on the fact table is set to 0 (or -1). This way that fact table row is assigned to the unknown row.
In some data warehouses, the unknown row for the date dimension is 1/1/1900. Consequently, the year column of this unknown row is set to '1900'. Some users don't like to see '1900' when browsing the cube. They prefer to see 'unknown' instead of '1900'. But year is a numeric column and we can't store the word 'unknown' in the year column. In this case we may choose not to use the unknown row but to map it to the dimension unknown member. To do this, we make the unknown member of the date dimension 'visible'. On the DSV, we explicitly exclude the unknown row like this: “select … from dim_date where date_key 0”. On the error configuration of the cube, we set the KeyErrorAction to 'ConvertToUnknown', the KeyErrorLimitAction to StopLogging and the KeyNotFound to IgnoreError. This way, when SSAS processes the cube and found a date on the fact table that does not exist in the date dimension table, that fact row will be assigned to the unknown member and SSAS will continue processing the cube. We need to be careful when doing this because it will affect all other dimensions, not just the date dimension.
There are 3 places where error configuration for the orphaned fact row can be set: cube, measure group and partition. The error configuration on the dimension itself doesn't affect the orphaned fact row; it is for orphaned dimension rows in a snow flake schema situation.
Another benefit of using the unknown member rather than the unknown row is to capture 'orphaned rows'. An orphaned row is a row on the fact table with a dimension key that does not exist on the dimension table. In best practice this should not happen. The ETL is supposed to prevent this situation. The ETL should allocate key 0 (or whatever the surrogate key of the unknown row is) to those fact table rows, so that they are mapped to the dimension unknown row. But in reality this does happen in practice. Not intentionally of course but it does happen. A typical situation is where the dimensional key column on the fact table contains NULL rather than 0 because that key column is not applicable for that fact row.
We suppose to have a foreign key on the fact table to prevent orphaned rows, but in many data warehouse implementation I found that this is not the case. Some people argued that “it is not possible to have orphaned rows on the fact tables”, because “all data flowing into the warehouse is controlled by the ETL” and “the ETL always mapped unknown fact rows to the unknown row in the dimensions” so “we don't need to put foreign keys”. But I found in a few occasions that data warehouses without foreign keys on the fact tables do have orphaned fact rows. In chapter 6 of my book Building a Data Warehouse With Examples on SQL Server, I explained the benefits of putting foreign keys on the fact tables and how to deal with the assumed disadvantages (such as slowing ETL load process).
In data warehousing and business intelligence, mapping orphaned fact rows to the unknown member is important because if not we will miss those fact rows, causing the total of measures to be incorrect. In SSAS, if we don't change the UnknownMember and ErrorConfiguration properties, by default orphaned rows on the fact table will be mapped to the dimension unknown member. This way we will always get the correct totals of the measures. Some people set the UnknownMember property of the dimension to 'Hidden', relying completely to the ETL to guarantee that there are no orphaned rows in the fact table. If you decide to do this, it is wise to put foreign keys on the fact tables to guarantee referential integrity.
Another benefit of using unknown member rather than unknown row is that we can specify the name of the unknown member. It doesn't have to be 'Unknown'. We can set it to 'Not Applicable', for example, to suit the users' needs.
Despite all the advantages I mentioned above, personally I would prefer not to fiddle around with the unknown member in SSAS. Rather, I prefer to set the data in the fact and dimension tables correctly and leave the SSAS UnknownMember as per their defaults. For example, I've come across a situation where the value of an attribute on the unknown row is = 'unk'. But there is another row in the dimension table with the attribute value = 'unknown'. When browsing the cube the users will find that the attribute has both 'unk' and 'unknown' members. We could tackle this on the DSV by adding a 'CASE WHEN' clause on the named query SQL, or we could exclude the unknown row and use the unknown member instead. But I prefer to fix the data, setting the physical values of that attribute correctly in the dimension table. The physical dimension table may not only be used by SSAS; it may also be used for reporting by SSRS or other reporting/BI tools such as Business Objects or Cognos.
Another disadvantage of using unknown member rather than unknown row is that when we make the unknown member visible, when there is no unmatched record, we will still see that member (unless we suppress it on the OLAP client).
Date Hierarchies
It is a best practice to build a hierarchy and hide the composing attributes. This is more so in 2008 where AS checks if we have hidden the members used in the hierarchy and give us a warning if we haven't done so, e.g. “Avoid visible attribute hierarchies for attributes used as levels in user-defined hierarchies”.
For example, say we have these attributes: date, quarter, month and year.
- Year: yyyy, e.g. 2008
- Quarter: yyyy Qn, e.g. 2008 Q4
- Month: yyyy-mm, e.g. 2008-10
- Date: yyyy-mm-dd, e.g. 2008-11-15
We then create a Year-Quarter-Month-Date hierarchy and we hide the Date, Month and Year attributes. When we browse the hierarchy using ProClarity it looks like this:
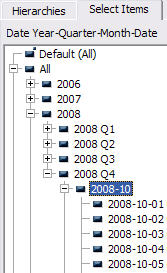
Figure 1. Browsing a date hierarchy in ProClarity
And in Excel 2007 it looks like this:
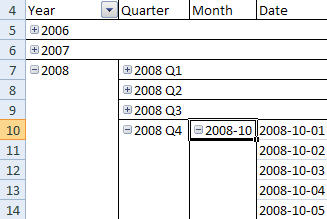
Figure 2. Browsing a date hierarchy using Excel 2007
My colleague John Tunnicliffe advised me about ISO 8601 date format (yyyy-mm-dd), which I think is a good idea because of its clarity. It takes away the confusion caused by country-by-country custom such as dd/mm or mm/dd. He also mentioned about dd-mmm-yyyy format, e.g. 06 May 2008, which is useful to remove the confusion about month, such as 05/06/08: is it 5th June or 6th May? One caution about using mmm (short form of month) is the language, i.e. is it Mei, Mai or Mayo?
On the OLAP client, users can select members from different levels. And those members are not necessarily ascendant to each other. For example, users can still select non-ascendant months together, user can still choose 'all dates in July 2008'. This depends on the OLAP client, i.e. some OLAP clients provide facility to select all descendants of a member, but some with OLAP clients we have to select the descendants manually.
Although BIDS 2008 advised to hide the attributes used in the hierarchy, in my experience some users would still prefer to see those attributes. This enables them to use (for example) the month attribute directly either as a slicer or filter, without navigating through the Year-Month-Date hierarchy.
We should name our hierarchies properly. The name needs to reflect the levels, i.e. 'Year-Month-Date', not just 'Date Hierarchy'. Also it is better to avoid abbreviation. Calling it YMD might cause confusion among some users, wondering what YMD stands for.

It must have been quite a long read so far, so I'll end it here. In part two I will discuss:
- Date dimension that is used as a referenced dimension
- Date dimension that is generated and stored on the SSAS server (no physical table)
- Advantages and disadvantages of using smart date key e.g. YYYYMMDD with int data type
- Enabling users to select a date (or month) to be used in calculated measure using 'from date' and 'to date'
- and other things
Vincent Rainardi
Author of Building a Data Warehouse With Examples on SQL Server
November 2008

