

What is the best way to store an IP Address in SQL Server
Imagine that you are asked to design a database for a data analysis team to perform web site traffic analysis.
This brief will have many requirements and amongst them will be the need to store IP addresses.
Search engines such as Google have a fixed range of IP addresses so the team can easily separate out
traffic from true visitors Vs traffic from bots. Although the team have a good rudimentary knowledge of T-SQL the data must
be relatively simple to query. So with regard to IP addresses the requirement is as follows:
- Store IP addresses efficiently
- Allow retrieval of IP addresses in a machine readable format
- Allow simple querying on a range or ranges of IP addresses
The data type question
If traffic to your web site is high then the choice of data types is going to be important.
You could keep the IP address as a VARCHAR(15) but given the nature of what an IP address actually is, 4 integers in the range 0 to 255, this seems a trifle wasteful.
My initial thought was to use techniques described in Lee Everest's article Introduction to bitmasking in SQL2005
but if you read the forum discussion of the article you will see an interesting suggestion by Joe Celko.
So what possiblities do we have? Let us consider the ip address 192.168.0.5
| Method | Storage | Comment |
|---|---|---|
| VARCHAR(15) | Between 7 and 15 bytes | Stores the IP address in human readable but this is wasteful. |
| BIGINT | 8 bytes | We can represent our IP address as 192168000005. It is stretching the definition of human readability somewhat but this depends on your audience. |
| INT | 4 bytes | Our IP address is no longer human readable being represented as 1084751877. |
| Four separate TINYINT fields | 4 bytes | Our address is now both efficient and human readable just as Joe Celko pointed out. |
SQL 2005 CLR User Defined Types
SQL2005 provides us with one other possiblity. The .NET assembly user defined type.
I was fortunate to go on the Microsoft "Updating Your Database Development Skills to Microsoft SQL Server 2005" (Course 2734B) which included
an IP address UDT. As I am not sure of the copyright issues surrounding the code for the UDT I am not including the source code here but the UDT
provided the following functionality.
- Accept an ip address in the form nnn.nnn.nnn.nnn
- Return the individual bytes of an IP address
- Return the string representation of the IP address
- Return a varbinary representation of the IP address
- Return a string with the PING command and the IP address. I removed this from the code as it was irrelevant.
There are similar functions available on the web.
Test methodology
I decided to create five tables and into each put 1 million rows. Each table would contain a single INT IDENTITY field (IPID)acting as the primary key, plus the chosen method of storing an IP address.
| Table | Comment |
|---|---|
| IPAddressSource | IP Address stored as 4 separate TINY INT fields |
| IPAddressINT | IP Address stored as a single INT field |
| IPAddressBIGINT | IP Address stored as a single BIGINT field |
| IPAddressVARCHAR | IP Address stored as a single VARCHAR(15) field |
| IPAddressUDT | IP Address stored in a .NET CLR data type |
After population I ran an sp_spaceused on each table using the stored procedures described in
Automated Monitoring Database Size Using sp_spaceused.
For those who caught the article first time around I have added the equivalent procedure for SQL2000 in the discussion forum
attached to the article.
Initial results
| TableName | Rows | Reserved | Data | IndexSize | Unused |
|---|---|---|---|---|---|
| dbo.IPAddressBIGINT | 1,000,000 | 20,872 | 20,784 | 88 | 0 |
| dbo.IPAddressINT | 1,000,000 | 16,904 | 16,808 | 72 | 16 |
| dbo.IPAddressSource | 1,000,000 | 16,904 | 16,808 | 72 | 24 |
| dbo.IPAddressUDT | 1,000,000 | 49,928 | 49696 | 192 | 40 |
| dbo.IPAddressVARCHAR | 1,000,000 | 30,088 | 29,960 | 120 | 8 |
Straight away we can see that the table using the CLR UDT is by far the worst in terms of storage size taking nearly 50MB
to store our million rows.
Running an sp_help reveals why.
| Column_name | Type | Computed | Length | ...etc |
|---|---|---|---|---|
| IPID | int | no | 4 | |
| IPAddress | IPAddress | no | 37 |
There is very little information available on the storage of data in CLR UDTs but what appears to happen is that
the instance of the datatype (including structure and data) is serialised and stored in a VARBINARY type format in the field.
This sort of begs the question as to what real-world use are CLR UDTs?
The motivation to try a CLR IPAddress type was that a single type could encapsulate the IP address. The type is atomic.
Storing the data as 4 TINYINT fields means that any one of the four parts of the IP address is meaningless in its own
right. It is not atomic.
In this case we can see that there is a heavy overhead in gaining atomicity.
The indexing question
We have established that for readability and efficient storage of data storing an IP address as 4 separate TINYINT fields is the most efficient. But what about searching on IP Addresses?
What I need to be able to do is to identify ranges of IP addresses that correspond to Web Bots. Given the sheer volume of records
I am going to need to discover the most efficient method of doing this.
The SQL Query engine decides for itself whether or not there is a benefit in using an index. If the index is not regarded as being
selective enough the engine will simply ignore the index.
To give an example I had a table containing details of cars where the primary key was make, model and year.
WHERE make='FORD' resulted in a TABLE SCAN
WHERE make='MASERATI' resulted in an INDEX SEEK
The only difference in the WHERE clause was the value being searched for.
Again if you look at the discussion for Lee Everest's article
to make the index as selective as possible Joe Celko suggests that an index be placed across the four TINYINT columns representing the IP Address but from the right-most
first, in effect recording the IP address backwards. As the digits in an IP address vary the most in the right hand portion and least in the left hand portion this
should make the index as selective as it can possibly be.
My first port of call was to create such an index on my dbo.IPAddressSource table.
The next step was to devise a query that would search for a range of IP addresses such as 72.100.5.25 to 74.50.25.1
/*
Define parameters to test various ranges of IP addresses
*/
DECLARE
@LowIP1 TINYINT , @HighIP1 TINYINT ,
@LowIP2 TINYINT , @HighIP2 TINYINT ,
@LowIP3 TINYINT , @HighIP3 TINYINT ,
@LowIP4 TINYINT, @HighIP4 TINYINT
SELECT
@LowIP1 = 72, @HighIP1 = 74 ,
@LowIP2 = 100, @HighIP2 = 50 ,
@LowIP3 = 5, @HighIP3 = 25 ,
@LowIP4 = 25, @HighIP4 = 1
SELECT * FROM dbo.IPAddressSource
WHERE
(
IP1= @LowIP1
AND (
IP2>@LowIP2
OR (IP2=@LowIP2 AND ((IP3 = @LowIP3 AND IP4>=@LowIP4) OR IP3>@LowIP3))
)
)
OR (IP1>@LowIP1 AND IP1OR
(
IP1 = @HighIP1
AND (
IP2 OR (IP2=@HighIP2 AND ((IP3=@HighIP3 AND IP4OR IP3
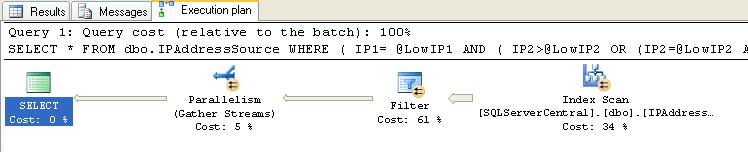
As we can see the WHERE clause is a bit convoluted and this is just searching for one range of ip addresses. We should also look at the execution plan.

The subtree cost is 4.56566
An alternative approach
We have established that storing an IP address as 4 TINYINT fields achieves two objectives
- Storing the IP address in an efficient format
- Storing the IP address in a format that is easily read by a human being
The problem areas are as follows
- Searching for a range of addresses requires convoluted WHERE conditions
- The query is expensive
As an alternative experiment I decided to create a new table called dbo.IPAddressCALC as follows
IF NOT EXISTS(SELECT 1 FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_NAME='IPAddressCalc') CREATE TABLE dbo.IPAddressCalc( IPID int NOT NULL, IP1 tinyint NOT NULL, IP2 tinyint NOT NULL, IP3 tinyint NOT NULL, IP4 tinyint NOT NULL, IPAddress AS CAST( ((CAST(IP1 AS BIGINT)* 16777216) +( CAST(IP2 AS BIGINT)* 65536) +( CAST(IP3 AS BIGINT)*256) +IP4) -2147483648 AS INT), CONSTRAINT PK_IPAddressCalc PRIMARY KEY CLUSTERED (IPID ASC) ) GO
Our IPAddress field is a calculated field using the bitmasking technique and contains an INT value.
To aid our search I placed an index on this column. To search this column now our query would become
SELECT * FROM dbo.IPAddressCalc WHERE IPAddress BETWEEN @Low AND @High
We would probably create function to return the values for @Low and @High from supplied IP addresses.
Our WHERE clause is much simpler and it is now easy to write a query that can handle multiple ranges of ip addresses.
Our execution plan is also slightly different.

The subtree cost is 3.73884
Wrapping it all up
The final step is to example sp_spaceused results for our two tables. We are interested
in the amount of data and index space taken up by each item.
| TableName | Rows | Reserved | Data | IndexSize | Unused |
|---|---|---|---|---|---|
| dbo.IPAddressCalc | 1,000,000 | 30,864 | 16,808 | 13,952 | 104 |
| dbo.IPAddressSource | 1,000,000 | 27,856 | 16,808 | 10,960 | 88 |
Adding a calculated column has no affect on the data held within the table, however, over 1 million rows the index takes
up just under 3MB more space.
The final note to add is that our analysis tables would be populated using some form of bulk loading process of the previous
day's results. Placing an index on a calculated field of a highly dynamic table could potentially cause performance problems.
Addendum
To develop this solution I generated 1 million random IP addresses.
For those of us who have cursed the SQL Server RAND function my population query was as follows
IF NOT EXISTS(SELECT 1 FROM dbo.IPAddressSource) BEGIN SET ROWCOUNT 1000000 INSERT INTO dbo.IPAddressSource(IP1, IP2, IP3, IP4) SELECT FLOOR(256*RAND(cast(cast(left(newid(),8) as varbinary ) as int )) ), FLOOR(256*RAND(cast(cast(left(newid(),8) as varbinary ) as int )) ), FLOOR(256*RAND(cast(cast(left(newid(),8) as varbinary ) as int )) ), FLOOR(256*RAND(cast(cast(left(newid(),8) as varbinary ) as int )) ) FROM master.dbo.sysobjects AS O1 , master.dbo.sysobjects AS O2 SET ROWCOUNT 0 END
The method works because NEWID() returns a number that is supposed to be unique in time and space and consists fo a consistant format
containing hexadecimal strings.
What I am doing is taking the first block of 8 characters, converting the resulting string to a VARBINARY value and this resulting value
is then converted into an integer value.
I don't actually care what the integer value is as I am simply feeding it into the RAND function as a seed.
