

At the SQLBits conferences there is always the quandary of six must-see presentations running in parallel at any one time. Throw the SQLCat studio into the mix and the greatest frustration is that there is simply too much grade A stuff to see and to little time to see if, even if you do attend on all 3 days.
Sadly, as a result, I missed Denny Cherry's presentation but in the lull between the conference and the time when the presentation videos are posted on the SQLBits web site I spent some time Googling his work. I happened across an interview with Denny and one comment of his that struck home was his lamenting that DBAs are hampered by their lack of knowledge with regard to storage. As storage is the biggest bottleneck this would be an area that DBAs would do well to pay attention to.
I spent some time speaking to the Fusion-IO guys who have long been sponsors of the SQLBits and also two more storage vendors who joined them as sponsors. Coupled with many post-work/pre-beer conversations with SAN administrators it struck me that with IT departments expected to do ever more with ever decreasing resources the only way we can hope to continue to deliver business value is if the different IT disciplines engage in dialogue to gain a mutual understanding and appreciation of the challenges faced by their peers across those disciplines. Such appreciation and sharing of knowledge will lead to a more rounded, efficient and appropriate solutions for our commercial stake-holders.
The problem we face is that even when the IT disciplines talk to each other it is as if we are trying to overcome our own "Tower of Babel" where our desire to communicate is confounded by the lack of a common tongue. This article seeks to try and address this issue so if you've ever wondered why a request for storage from you SAN administrator results in a pained expression that would be instantly familiar to anyone who has watched their dog try to pass a lego brick, read on.
A way of looking at applications
I have deliberately used the two Platonic solids shown below to represent a view of IT solutions. Business needs are supported equally by Data, Applications and Infrastructure but each individual item is equally dependent on the other three. No single item stands supreme. A particular IT solution relies on processor power, memory, somewhere to store the data and the means to store or retrieve that data in a timely fashion.
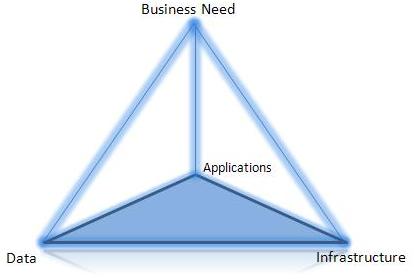 | |
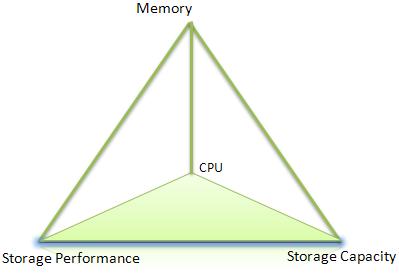
I emphasise the equality because IT departments already face enough external threats without creating new ones with internal bickering over supremacy. The paradox is that if one discipline is superior, then in bragging its acolytes would demonstrate their inferiority!
Storage costs and capacity
Storage costs have decreased geometrically just as storage capacity has increased geometrically. Matthew Komorowski has put together articles and graphs that illustrate this neatly and also reveal that there is a straight-forward relationship over time. It is much like Moore's law for the number of transistors on a CPU.
It should be noted that storage capacity of a hard disk platter has begun to plateau over the past 18 months illustrating that there is only so much that can be crammed onto a rotating magnetic disk.
Storage performance however has not kept up with the improvements in storage density and computer power. Where as capacity and power have increased by way of millions, storage performance has gone up by a factor of 200 over the same time period. In addition performance of enterprise grade storage (where reliability is essential) lags behind consumer grade storage.
Storage administrators find themselves in the position where: -
- Providing raw capacity is not the issue
- Providing storage performance is both expensive and complex.
The heart of the problem
A traditional hard disk drive (HDD) has a number of mechanical moving parts as the diagram from the MSDN site illustrates.
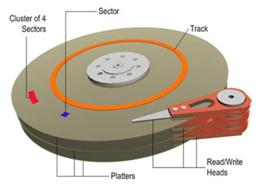
There are physical limits as to the speed at which the physical disk platters can move and the disk heads can traverse and reverse direction. There are also limitations as to how accurately the drive heads can read from the disk and this is affected by the following factors
- The density of the information on the disk
- The speed at which the disk patters are rotating.
The physical manifestation of this is the fact that larger capacity drives have to spin at a lower rate than lower capacity drivers in order to maintain reliability. As a direct result of this the throughput (measured in IO per TB) of the larger drives is lower than their smaller siblings.
Disk size | Rotation Speed (rpm) | IO/TB |
|---|---|---|
300 GB | 15,000 | 500 |
450 GB | 15,000 | 500 |
1TB | 7,200 | 72 |
20,000rpm Hard Disk Drive?
The first commercial 15,000rpm hard disk drive was release by Seagate in 2000. Prior to this the rotational speed of hard disk drives had increased from 7,200 to 10,000 to 15,000. As of May 2012 I have been unable to find a commercial 20,000 rpm hard disk drive and it is likely that the rise of SSD technology will mean that a 20,000 hard disk drive will never reach the market.
Spinning a disk at 20,000rpm presents a number of technical challenges
- Power consumption
- Cooling
- Noise - a manifestation of vibration. The reason this vibration, or harmonic ossilation can be a problem is nicely illustrated in the video "Shouting in the Datacenter"
- Stability – the physical problems of keeping such a fast moving object stable enough so that data can be read/written reliably.
The speed of rotation may influence the performance for throughput, particularly in sequential activity however it does not address the performance challenges with random seek activity. This means that increased storage performance will not come from higher rotational speeds in hard disk drive technology.
IOPS = Input/Output Operations per Second
IOPS are a measure of the frequency of requests made to the storage subsystem. The stated IOPS capacity of a drive is for a zero-byte file and is to provide a reference point for drive comparison. It is not a guaranteed figure. It is analogous to the manufacturer's MPG figure for a car; indicative rather than actual. The actual IOPS that can be achieved depends on a number of factors
- Read access vs write access
- Sequential access vs random access
- Position of the file on the disk (see Short-stroking below)
In order of performance (best to worst) the access patterns are as follows:-
- Sequential reads
- Sequential Writes
- Random reads
- Random writes
The biggest storage performance drain comes from a write biased mix of random read/write activity.
Sortstroking and Over provisioning
Over-provisioning
In a high load transaction system it is not uncommon to see the throughput requirements exceed the ability of a disk to fulfil the requirements.
Consider a 500GB database with a performance requirement of 3,000 IOPS.
- 1 x 300GB drive can deliver 150 IOPs
- 3,000 = 20 x 300GB drives
- Resilience using RAID 1 means that 40 drives are used
- 40 x 300GB =12TB.
In effect to support a 500GB database 12TB of SAN storage is effectively consumed. Where it is necessary to provide spindles to supply performance with capacity beyond that of the data residing on those spindles this is known as “over provisioning”.
Looking at the same example using 1TB disks the wasted storage becomes significantly worse
- 1 x 1TBB drive can deliver 75 IOPs
- 3,000 = 40 x 1TB drives
- Resilience using RAID 1 means that 80 drives are used
- 80 x1TB =80TB.
However many disks are needed to supply the required IOPs they have to be housed, powered, cooled etc.
Short-stroking
With any rotating circular object the outside of the object will always be moving faster than the inner tracks. In addition there are more sectors in the outside tracks than there are in the innter tracks. This means that data recorded on the inner tracks is read much more slowly than data at the outer tracks.
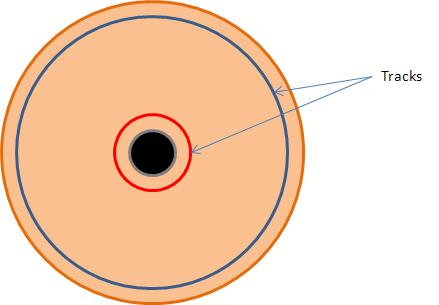
As a drive fills its performance can significantly reduce as a consequence By deliberately limiting the use of the drive to the out tracks the data throughput performance can be increased significantly however the inevitable result is greatly reduced capacity.
Implications of short-stroking and over-provisioning
The inevitable consequence of short-stroking and over-provisioning is that many more disk drives are used than storage capacity would indicate. These require physical space, cooling and power within the data centre with the inevitable cost implications.
Beyond that there is the increased possibility of one or more disks failing. If there are more disks then there is more chance that one or more will fail.
Are SSDs the solution?
Solid state disks have no moving parts and so do not face the physical constraints that govern hard disk performance. Performance is typically in the 10,000 IOPs range though solutions such as Fusion-IO deliver in the 100,000 IOPS to 1 million IOPs. In fact Fusion-IO have a 1 billion IOPs solution!
At this level of throughput over-provisioning effectively becomes a thing of the past. This has major benefits in the following areas: -
- Fewer units
- Overall reliability
- Floor and rack space
- Cooling
- Reduced power consumption both per unit and number of units plus reduced cooling requirement.
Cost and capacity of SSDs
SSD drives have two main disadvantages
- Relatively expensive in terms of £/GB
- Relatively low capacity.
However, the capacity throughput is such that the cost savings made in the areas mentioned above may be sufficient to offset their high price. This is particularly true when data centres and/or SAN storage is reaching its capacity and extending that capacity has a high price tag.
SSD vendors continue to innovate and the results of this innovation are:-
- Capacities are increasing
- Performance (already a key selling point) is increasing
- Costs are reducing
It is likely that the balance between HDD and SSD for these factors will reach a tipping point in the next 18 months which will result in rapid phase out of traditional HDD technology in the consumer arena. For the enterprise sector matters are complicated by the huge amount of legacy hardware and also the plants and factories whose livelihood depends on manufacturing traditional hard disks.
Lifetime of SSDS
The cells within an SSD can only be written to a finite number of times before it becomes “burnt out”. In the early days of SSD technology high cost plus the limited lifespan of the technology was a major detraction from SSD adoption. The burn-out occurs because resetting the gates in the solid state memory requires an ever increasing voltage. Eventually the voltage that would be required is too high so the cell is marked read only.
At the time of writing (April 2012) longevity has largely been addressed with certain caveats. Some older hard disk controllers are geared up with the expectation of a physical hard disk drive being attached and are aware of the limitations of that drive. They make some effort to place the data intelligently on the drive. Taking this on an SSD drive in effect biases the write mechanism to repeated use of specific cells thus accelerating burn-out.
Fusion-IO contains its own controller and therefore takes account of the different nature of SSD technology to prevent premature burn-out. Fusion-IO claim that a 1TB card would have to be written in entirety 5x per day for 5 years before it suffered burn-out.
Performance of SSDs
The ultra-high performance of SSDs will not necessarily be a pain free implementation. If the architecture of storage solution is predicated on the use of hard disk drives then the performance characteristics of SSDs can overload them. This is analogous to putting a 500bhp engine in a family hatchback without considering the need for better suspension, tyres and brakes. The extreme performance can over-whelm the CPU leading to CPU stalling.
Similarly placing SSDs within a SAN can quickly lead to the cache partition being overwhelmed. Another point that must be considered is the infrastructure surrounding the SSD. If the SSD is simply treated as a straight swap out for a traditional hard disk then the power of the SSD will probably be blunted by the limitations of the sub-systems surrounding it.
SSD Location
From a management perspective administering storage from a central point is highly desirable however the touch points with that central point can be the bottleneck in the system. Having localised storage reduces the central bottleneck but the penalty is complexity from a management perspective.
There is also the consideration that in clustered SQL Server environments (prior to SQL 2012) localised SSDs are not an option as the storage for that cluster must be in the shared quorum for that cluster. From the presentations I have seen so far (SQLBits, SQL Relay 2012) and what I have read SQL Server 2012 "always on" is a hybrid of clustering and mirroring and therefore opens up the option for the separate nodes to be able to use their own TempDB thereby opening up the door for SSD implementation for that purpose.
The anatomy of a SAN
Our SAN administrator described the anatomy of their SAN which I have captured in the diagram below.
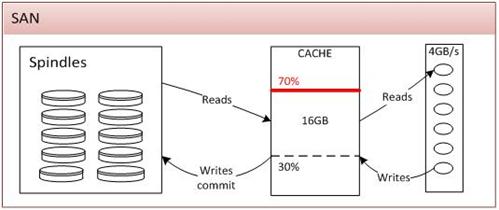
Part | Description |
Spindles | These are the physical storage of data within the SAN. Disks can be arranged into “Disk Groups” and those groups ring-fenced for a particular purpose. Disk groups cannot contain mixed size hard disks; 1TB and 300GB disks cannot be mixed in a single group. Disk groups cannot borrow from each other’s capacity. There is increased wastage of capacity by ring-fencing storage in this way. |
Cache | This is known as “partition cache” and is shared between all users. Just like any other cache it is designed as a performance enhancer but also as a capacitor for write activity. 30% of the capacity of the cache is dedicated to write activity however this can increase up to 70% in response to demand. If demand reaches 70% then the SAN cannot guarantee that data can be committed to disk and will therefore refuse further IO requests. This is by design to protect against data loss. Fusion-IO has a similar concept where it is recommended that 2GB of RAM be provided per 80GB of Fusion-IO storage. If sufficient RAM isn’t present then in high write scenarios the Fusion-IO car will refuse writes, again to protect itself against data loss. |
Header Unit | Handles communication between the SAN and the outside world. Although SSDs can be put into the SAN the throughput is so high that only a limited number may be inserted before their throughput overwhelms the header unit. |
Cache Memory
Unlike other servers the SAN is not a commodity piece of hardware and so the costs of the components are very high. Solutions involving an increase in SAN capacity will also be extremely expensive. To give an example the 16GB RAM would seem to be a very small amount of RAM given the terabytes of data being managed. However 128 GB RAM for the SAN would cost a £six figure sum!
What is the advantage of a SAN?
In the time before Storage Area Networks we had direct attached and localised storage. Disks were small (36GB or 72GB) and to provide capacity and performance we needed a great deal of them. Managing the sheer number of disks was a nightmare. SANs came into being to address the management aspect of large data volmes and make it easier to provision storage and replicate data to provision against disaster. If you ask your SAN administrator about SAN replication you are likely to get a somewhat guarded response.
If over-provisioning is now no-longer required and always on architectures advocates local storage the question has to be asked "to what extent does the SAN satisfy the requirements of today's data"? Personally I think it will be just as Steve Jones once compared the evolution of SQL Server to Grandfather's axe. It's had 5 handle and 3 heads but it is still Grandfather's axe.
Data and storage
Understanding the nature of the data
A fundamental understanding the nature of data will allow a solution to be developed that is architecturally appropriate and compatible with the storage we have available.
That understanding should include the following:-
- Size of the data
- Growth of data
- Frequency and break down of CRUD activity on data
- Creating new data
- Read activity
- Update activity
- Delete/archive activity
- Location of data
- Transience of the data; is NOSQL appropriate?
- Resilience of the data
- Are multiple copies required
- What level of outage is permissible
- Business cyclic use of data
- Accessed for period (day, week, month etc) end reporting.
- Ebb and flow throughout the day
- Business use. What is the data actually used for?
- Concurrency of data, that is, the number of accessors of the data
- Retention periods
- Back up requirements
- Maintenance operational requirements
The nature of data will change
The nature of any piece of data will change depending on a number of factors
Factor | Effect |
|---|---|
Location |
|
Business / regulatory requirements | A dataset can be relatively transient supporting small back end processes but a change in requirements can promote it to mission-critical status requiring resilient hardware, extended retention periods and increased storage capacity |
Time | Data can sit dormant for a period of time suggesting that its performance requirements are low. That data can become highly active at key times of the year where its performance requirements are high. |
Migration/Upgrade | During a migration/upgrade data access will increase dramatically. This could be misinterpreted as a false positive whereas the change in access pattern is purely down to the migration process. |
System activity | Routine maintenance activity such as back up, database reindexing, archiving and purging can have a radical affect on the perceived access pattern for data. Although such activity is legitimate and its own access pattern should be considered it does need to be identified and isolated. |
Communicate, communicate, communicate!
If you have a good understanding of the nature of your data and the factors that will trigger a change then this is a piece of information that must be shared. If a SAN administrator is watching for IO activity and a sudden spike occurs due to a database reindex then the SAN administrator should know when such activity occurs.
Categorisation of Data
Category | Description |
|---|---|
Metadata | Meaningful descriptive information about information
Likely to be slow changing (almost static) |
Configuration data | Determines the mechanics of how an application works. Not necessarily in a DB. Location determined by appropriateness to solution. Mainly read, rarely changed, should be cached. |
Reference data | Slow changing data usually visible to the customer such as airports, salutations, product sets on data driven channels. Often defined externally by a standards body. In OLTP environments usage is similar in access pattern to configuration data In DW environments reads are frequent as this provides context for information. |
Operational data | Data generated by applications as part of their normal operation. Event and audit logs. Rarely if ever read by the generation device. Should be streamed sequentially. In the case of event logs the separation of the different severity levels of message is an important consideration. The nature of the way in which data is accessed suggests that storing this information in a traditional RDBMS may not be the most suitable approach. |
Persistent data with known life cycle | Customer behavioural information such as enquiries and applications. Web analytics Retention period on the web site is determined by the business functionality. Back end operations should be heavy readers of this information. Purge/Archive activity likely to take place periodically. There needs to be consideration as to the most appropriate place to record such information. Assuming that the data is required at all then the questions that have to be asked are as follows:-
|
Persistent data with indeterminate lifecycle | Data for which the lifecycle exists but cannot be predetermined either by business or regulatory requirements. Principal example is a “Customer” |
Backup/Archive | Data that can be recovered in the event of data loss. Absolutely must not be lost. Largely sequential in nature. High volume requirement |
Transient data | Data that goes through a transformation process or flow but is not retained either at all or in its untransformed state. SQL Server distributors, NOSQL solutions, queues etc. |
Command Query Responsibility Separation (CQRS)
In the application world there is a design pattern CQRS. This is nicely described by Martin Fowler in one of his blogs. The gist of it is that rather than having a single huge monolithic application handling all aspects of all interaction the application is made up of separate components in such a way that the components and/or services that have a responsibility for maintaining data are separate from those that read data.
Harking back to the Platonic solids at the start of this article good communication between storage/infrastructure guys, data guys and application guys can really capitalize on CQRS design patterns for the benefit of all!
- Application people can give their components/services the ability to have many connection strings
- Data people can capitalize on that connection string facility to scale out their databases so read activity can be separated out
- SAN people can capitalize on this by providing storage targetted at the particular measurable access patterns
Understand your application and its affect on storage
As DBAs you know how SQL Server works but does your SAN administrator know? If not then it is the DBA's responsibility to share the knowledge
The facts that will be interesting to a SAN guy will include the following:-
- TEMPDB will suffer intense random activity
- Other system DBs will be read frequently but not necessarily written to heavily or at all.
- Log files are sequentially written, but sticking 2 or more on the same drive effectively creates random writes.
- Filegroups can be placed where we want
- Distribution databases behave in a particular way.
- User databases will behave in a (generally) predictable manner.
- ...etc
Monitoring
It is clear that applications and their dependent database must be designed not just so they can be monitored but designed in such a way that monitoring is part of their core functionality.
- Identify the categorisation of data
- Identify the access pattern for data
- Assign data to units of storage (disks, files) according to the information identified above
- Design applications and databases to allow core data subject areas to be moved in order to facilitate monitoring
- Tables
- Indexes
- Files (irrespective of whether they are database files or not).
SAN monitoring
From an IO perspective the SAN can be monitored at the disk level.
- Physical disks/spindles within the SAN
- Virtual disks presented to servers
Database monitoring
There are a range of methods that can be used to monitor the stresses and strains on a SQL Server database
- PerfMon counters
- Data Management Views DMVs
- sys.dm_io_virtual_file_stats.
- sys,dm_db_index_usage_stats
- sys.dm_missing_index
- 3rd party tools such as SQL Monitor.
- Event logs
Data available using 3rd party tools is generally available in PerfMon statistics and DMVs but the tool encapsulates, calculates and presents the statistics in a form that is easily understood and unambiguous.
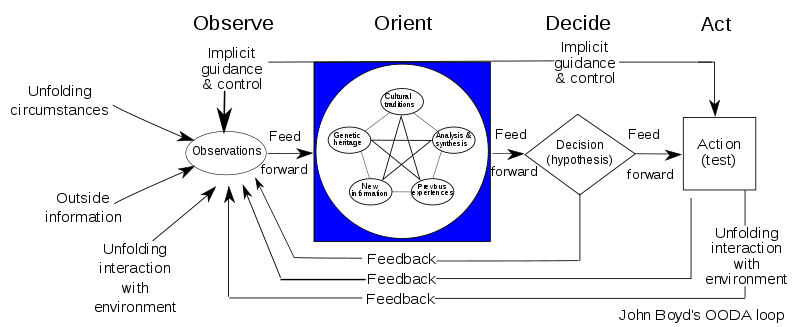
Observe, Orient, Decide and Act
Of course there is no point having monitoring without a process in place to act on the information provided by that monitoring. Once again, all participants in the first Platonic solids diagram need to work together to implement the IT equivalent of the John Boyd OODA loop as described on Wikipedia.
Done correctly this means that not only is an application capable of being refactored but so to can each element (data, application, infrastructure and business process) and each element can be designed to support the refactoring of the others.
Concluding thoughts
I started my journey knowing very little about storage other than the size of hard disks. Now I am firmly convinced that Denny Cherry's original observation is extremely important.
The Microsoft FastTrack data warehouse appliance is an excellent illustration of how commodity hardware can deliver astonishing performance when the database and data is designed and loaded in sympathy with that hardware.

