

If you haven't already, you might want to look at the two previous articles
I've written recently on replication (Snapshot
Replication and Getting
Ready to Replicate) that set the stage for this one. This week I'm going to
return to snapshot replication, discussing how to do a basic implementation and
pointing out some of the more interesting points along the way. Snapshot is a
great way to start learning replication before moving into the more complicated
areas of transactional and merge. For this article I'm going to replicate
Northwind from one named instance to another. You can of course replicate to
another server or even to a different db on the same server.
Just to be clear before I start, snapshot replication is generally a way to
provide a read only copy of the data to one or more subscribers. Updates on the
publisher are not sent over, you have to send a whole new snapshot to refresh
the subscriber. One possible use for this is lookup tables that rarely change.
Using Enterprise Manager (SQL2K), here is where we start:
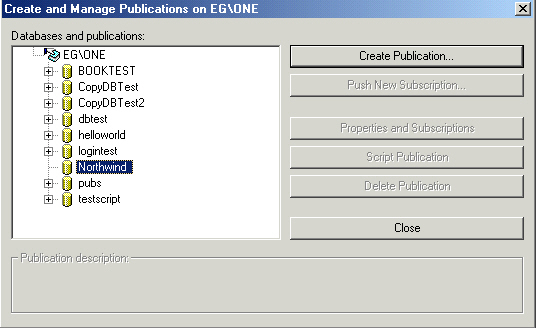
Pick the database name that will be the source (though it doesn't matter, you
get the option to change a few clicks further along), then click Create
Publication.
Which starts the publication wizard. Replication consists of two parts,
publications and subscribers. Publications define who and what data will be made
available to subscribers, while subscribers can then...subscribe!...to get a
copy of the publication. Really a pretty clear metaphor for what happens. I've
selected advanced options so we can see the additional choices you can make, for
a very basic publication you can leave it unchecked of course.
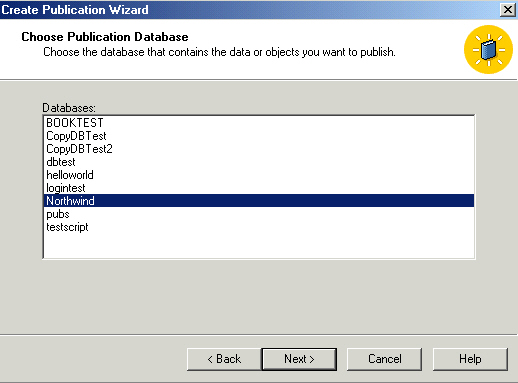
Told you! Get to pick the database again.
Here are our choices. We'll go with door #1, snapshot replication.
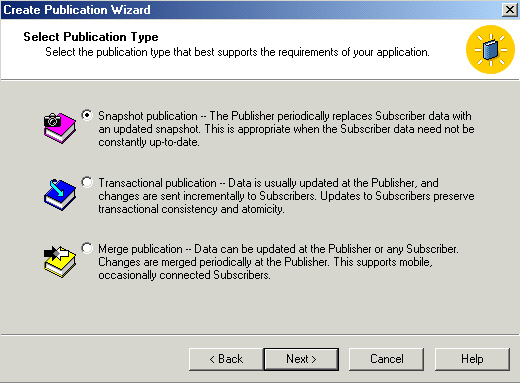
Now here are two VERY cool options we'll wait to explore further until next
time. While we think of a snapshot as being a read only copy (because changes
would be lost when the next snapshot is issued), by using one or both of these
options we can let users write to the subscriber, then have those changes posted
back to the publisher.
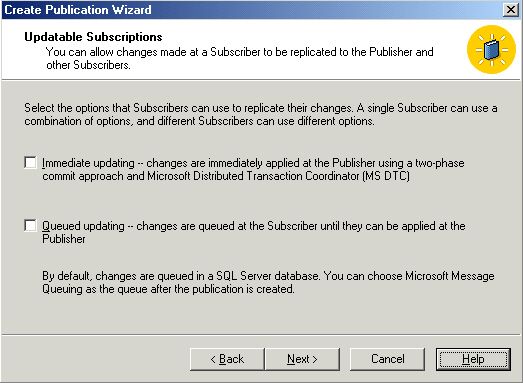
Another interesting option - we can use DTS to transform the data. Definitely
an advanced option, this can be used in any way you think to write code. A not
very good example might be that while you represent prefix, first name, and last
name as separate columns in your contact table on the publisher, you want to
treat it as one column on the subscriber, so you define a package to concatenate
and format the data as it's sent to the subscriber. Something else we'll return
to in a later article.
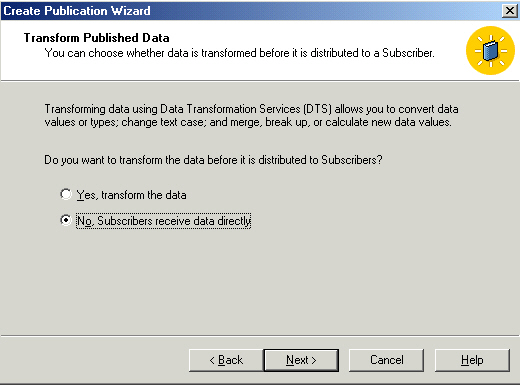
Here I usually only select what I need, in this case SQL2K. In a follow up
(sorry to keep saying that, but too much to cover in one article!) we'll send a
snapshot to Access to see how that works.
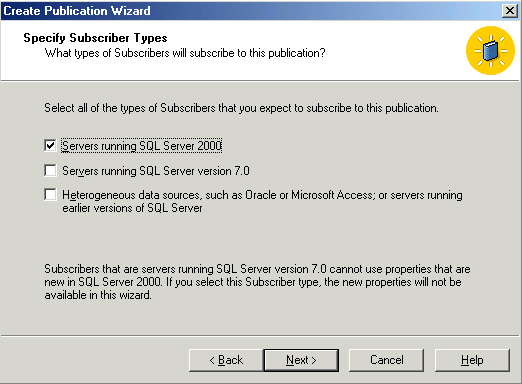
This is where we do the real work. You can select whichever objects you need
to send to the subscriber and in later steps, even apply filters. I don't
normally replicate stored procedures for snapshot replication (more useful in
transactional in my opinion) but if you need them on the subscriber (perhaps
because you're selected the updateable subscriber option a few steps back)
select them. Views are more likely to be needed.
A huge point in building your publication is to think about the impact that
running the snapshot will have on the publisher and the subscriber. Every time
you run the snapshot job it will lock the tables while it BCP's the data out. On
small tables your users will never notice, on large tables it can take long
enough to bring operations to a halt. It's nice to have one publication that
contains everything, but it's often more practical to define one publication for
all the small tables, separate pubs for each of the larger tables. Another twist
might be to put all the tables that change frequently in one pub, ones that are
more static in another. Issues caused by the table locking can be minimized by
running the snapshot off peak, but I'll warn you now - sooner or later you'll
need to do it during the day!
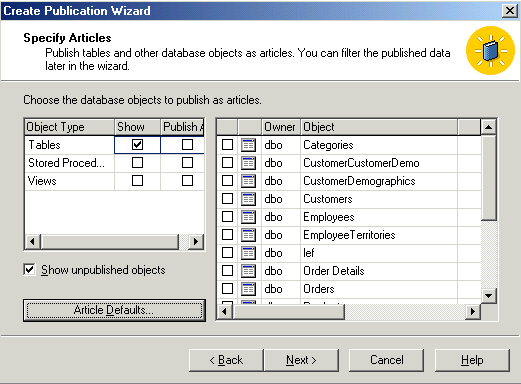
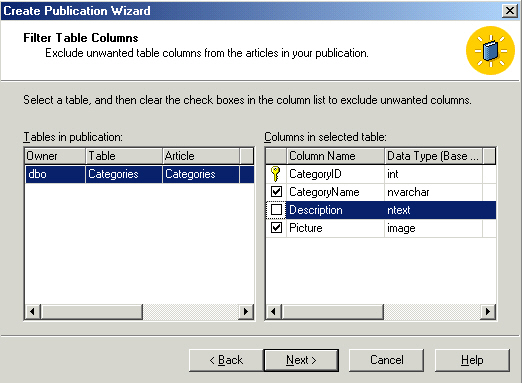
To keep this simple, I'm just going to replicate the categories table. Can't
see it in the image, but I've checked the box to the left of it. The button to
the right holds some interesting prospects as you'll see in the following image.
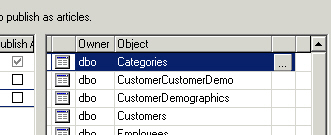
Destination owner is something you really want to consider. It
defaults to being whatever the owner is on the publisher. I keep all objects
owned by dbo so that works for me. Even if not owned by dbo, it might make sense
to preserve the same owner on the subscriber. Might not. If you need to change
it, this is the place.
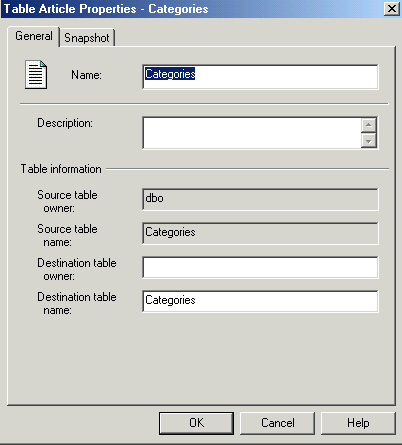
Here is the other tab. The default behavior of a snapshot is to drop and
recreate the table each time along with the indexes and primary key. In a lot of
cases this makes sense, as you make schema or index changes on the publisher,
the next time you snapshot the subscriber gets the changes. Keeping the existing
table unchanged will save you some disk/network io if you KNOW the contents
won't change. State look up table maybe? Deleting data that matches the row
filter is interesting. This would let you push over the data you want, yet leave
other data in place. This can get a little weird if you ask me! Never had a need
for it yet. The delete all data option is nice if you want to preserve
schema/index changes made on the subscriber, I guess also saves the minor
overhead of dropping/creating the object each time.
I hardly ever write to a snapshot copy, so RI and triggers are usually not an
issue. If you're doing updates AND posting them back, they become much more
important. Converting user defined types to base types saves having to add your
user defined types to each subscriber. I'll confess to not using UDT's very
often, doesn't seem like it's much work to add them to the subscriber if you
need them.
Click Ok, Next, brings you to this warning window. I've selected at table
that contains an identity col AND make the publication not updateable. Identity
columns on updateable subscribers will give you a large headache, more next time
(or the time after maybe!). In this case clicking next is all we need to do.
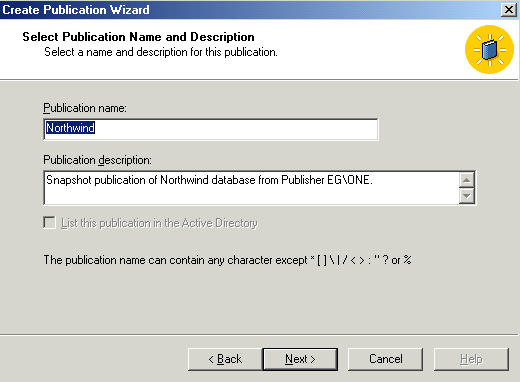
A good name is worth a minute. If you only have one pub, I just use the name
of the database. If more than one, I might use 'Northwind-SmallTables' and 'Northwind-LargeTables',
something to let me see the purpose rather than the content. I rarely use the
description block and just leave the default. The option to list in Active
Directory is grayed out because I'm working at home (not on a domain). Listing
in AD is a gee whiz feature as far as I can tell! Most subscribers are either
set up by the DBA or told by the DBA what to click, not many head out to AD to
see what is available.
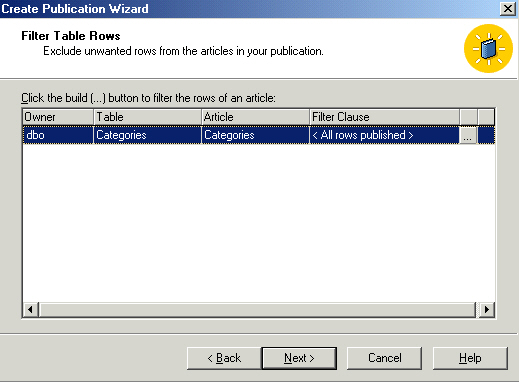
Just to keep it interesting we'll define some filters.
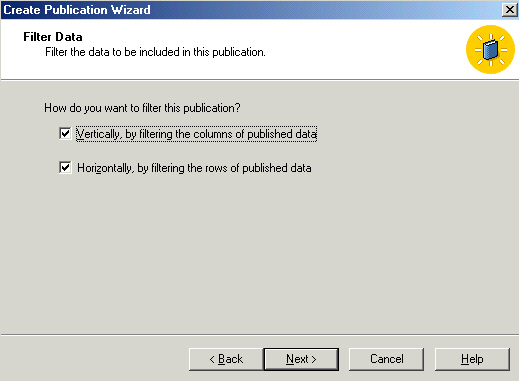
Both horizontal and vertical filters will be applied - configuring both the
select (defaults to all columns) and the where clause (defaults to all rows).
Columns are easy, just check/uncheck to meet your needs. Note that you have
to replicate the primary key. I don't know when it would make sense not to
replicate it, but as long as the subscriber is not updateable it wouldn't
matter. Just live with it!
Next is rows. For each table you need to filter, click the little box to the
right.
Part of it pre-populated, I just typed in the 'categoryid > 5' part.
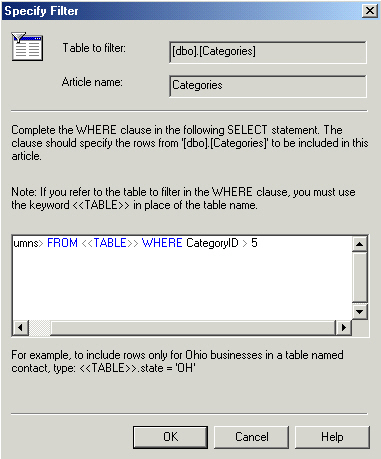
Click ok to see the updated display.

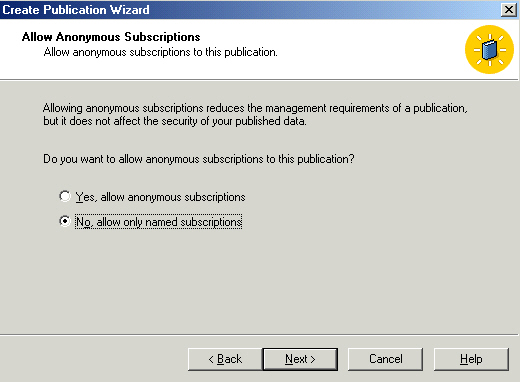
Books online gives the following reasons for allowing anonymous subscribers -
you have a large number of subscribers, you want to eliminate the extra overhead
of maintaining the subscriber info on the publisher or distributor, or you have
subscribers that will use the internet. Obviously if you allow anonymous
subscribers you're giving up control of who sees the data. Not always bad, but a
choice to be made carefully. We'll with named for now.
Almost done with this part, we can now configure how often the snapshot agent
(a SQL job) runs. The default is once a day. Remember the warning about table
locking, pick a time that will cause the least problems.
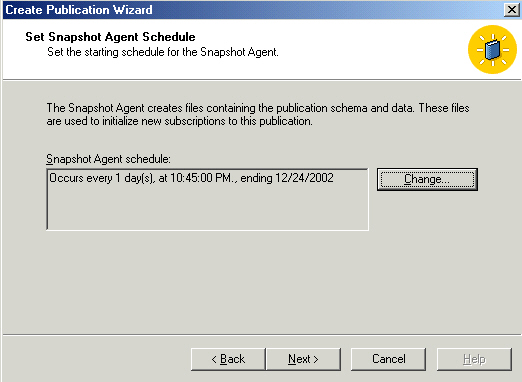
Click Next and you're almost...done! Click close and you'll have successfully
created your publication.
Back in Enterprise Manager you'll see that the database icon has changed,
plus you now have a Publication folder containing the Northwind publication we
just created.
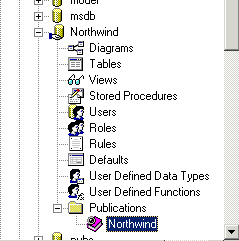
You can now delete the publication by just right clicking it and selecting
delete. I know that seems like a lot and we still haven't pushed any data to a
subscriber, but once you run through it a couple times it becomes pretty fast
and intuitive. Next time we'll push this publication to a subscriber, then
explore some of the other options I had to gloss over this time. Too much
detail? Not enough? Rate the article and add a comment, contribute to the
discussion!