

Introduction
How many times have you wished to have some basic information about all your servers at your fingertips? If you are like me, this happens quite a bit.
I work for a software company where my colleagues and I are responsible for a modest farm of SQL Server 2000 and 2005 servers. In order to serve the needs of our developer community more efficiently, we needed to gather up some basic information on all our servers. Further, it would be best if the data could be accessed quickly by everyone on the team. The question was, how to do this and present the information in a way that the team, or others, could see easily. Of course, it would help if we didn't need to buy some type of package.
The solution? Use the tools we already have at our disposal: SQL Server's ability to use Distributed Transaction Control, built in scheduling and Reporting Services. This enabled us to build a simple data gathering framework with data that is viewable from a browser within our network.
Push or Pull
At our location we co-located the report repository and the SQL Server Reporting Services functions onto one server. To enable statistics gathering, we could use either a Push or Pull model. In a Push model all of our servers would report their data to a common repository. The advantage of this model would be that if a server pushing the data failed, it wouldn't impact the common repository. The disadvantage would be that it would entail greater administration around the scheduling of the push. In the Pull model, one server would schedule and pull data from all of the others. The advantage here would be to decrease the administration burden. The disadvantage, of course, would be that if a server failed while gathering the data we might skip gathering for that scheduled pull.
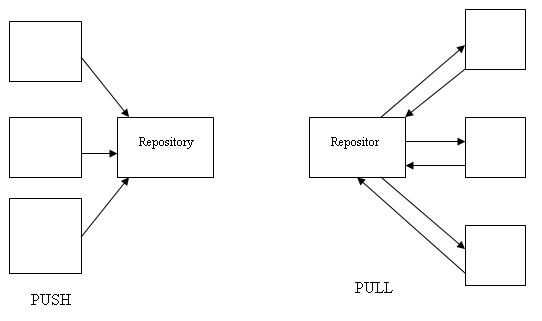
Since we do not have frequent outages we decided on a Pull model to focus the administrative burden on one server.
Setup
Once this decision was made, the following prerequisites were needed to support the model:
- SQL Server 2005 with Reporting Services to act as a central repository.
- Enabled Microsoft Distributed Transaction Controller on all servers involved.
- Create database links to all servers from which data will be pulled.
As our initial requirements were for simple data, we run either Microsoft supplied stored procedures or home grown ones to populate the repository. A job is scheduled to run a stored procedure whose data is returned in a result set that is subsequently stored on the repository server.
Each scheduled job would need to know which servers to pull data from. For that, a table was created that would store the server name and a switch.
CREATE TABLE article_servers(
dbserver sysname NOT NULL,
oksw int NULL
) ON [PRIMARY]
GO
INSERT INTO article_servers (dbserver, oksw)
values('SERVER1',1)
GO
INSERT INTO article_servers (dbserver, oksw)
values('SERVER2',0)
GO
INSERT INTO article_servers (dbserver, oksw)
values('SERVER3',1)
GO
The switch column, OKSW, can be used to skip processing that server for the data gathering operation. In the above SQL, SERVER2 would be skipped when checking for servers to process as each job would select all servers where OKSW = 1. The job will then loop through this list executing the stored procedure on each target server in turn.
Where's the space?
One of the original drivers for this process was a need to determine quickly who might be consuming space on our farm. In order to accomplish this we created a stored procedure that acts as a poor mans SP_HELPDB. This procedure loops through the databases on a server, avoiding the
Microsoft supplied ones, gathering state type information such as those gleaned from a DATABASEPROPERTYEX function. Additionally, it sums up the space consumed by each database and saves it in a temporary table. The stored procedure was created on each server we needed data from and returns this data in a result set.
On the repository server we created a table that parallels the result set returned by the stored procedure. That table is then populated by a scheduled job that runs nightly on the repository server. This job loops through the server table shown above and calls the space stored procedure.
As each result set is returned, it is added to a temporary table that is then inserted to the repository one.
Since this stores data in a historical fashion, a subsequent step in the job purges data older than a configured number of days.
This job has enabled us to present data in a number of different ways regarding space utilization and database status info that would have taken logging on to all servers to satisfy before. Some example reports are shown in the following figures.
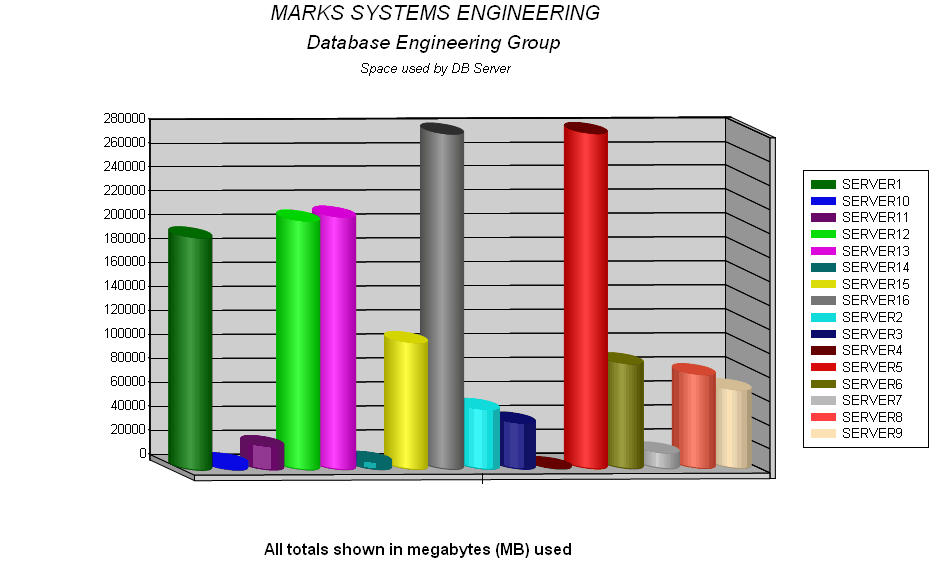
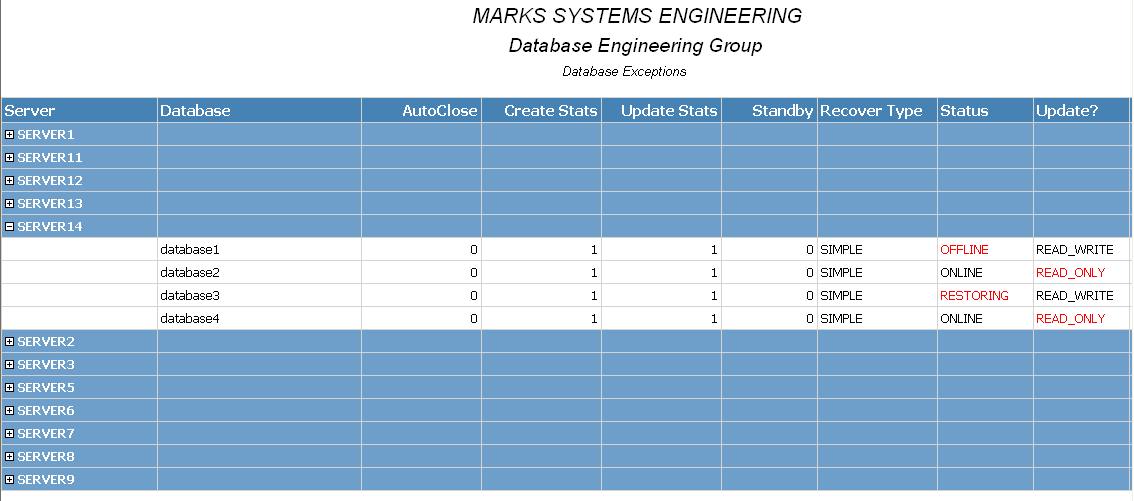
Software Version
In this example, we wanted a consolidated list for management of what software was running on which server. This is for a text report that demonstrates just how simple this process could be.
We created a stored procedure that runs one select on each server.
create procedure [dbo].[article_getsoftware]
as
begin
select getdate(),
cast(serverproperty('machinename') as varchar(20)),
cast(serverproperty('productversion') as varchar(20)),
cast(serverproperty('productlevel') as varchar(20)),
cast(serverproperty('edition') as varchar(40))
end
Using the same batch job framework, we scheduled a job that loops through the servers executing the above stored procedure. In this case, only changed information is saved.
This results in a simple text based report
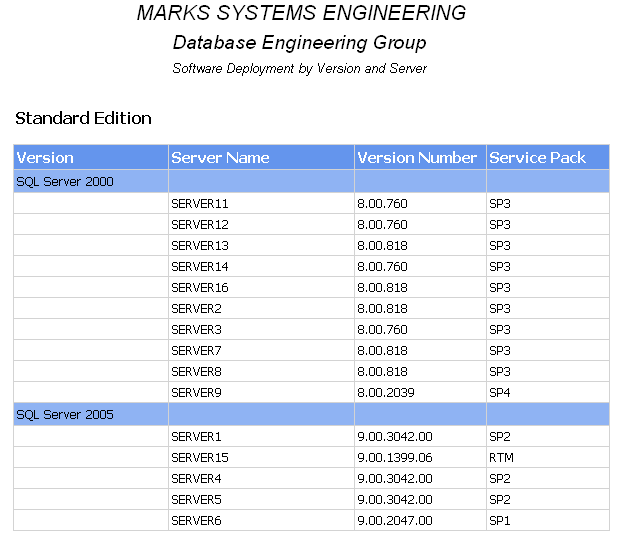
Conclusion
Although we have only scratched the surface at my company, we have already fielded a number of administrative reports that can be viewed anytime. So far after deploying only a handful of batch jobs for gathering data, we have reports around database state, free space, space consumed, largest consumers and software deployment. This enables us to make some common decisions faster which allows us to return some of that time back to our development community.
With this simple framework and the tools you already have, you can free yourself from some of your administrative research. In addition, you'll have clear state information on your server farm for management use.
In Part 2, I plan on providing more detail around the space consumed process described above.
