

The Problem
Once upon a time Mr. Francois Ansee, SQL guy extraordinaire, wanted to get a list of his customers.
The catch? They had to be sequentially numbered, in alphabetical order by CustomerID.
It's one of the most basic tasks a SQL guy (or gal) will face, and in prior versions of SQL Server, the choices could be
frustrating. Let's consider Francois' problem and look at some possible solutions in SQL 2000. Here's the result our
intrepid SQL guru is looking for:
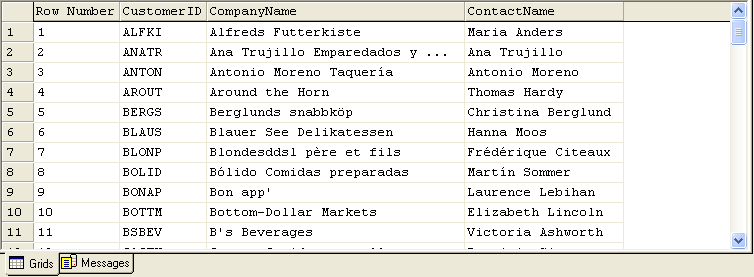
One of the first solutions to present itself is also the simplest. Francois can simply add an IDENTITY column to the
Customers table to automatically generate numeric values. There are several downsides to this method:
- The values inserted might have gaps in them. SQL Books Online specifies that this is an issue for
"tables with frequent deletions"; however, I have also identified the gap issue as a problem for tables
where multiple INSERT statements are running simultaneously.
- If Francois deletes all the rows from the table, the IDENTITY column does not start counting from 1 when new rows
are inserted.
- If Francois wants his customer list sorted by ContactName instead of CustomerID, his IDENTITY column numbers
will display all out of order.
- Company policy might not allow "quick and dirty" changes to tables in production databases.
Another option for Francois is to create triggers to generate sequential numeric values and store them in the table
at insert time. Using this method he can also compensate for gaps between values. This can cause a performance hit
and can become complex. Add this to the fact that Francois does not like to work any harder than he has to, and we can
safely move on to the next option.
Francois could use a cursor and a counter variable to iterate the rows one-by-one. Francois prefers set-based solutions,
and he avoids cursors.
Our SQL guy now has three fewer solutions than he started with. He finally decides on a classic self-join with the
SQL COUNT(*) aggregate function. To generate the results above, using the Northwind sample database, Francois uses
the following query:
|
This method consistently generates proper sequence ranking for your table, it is 100% set-based, and it can easily be
modified to sort by ContactName (or any other column) instead of CustomerID. The downside to this method is that
self-joining a very large table can be resource-intensive and hurt performance.
SQL 2005 to the Rescue
The SQL Server team has introduced several new features in SQL 2005 to make short work of numbering problems like this.
In particular, to deal with this exact problem they’ve added the ROW_NUMBER function. Let’s say that Francois now
wants to list all the contacts in the SQL 2005 AdventureWorks sample database, with the rows numbered sequentially. He
could use the following query:
|
To get these results:
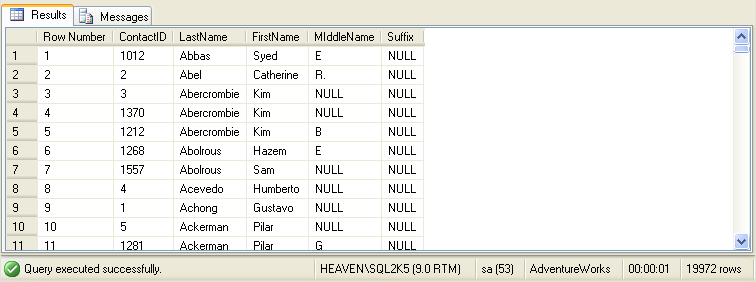
Let's look at the ROW_NUMBER function's format for a moment:
ROW_NUMBER() OVER ([PARTITION BY value_expression, ...] [ORDER BY column, ...])
The OVER clause is the key. It allows you to specify an ORDER BY clause to determine the order of counting. In
the example, we are specifying that the rows will be numbered sequentially in LastName, FirstName, MiddleName sort order.
The optional PARTITION BY clause specifies a partition, after which the row numbering re-starts. If we modify the query
above to include a PARTITION BY LastName, row numbering will re-start after each new LastName in the table. Our modified
query looks like this:
|
And here are the new results:
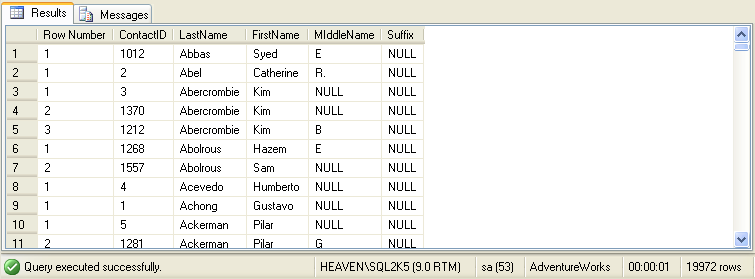
Notice how the PARTITION BY clause forces the row numbers re-start at 1 each time the LastName changes.
Enter the Sales Team
The members of the sales team at Adventureworks are constantly asking Francois to run queries against the data in the SQL
database. Sometimes they ask for simple queries, like a list of all customers who placed a single
order larger than $1,000. Other times they ask for more complex results, like a list of all the best sales days (in terms
of $$$) for 2001. For the latter query, our high-speed SQL guru decides to use the new SQL 2005 RANK function:
|
The RANK function is similar in syntax to ROW_NUMBER, but it serves a slightly different purpose. RANK numbers rows
like ROW_NUMBER but it assigns the same row number to rows in the event of a "tie." You can see this for
yourself in the results of the query above:
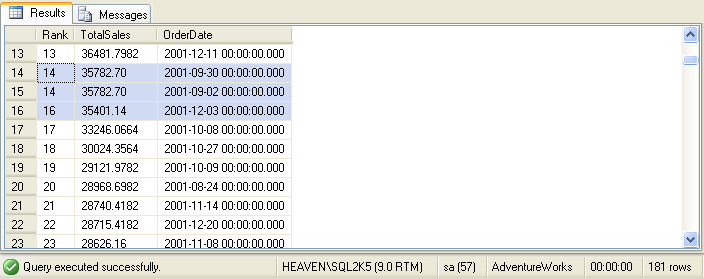
Notice that days with the same total sales display with the same rank number, and the rank numbers jump after a
tied result. In this example, the rank jumps from 14 to 16 because of the two-way tie for the 14th position.
DENSE_RANK is a variation of the RANK function. Unlike RANK, the DENSE_RANK function doesn't jump after a tied
result. Here is the query above using DENSE_RANK:
|
And here is the result:
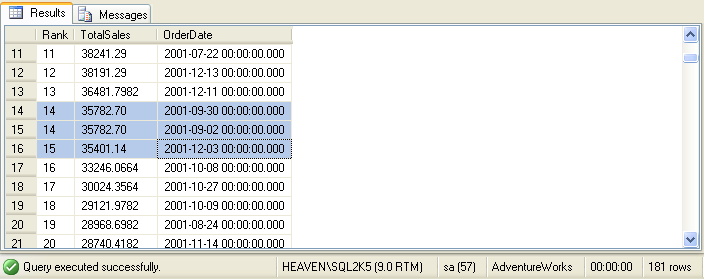
After the two-way tie for number 14, DENSE_RANK continues counting sequentially with 15.
Even More Complex Numbering
SQL Server 2005 adds another function called NTILE. This function divides your result set into a specified number
of groups (roughly) equal in size. The format to use NTILE is similar to the other ranking/numbering functions,
except that you also specify the number of "tiles" to divide your data into. For the example, we'll use
an even more complex sales report. This time the sales team wants a report that divides up the sales territories into
4 quartiles, based on total sales:
|
This query produces the following result:
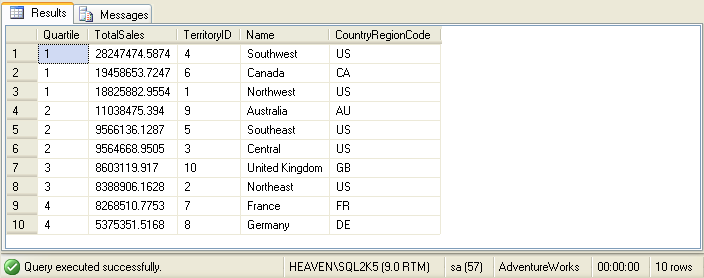
If you look closely at the results, you will see that the first and second quartiles have 3 rows each, while the third
and fourth have two rows each. Since our total number of rows does not divide evenly into 4, the top quartiles are
expanded slightly to hold more rows.
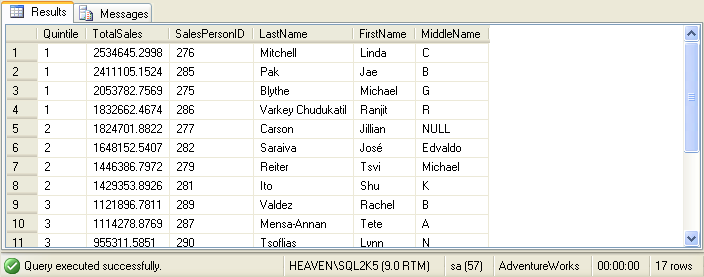
Of course NTILE does not have to specify "quartiles" (1/4ths). Here is another sales example, which divvies
up the sales team into "quintiles" (1/5ths) based on total sales:
|
Conclusions
The SQL Server team has added new functions to SQL Server 2005 to make it easier to perform common row-numbering tasks,
including ROW_NUMBER, RANK, DENSE_RANK and NTILE. These functions make row numbering tasks easier than ever.

