

Azure Data Factory (ADF) is a cloud based data integration service that allows you to create data-driven workflows in the cloud for orchestrating and automating data movement and data transformation. Azure Data Factory does not store any data itself. but it allows you to create data-driven workflows to orchestrate the movement of data between supported data stores and the processing of data using compute services in other regions or in an on-premise environment. It also allows you to monitor and manage workflows using both programmatic and UI mechanisms.
The Azure Data Factory service allows you to create data pipelines that move and transform data and then run the pipelines on a specified schedule (hourly, daily, weekly, etc.). This means the data that is consumed and produced by workflows is time-sliced data, and we can specify the pipeline mode as scheduled (once a day) or one time.
The pipelines (data-driven workflows) in Azure Data Factory typically perform the following three steps:
- Connect and Collect: Connect to all the required sources of data and processing such as SaaS services, file shares, FTP, and web services. Then, move the data as needed to a centralized location for subsequent processing by using the Copy Activity in a data pipeline to move data from both on-premise and cloud source data stores to a centralization data store in the cloud for further analysis.
- Transform and Enrich: Once data is present in a centralized data store in the cloud, it is transformed using compute services such as HDInsight Hadoop, Spark, Data Lake Analytics, and Machine Learning.
- Publish: Deliver transformed data from the cloud to on-premise sources like SQL Server or keep it in your cloud storage sources for consumption by BI and analytics tools and other applications.
Dynamic Pipelines
During the recent project I implemented at one of our prestigious clients in the manufacturing space, I encountered a specific requirement to ingest data from 150 different sources. Creating separate pipelines for each data source will end up creating 150 ADF pipelines and that could be a very complex maintenance effort post-go-live. I did a lot of research and came up with a design to configure Dynamic Pipelines, which means that every data set would run through the same pipeline.
To logically design the lifecycle of a dataset from source to the destination inside a Synapse table, I planned to configure 3 pipelines that do the all the data processing to ingest data into Synapse. As a result, all 150 data sets were able to get processed within just 3 pipelines. This is a very sophisticated technical configuration, and I neither find it anywhere on the internet nor in any books. I would like to share this knowledge and experience gained so that anyone who is trying to implement something similar can design the best industry solution which is robust, maintainable, and re-usable. This impressed my client team, so here we go.
Business Requirement
Let me first talk about the business requirement. There are around 150 different sources of Point-of-Sale data from different online retailers like Amazon, Home Depot, Way Fair, Lowes, etc. Business users used to go to each point-of-sales platform to download the data for analysis purposes. For example, they collected data for these purposes:
- how many customers browsed their product on Amazon, Home Depot, or Way Fair platforms
- how long customers were on the website
- how many products customers added to the cart
- what other products customers added to the cart
- did the customer end up buying all of them or did they abandon the cart.
For all such kinds of analysis business users had to go to each platform separately. Not only that, after downloading the data they had to apply multiple business logic to convert that data into some meaningful information.
The intent of this project is to bring all this data from all different sources into one platform and apply the business logic as well before the business team access and create their reports. The Microsoft Azure Platform was chosen by the customer due to the latest and greatest cloud technology features like Azure Data Factory, Data Lake, Synapse, Logic Apps and Power BI services, etc.
One of the major components implemented in this project is Azure Data Factory. Azure ADF is used to pick the datasets from multiple sources, which are in a very unstructured format. These datasets pass through the Azure ADF pipelines to convert the data into a structured format and to apply business logic. Finally, via Azure ADF, this data is moved into Synapse and Data Lake where business users can access this data via the Power BI service.
Dynamic Azure ADF Pipelines
To save a lot of maintenance effort and also the development time, I came up with a unique solution design to create dynamic ADF pipelines. All 150 datasets pass through one single pipeline dynamically. Here is the high-Level Solution Architecture:
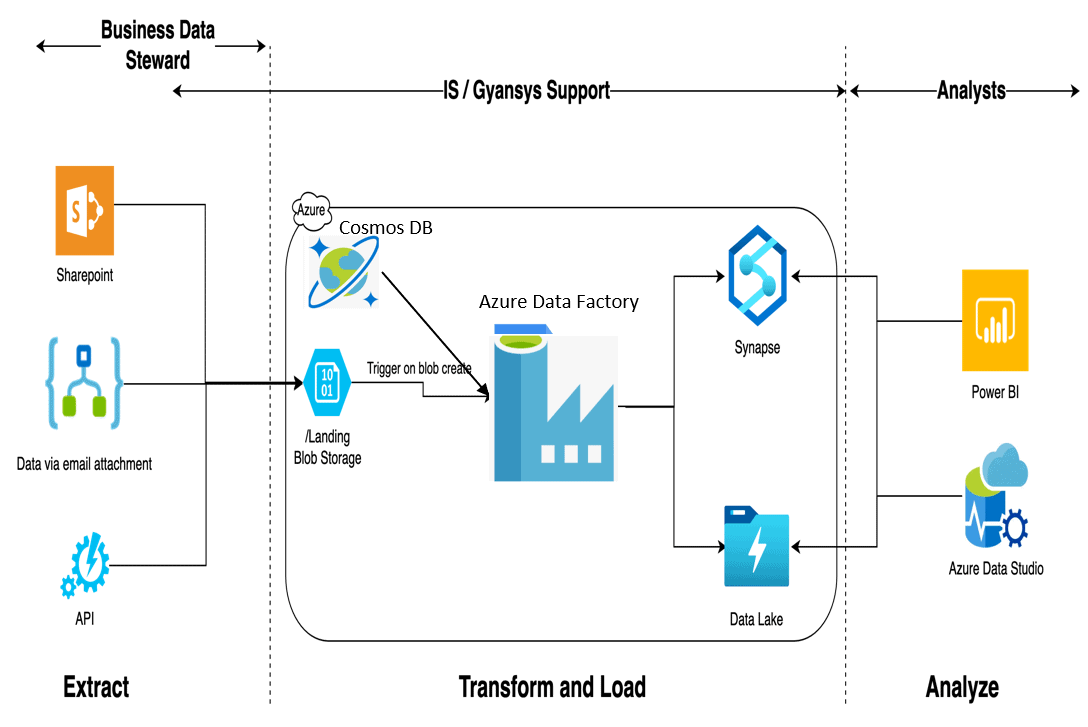
The main components configured to set up a dynamic pipeline are:
- Cosmos DB
- Blob Storage Containers
- Synapse
- SQL Stored Procedures
- Data Bricks
Each component is discussed below.
Cosmos DB
Cosmos DB is a database that can hold data in a JSON format. This database is used to store the configurations related to each data set. When a dataset starts processing within the data factory pipeline, the configuration related to that data set is read from Cosmos DB, and that data set is processed.
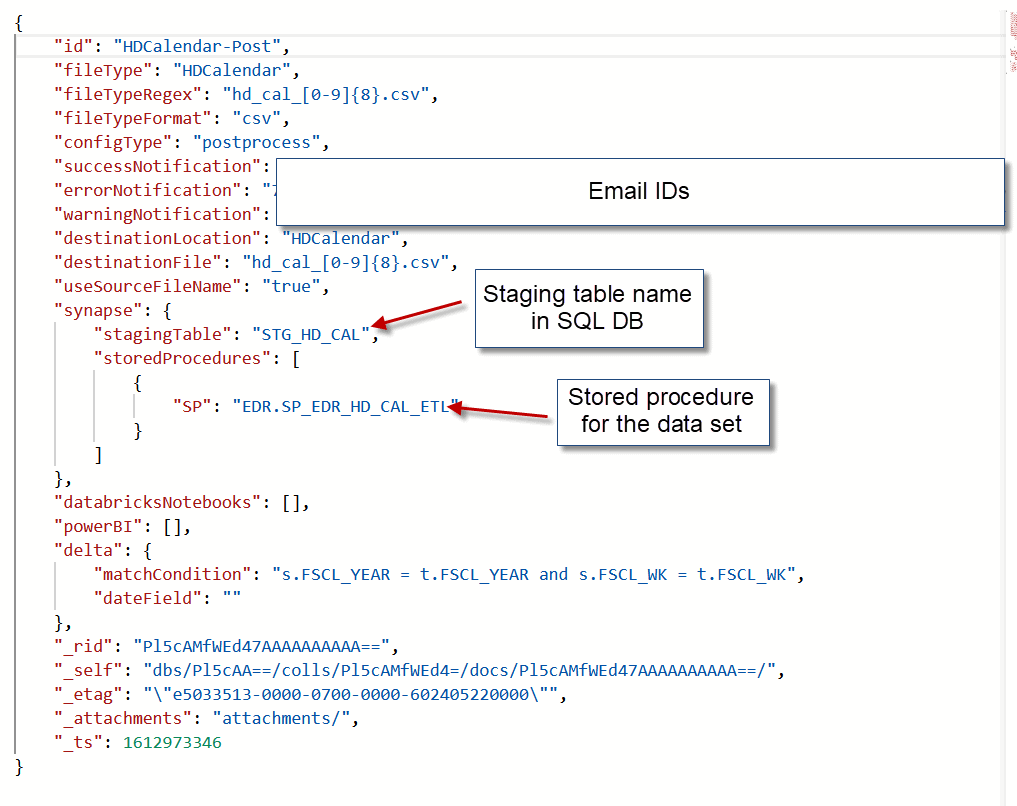
For example, below is a Cosmos DB dataset configuration. When a data set is passed through the Azure Data Factory pipeline, this configuration is read via a 'Lookup' activity. Once this Cosmos DB configuration is read in ADF, we can pass these parameter values to multiple variables within the data factory, like email IDs to send out email notifications or to check what is the file format of the file in the data set or what is the staging table name or the stored procedure name etc. You can find more information during the ADF discussion below on how to use this configuration within pipelines.
Blob Storage Container
Files or data sets from the shared drive or other online platforms are captured and landed into the blob storage in Excel, CSC, JSON formats. These files are either dropped manually, via email, or pulled via APIs. As soon as a Blob or a dataset is saved in the Blob storage container, the data factory pipeline gets triggered to process the file.
Azure Synapse
This is the final data warehouse service where the processed data is stored in tables.
SQL Stored Procedures
After converting the file from an unstructured to a structured format, stored procedure/s are run to apply the business logic and turn that data into meaningful information and finally to store that data in the synapse table.
Databricks
If a dataset is in an unstructured format, that needs to be converted into a structured format, based on the fields required by the business. This processing happens via Databricks. The Databricks component consists of a python programming paradigm that handles the conversion from the unstructured to the structured format.
Dynamic Pipeline Configuration
To logically divide the whole data set processing prior to being stored in a Synapse table, there are 3 pipelines configured: Router, Pre-process and Post-process. The router pipeline picks the data set file and passes it to either pre-process pipeline or post-process pipeline. If any dataset needs to be converted from an unstructured to a structured format, they are passed to the pre-processing pipeline and processed here. After conversion, the original data set file is converted into multiple structure CSV files and these files are further passed to the post-processing pipeline to move data to the Synapse table. Any files which are already structured and need no pre-processing are directly passed to the post-processing pipeline for Synapse storage.
To achieve the dynamic behavior of the pipelines, there is extensive use of variables and parameters within the pipelines. Any information related to datasets is not at all hard-coded anywhere in the pipelines and everything is achieved via the config stored in CosmosDB and variables/parameters within the pipeline.
For the dynamic pipeline config settings, I will talk about the first pipeline, the Router data factory pipeline. I divided the dynamic process into 2 parts:
- Main Pipeline or Parent Pipeline: The purpose of this pipeline is to pick the dataset and pass it to another processor pipeline that does all the processing. If for any reason any activity in the processor pipeline fails, the main pipeline will send out appropriate error information returned by the processor pipeline to the authorized recipients via email. Also, the error is logged in the CosmosDB database, which is further connected to PowerBI where a full-fledged dashboard is set up to analyze the errors. Preventive action is taken based on the analysis performed.
- Processor pipeline: This pipeline reads the config from CosmosDB, picks up the files from the blob storage container, and processes it accordingly.
Each of these pipelines is described below.
Parent Pipeline
The Main/Parent Pipeline Architecture is shown here:
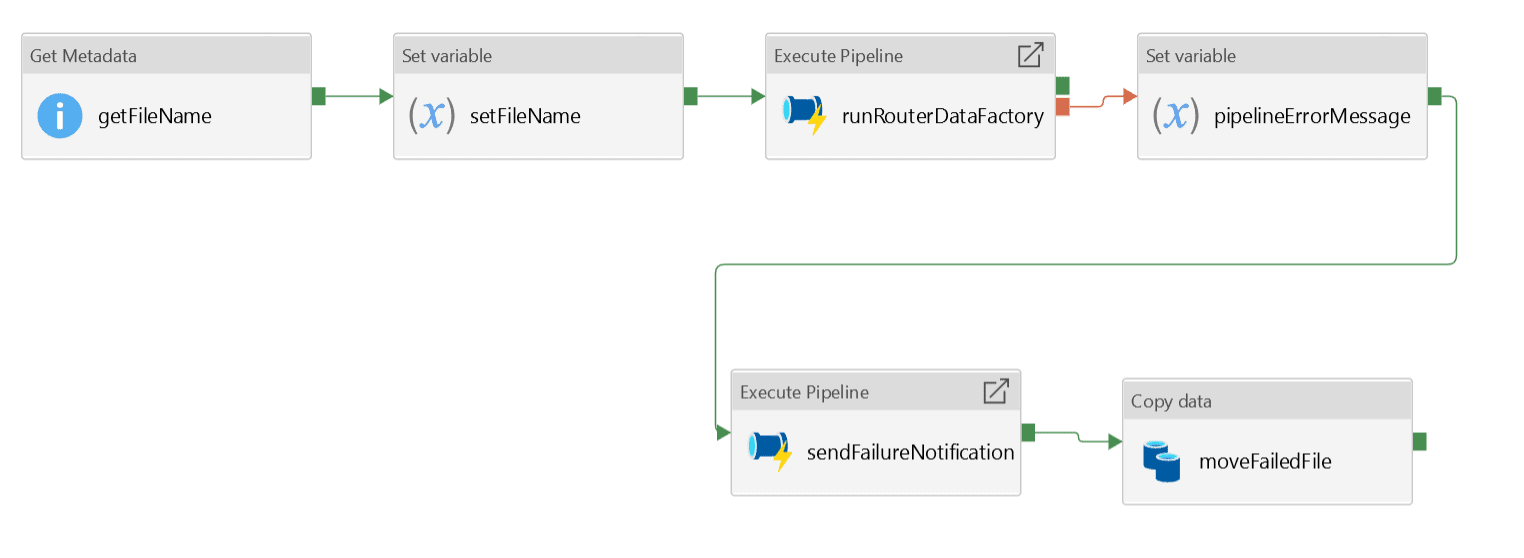
Each activity in the ADF pipeline is described here:
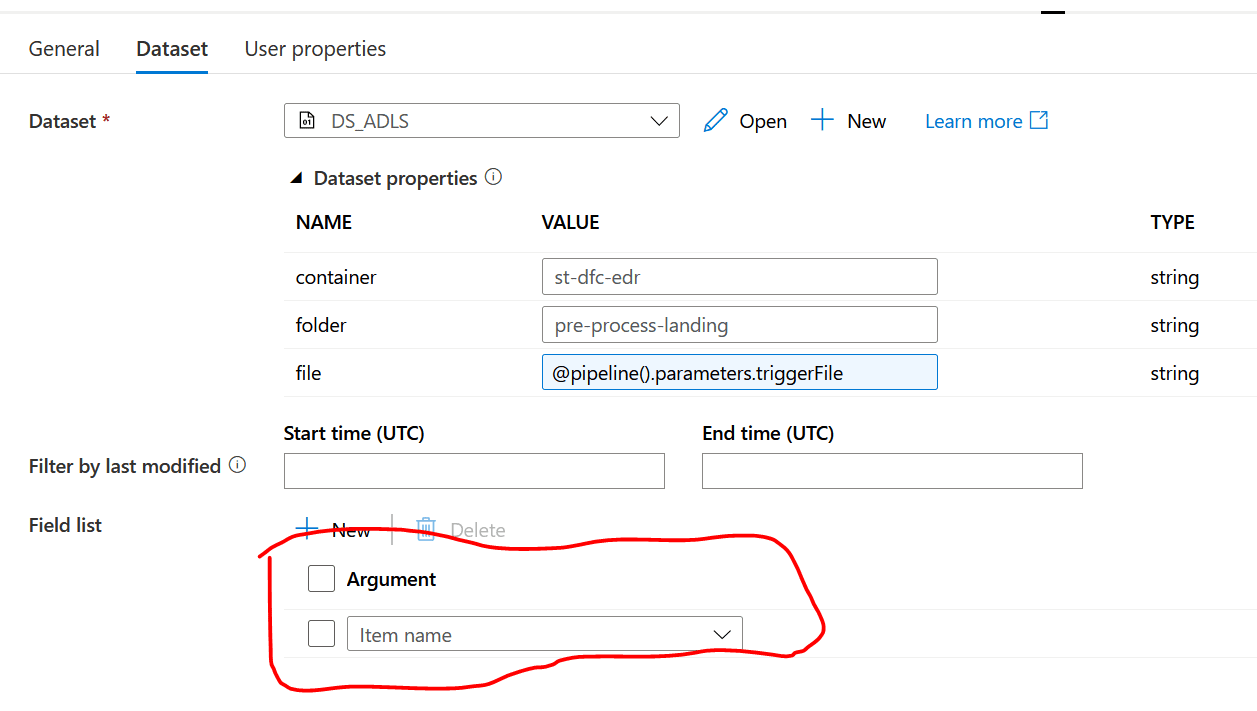
getFileName: This is a ‘Get Metadata’ activity. Notice the Field list configuration selected as ‘Item name’. As soon as the blob hits the folder in the blob container, this pipeline is triggered, and the ‘Get Metadata’ activity picks up the file name from the folder.
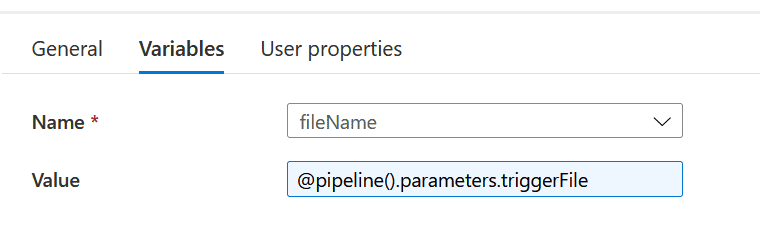
setFileName: This is a ‘Set Variable’ activity. The name of the file is passed to this variable.
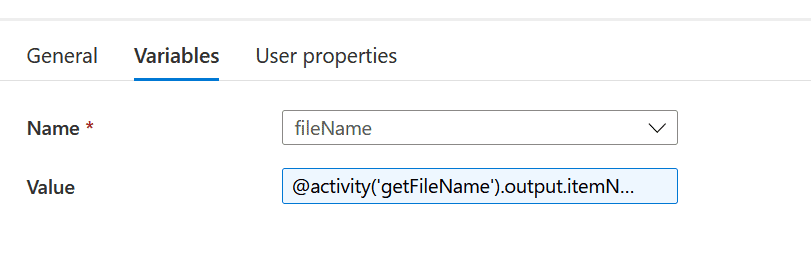
runRouterDataFactory: This is the ‘Execute Pipeline’ activity and triggers the processor pipeline.
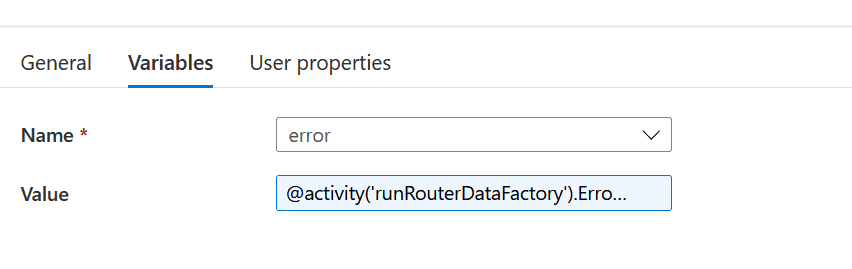
pipelineErrorMessage: This is a ‘Set Variable’ activity. Notice that this activity is connected as a failure process of the previous activity. The previous activity runs the processor pipeline, so this means if there is any activity that fails in the processor pipeline, the error returned gets stored in a variable: @activity('runRouterDataFactory').Error.Message
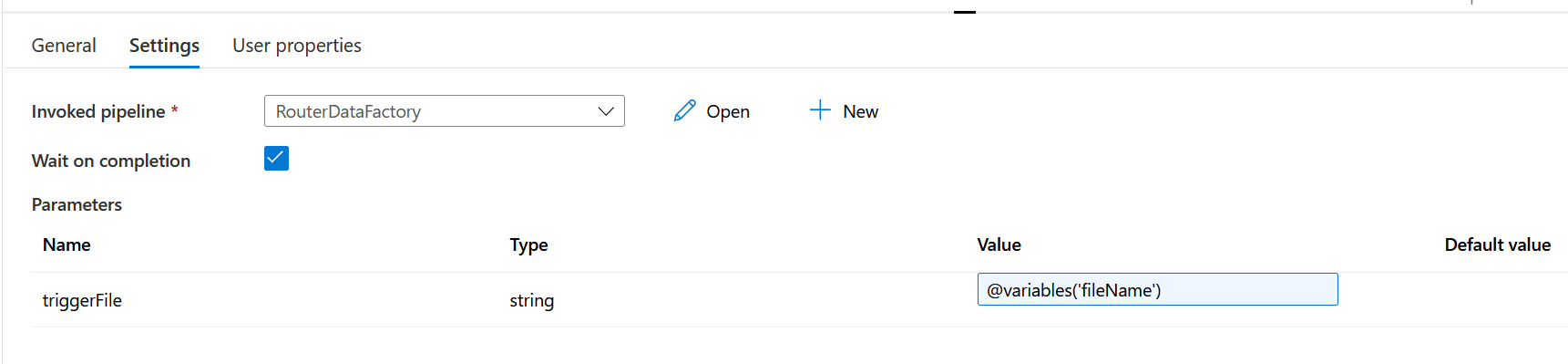
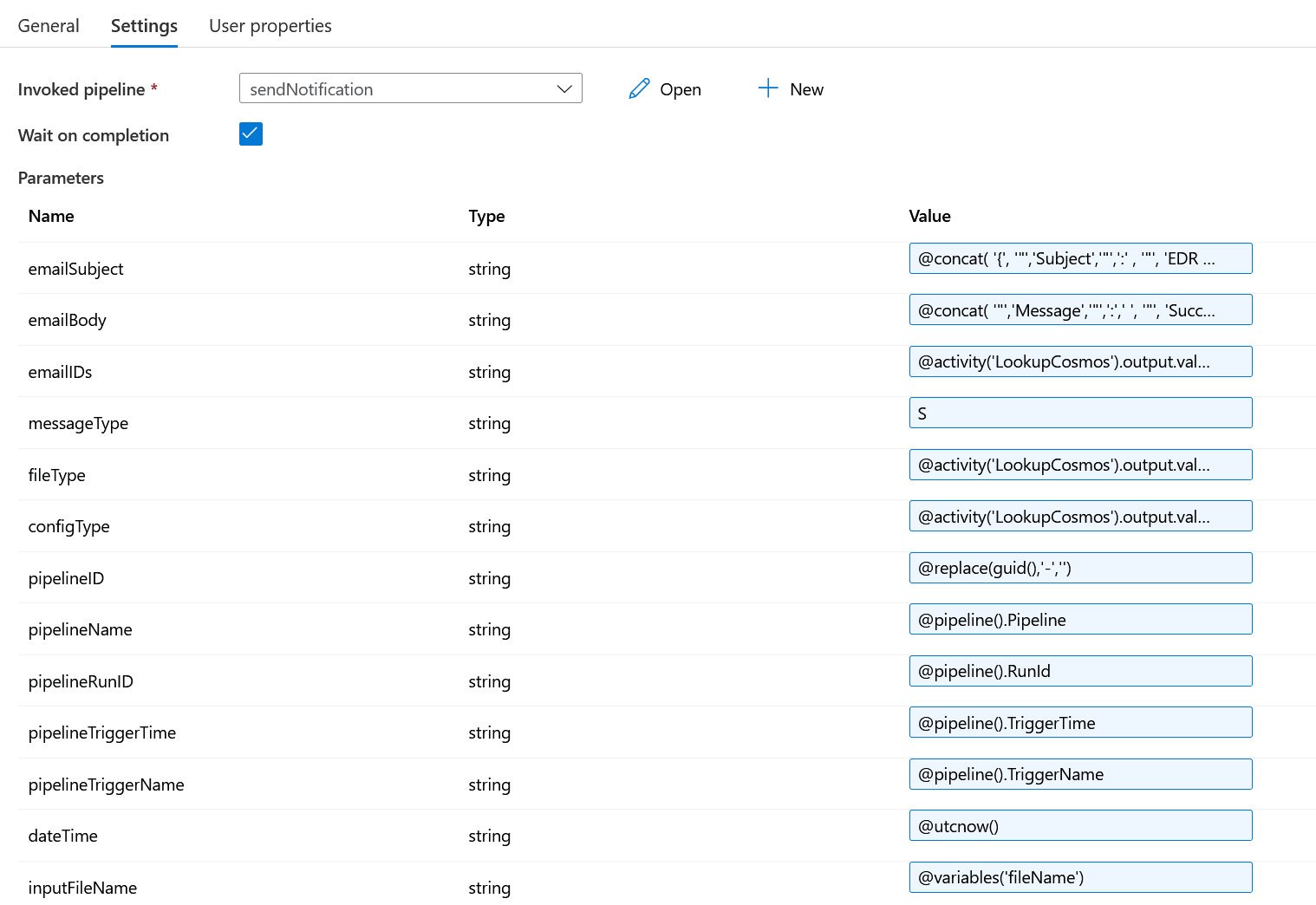
sendFailureNotification: This is another ‘Execute Pipeline’ activity and triggers a separate pipeline to send out an error notification. All the necessary information is passed to the pipeline to send the email notification.
moveFailedFile: This is a ‘Copy data’ activity. Since there was an error in the processor pipeline, the dataset needs to be re-processed after fixing the error. This activity moves the failed data file from the landing folder to a different ‘error’ folder which holds the error data files. They can be fixed and moved back to the landing folder for re-processing.
Process Pipeline
The Processor Pipeline architecture is shown here:
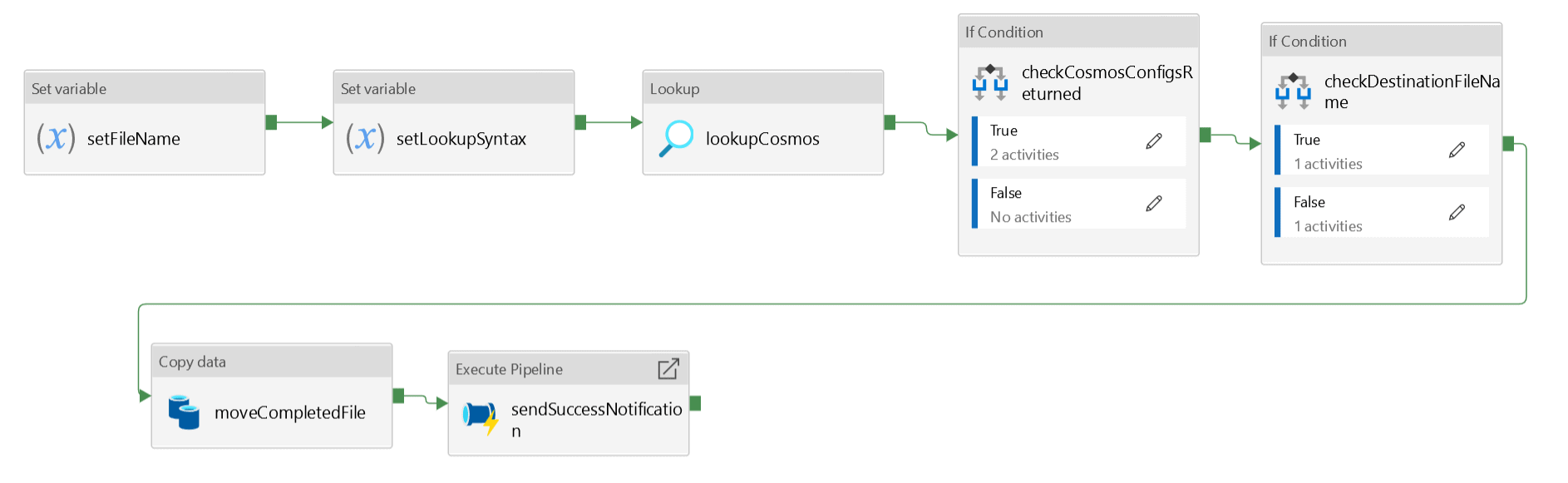
setFileName: This is a ‘Set variable’ activity. The file name picked by the parent pipeline is passed to this processor pipeline via a parameter.
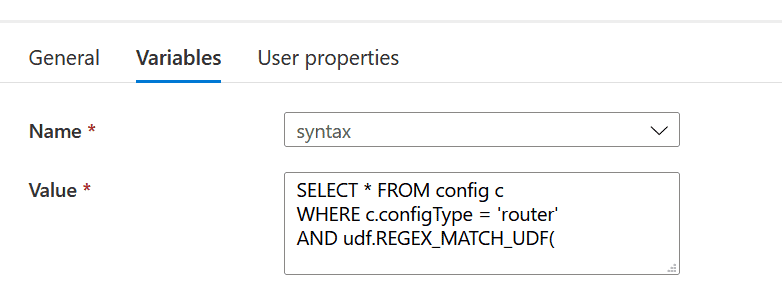
setLookupSyntax: This is the ‘Set variable’ activity. The variable holds the syntax to lookup Cosmos DB.
lookupCosmos: This is a ‘Lookup’ activity. This is used to look up into the Cosmos DB for the configuration related to the dataset landed in the blob storage container. The query used for this is:
@concat(variables('syntax'),variables('singleQuote'),variables('fileName'),variables('singleQuote'),',','c.fileTypeRegex',')' )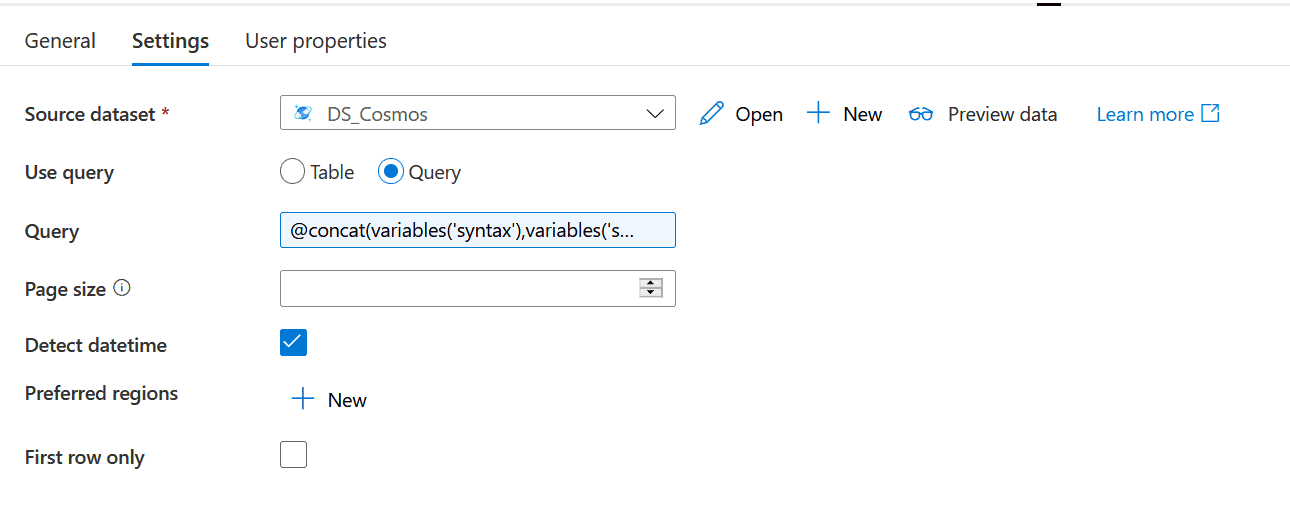
checkCosmosConfigsReturned: This is an ‘IF condition’ activity. This condition checks if a configuration related to the data set in the process is available in Cosmos DB or not and is read by the Lookup activity. If ‘True’: Do Nothing. If False: This means config is not available and it makes no sense to move further in the pipeline. Raise an error message and force pipeline to error.
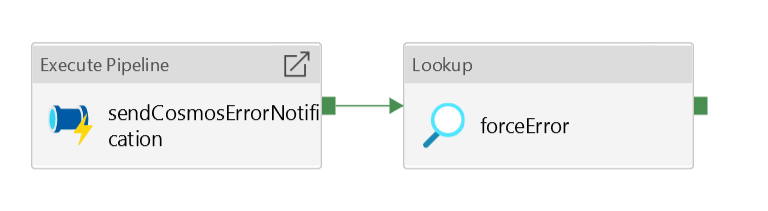
sendCosmosErrorNotification: This is an ‘Execute Pipeline’ activity and triggers Send Notification pipeline with all necessary information required i.e. email body, subject, and email IDs.
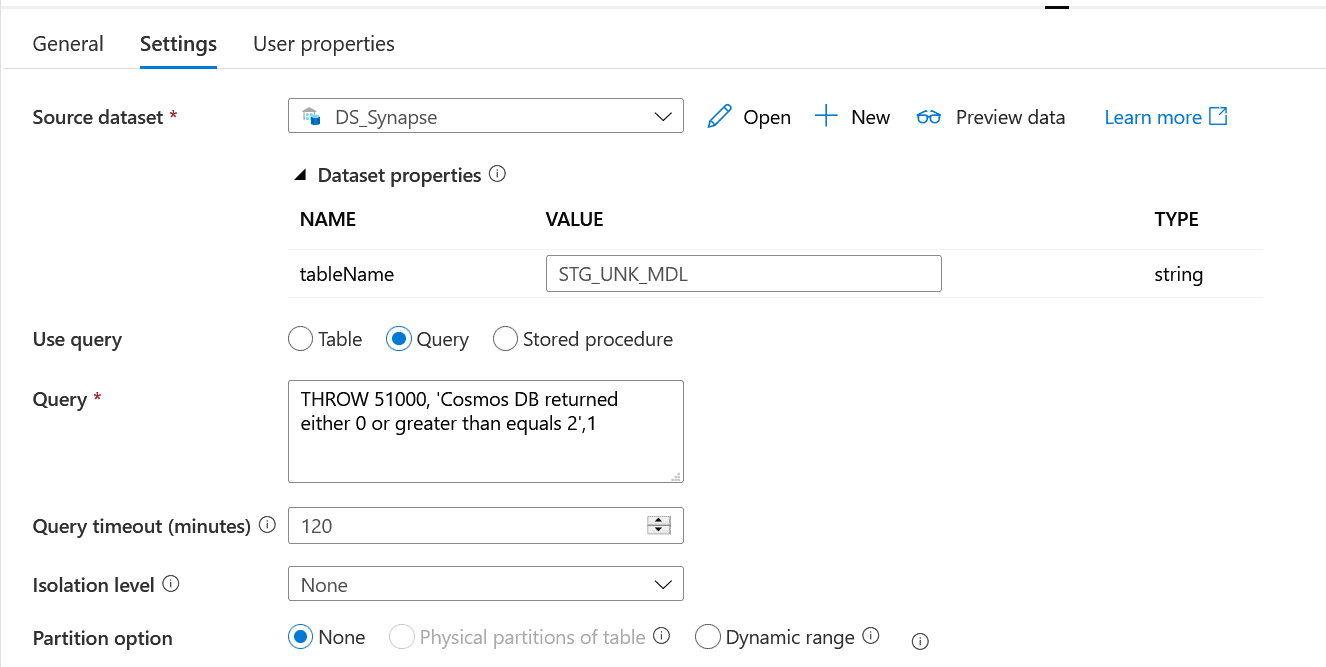
foreceError: This is a Lookup activity, but it is tricky to use this activity to throw an error instead of reading any data. Check out the below config.
checkDestinationFileName: This is an ‘IF Condition’ activity. This is one example where I can show how Cosmos DB config is used within pipelines. There is a placeholder in Cosmos DB that holds the name of the ‘Destination’ file. This activity will move the file. After the file is converted from unstructured to structured data, the processed file is dropped into another folder in the storage container with a new name. The name of that file will a new name as maintained in the Cosmos config as “destinationFile”, shown below:
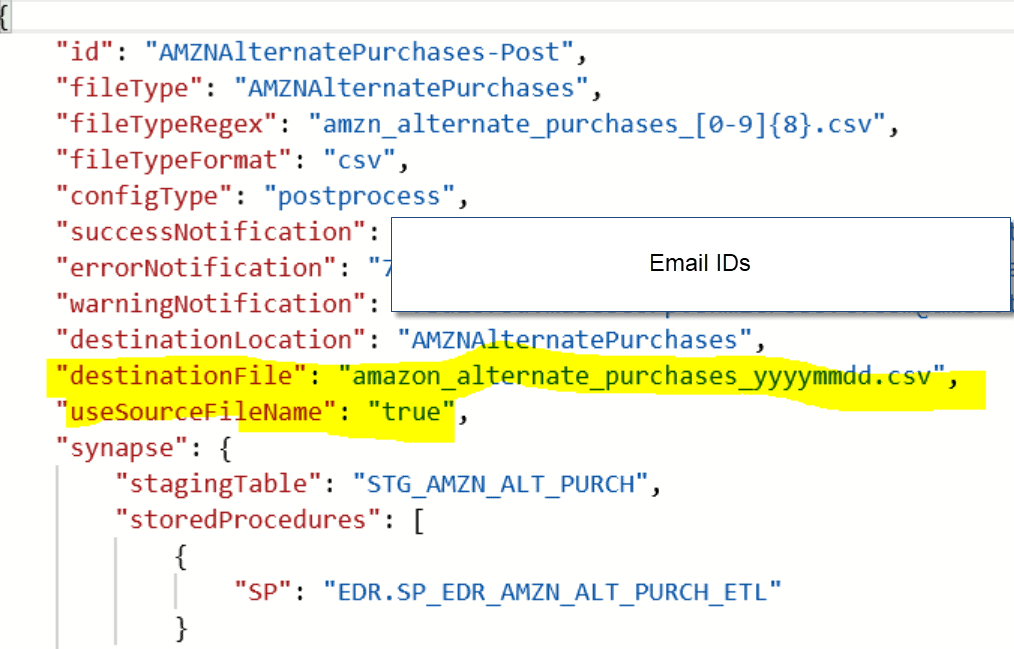
The property, useSourceFileName, has a value “true” or “false”, which will be looked at in the Data Factory in this ‘IF condition’. If “True”: Copy the file to the destination folder with the file name maintained in the Cosmos DB. If “False”: Copy the file to the destination folder with the file name same as the source file.
moveCompletedFile: This is a “Copy” activity. Once the file is processed, it’s a success and the file is moved to a different folder titled ‘completed’. You can also attach a timestamp with the file name to keep track of the files processed with time.
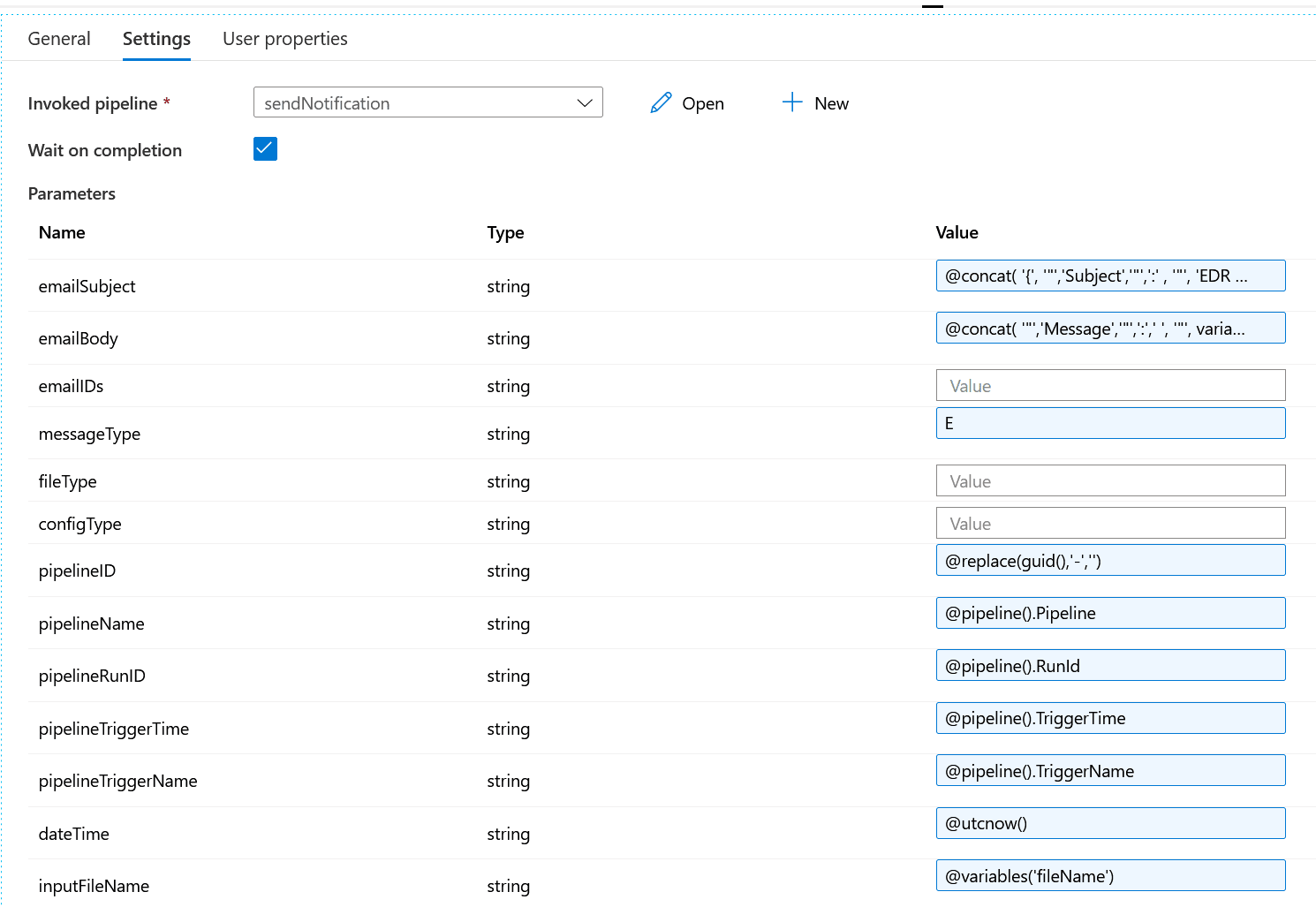
sendSuccessNotification: This is the ‘Execute pipeline’ activity. Once the file is processed successfully, a success message is sent out. This activity triggers another process chain, sendNotification, which finally sends out a success message to the designated email IDs maintained in the Cosmos DB config. You can pass all the necessary information to the sendNotification pipeline via parameters.
Conclusion
Azure Data Factory is a very robust data integration and ingestion platform that can process terabytes to petabytes of data stored in the storage containers or data in transit via outside sources. With the right design, data ingestion to the Azure platform can be made dynamic, easy to use, and easy to maintain. Hope this article is helpful in designing efficient data factory pipelines that will save a lot of time and effort.
