

Series Overview
This series of articles looks at how the optimizer builds up an executable query plan using rules. To illustrate the process performed by the optimizer, we'll configure it to produce incrementally better plans by progressively applying its internal exploration rules. You can read about the basics of how a plan is conrtucted in Part 1.
Part Two - Producing the Fully-Optimized Plan
As a reminder, here is the sample query we are optimizing:

Part One ended with this partially-optimized plan:
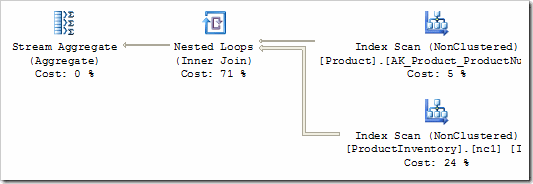
The optimizer has pushed the predicate "ProductNumber LIKE 'T%'" down from a Filter iterator to the Index Scan on the product table, but it remains as a residual predicate. We need to enable a new transformation rule (SelResToFilter) to allow the optimizer to rewrite the LIKE as an index seek:
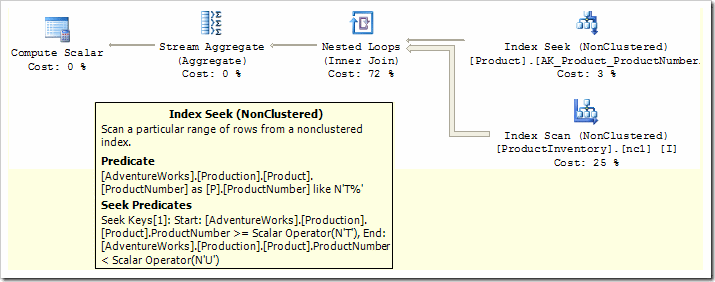
Notice that the LIKE is now expressed in a SARGable form, and the original LIKE predicate is now only evaluated on rows returned from the seek.
The remaining inefficiency is in scanning the whole Inventory table index for every row returned by our new seek operation. At the moment, the JOIN predicate (matching ProductId between the two tables) is performed inside the Nested Loops operator. It would be much more efficient to perform a seek on the Inventory table's clustered index.
To achieve that, we need to do two things:
- Convert the naive nested loops join to an index nested loops join (see Understanding Nested Loops Joins)
- Drive each Inventory table seek using the current value of Product.ProductId
The first one is achieved by a rule called JNtoIdxLookup. The second requirement is a correlated loops join - also known as an Apply. The rule needed to transform our query to that form is AppIdxToApp.
With those two new rules available to the optimizer, here's the plan we get:
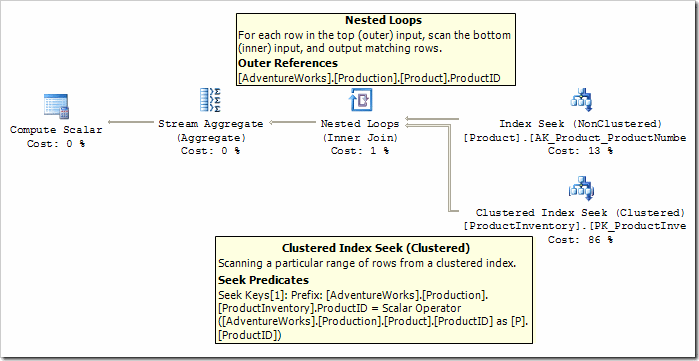
We're now pretty close to the optimal plan (for the specific value in this query). The last step is to collapse the Compute Scalar into the Stream Aggregate. You might remember that the purpose of the Compute Scalar is to ensure that the SUM aggregate returns NULL instead of zero if no rows are processed.
As it stands, the Compute Scalar is evaluating a CASE statement based on the result of a COUNT(*) performed by the Stream Aggregate. We can remove this Compute Scalar, and the need to compute COUNT(*), by normalising the GROUP BY using a rule called 'NormalizeGbAgg'. Once that is done, we have the finished plan:
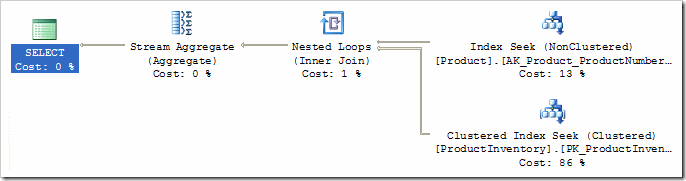
In the next two parts of the series, I'll show you how to customise the rules available to the optimizer, and explore more of the internals of query optimization.
Paul White
Twitter: @PaulWhiteNZ
Blog: SQLblog.com
