

Summary
The utility described in this article allows you to quickly identify which queries are running slower than expected on SQL Server 2005.
Recognising these queries will allow you to take corrective targeted action to improve their performance. Various possible solutions are proposed.
Introduction
As part of your normal monitoring it makes sense to ensure the runtime duration your queries does not deviate significantly from the expected norm. Identifying these queries will allow you to target your efforts and correct any performance problems in a timely manner.
A query can start to run slower for many reasons, including: an increased number of users (resulting in more waiting on resources), increased volume of data to process, too much context switching for parallel queries, and slower hardware.
When a query is run, its query plan is cached to improve subsequent run of the query. Many interesting details relating to the query are recorded, these details can be accessed via SQL Server’s Dynamic Management Views (DMVs). In particular the DMV sys.dm_exec_query_stats contains performance statistics for cached query plans. This DMV has everything we need to determine if a query is running slower than normal.
Details of the sys.dm_exec_query_stats columns relevant to us, are described in figure 1 (edited and taken from SQL Server 2005 Books online).
| Column name | Data type | Description |
| statement_start_offset | int | Indicates, in bytes, beginning with 0, the starting position of the query that the row describes within the text of its batch or persisted object. |
| statement_end_offset | int | Indicates, in bytes, starting with 0, the ending position of the query that the row describes within the text of its batch or persisted object. A value of -1 indicates the end of the batch. |
| plan_handle | varbinary(64) | A token that refers to the compiled plan that the query is part of. This value can be passed to the sys.dm_exec_query_plan dynamic management function to obtain the query plan. |
| execution_count | bigint | Number of times that the plan has been executed since it was last compiled. |
| total_worker_time | bigint | Total amount of CPU time, in microseconds, that was consumed by executions of this plan since it was compiled. |
| last_worker_time | bigint | CPU time, in microseconds, that was consumed the last time the plan was executed. |
| total_physical_reads | bigint | Total number of physical reads performed by executions of this plan since it was compiled. |
| last_physical_reads | bigint | Number of physical reads performed the last time the plan was executed. |
| total_logical_writes | bigint | Total number of logical writes performed by executions of this plan since it was compiled. |
| last_logical_writes | bigint | Number of logical writes performed the last time the plan was executed. |
| total_logical_reads | bigint | Total number of logical reads performed by executions of this plan since it was compiled. |
| last_logical_reads | bigint | Number of logical reads performed the last time the plan was executed. |
| total_elapsed_time | bigint | Total elapsed time, in microseconds, for completed executions of this plan. |
| last_elapsed_time | bigint | Elapsed time, in microseconds, for the most recently completed execution of this plan. |
Figure 1 shows the sys.dm_exec_query_stats fields used by the Query Time Delta utility
The _elapsed_time columns record how long the query took, taking into account any waiting on resources.
The _worker_time columns record how long the query took, ignoring any waiting on resources, instead it is concerned only with the time spent using the CPU.
In this article, we will look only at queries that are slower based on the _worker_time columns. This will allow us to ignore many of the variable factors that affect query duration, allowing us instead to create and discuss a simplified utility to quickly determine if a query is running slower than normal, based on the amount of CPU it has used.
Query Time Delta Utility
To determine if a query is running slower than normal, we need to calculate the average duration of the query and compare it to its last run value, adjusted for the amount of data it has processed.
The number of runs (execution_count) and the total worker time (total_worker_time) both include data relating to the last run, thus in order to create a more representative average, the number of runs is reduced by 1, and the total worker time has the last run time subtracted from it.
The average duration of the query is calculated by subtracting the last_worker_time from the total_worker_time and dividing the result by execution_count – 1.
The algorithm used to determine if a query is running slower than average is:
%Slower = (LAST – AVG) x 100 / AVG where LAST represents the duration of last query, and AVG represents the average duration of the query
For example, if the average query duration (AVG) is 40ms, and the last query duration (LAST) is 160ms, then %Slower = (160 – 40) x 100 / 40 = 300%
The duration of a query is affected by the amount of data it processes, this volume of data is reflected in the various IO columns of sys.dm_exec_query_stats. This utility calculates the slowness of a query (Impedance) by combining the duration of the query with the amount of IO performed. Again the ‘total’ IO values include the last run values, and thus need to be adjusted.
To see the SQL text of the individual query statement together with its parent query we call the Dynamic Management Function (DMF) sys.dm_exec_sql_textpassing it the query’s plan_handle as the function parameter. We can extract the individual query using the statement start and end offset values that are part of the DMV sys.dm_exec_query_stats.The DMF sys.dm_exec_sql_textcontains the id of the database the query related to, this is also shown. Note the WHERE clause only selects queries that have been executed at least twice.
For maintainability, the calculation of “% IO deviation” is separated from the main query. The data is sorted to show the TOP 100 slowest queries, by Impedance, this is a reflection of time deviation taking into account IO deviation.
Running the utility on my SQL Server gives the results given in Figure 2.
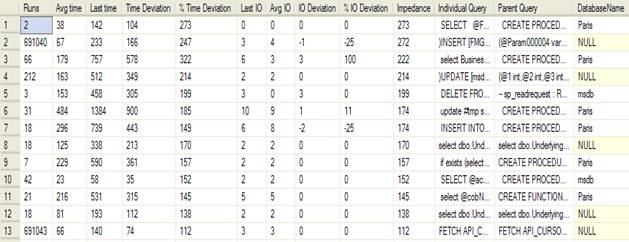
Figure 2 Output from the Query Time Delta utility.
The results show the individual statements, within a stored procedure or batch, that are running slower than normal. Adhoc or prepared queries are not associated with a database, hence the database name column is set to null.
Discussion
The utility described in this article allows you to quickly identify which queries are running slower than expected, after taking into account the volume of data processed.
Since this utility concerns itself with _worker_time rather than _elapsed_time, we can ignore many of the reasons why the query might be running slower (e.g. concurrency and blocking), and concentrate on why the query is using more CPU (i.e. worker_time) to fulfill its needs.
Perhaps the most common reason why a query starts to run slower (often suddenly) relates to “parameters sniffing”. Here the query plan is optimised based on the value of the parameters when the query is first used. You can imagine a parameter that retrieves only a few rows would produce a different plan than a parameter that would retrieve many rows.
Various solutions exist to create cached plans that are more optimal for the passed parameters, including:
1. Execute the stored procedure with the recompile option, this does not replace the query’s current cached plan.
e.g. EXEC sprocName WITH RECOMPILE
2. Add WITH RECOMPILE to the body of the stored procedure signature, this causes the stored procedure to be recompiled on every usage.
e.g. CREATE PROC sprocName WITH RECOMPILE
3. Use the optimizer hint RECOMPILE on an individual query within a stored procedure.
e.g. SELECT col3 FROM table1 WHERE col3 = @param1
OPTION (RECOMPILE)
4. Use the optimizer hint OPTIMIZE FOR. This allows you to create a plan based on more typical parameter values.
e.g. SELECT col3 FROM table1 WHERE col3 = @param1
OPTION (OPTIMIZE FOR (@param1=71))
5. Use Plan Guides, these provide a degree of stability by allowing you to use an existing optimised query plan.
Each of these proposed solutions has advantages and disadvantages, and is left as an exercise for the reader to investigate them further.
Further work
If you’re interesting in the effect of changing concurrency patterns, blocking, waits etc you might want to look at elapsed time rather than the worker time. You can see the effects of these by replacing the _worker_time variables with _elapsed_time variables in the Utility script.
Various changes (e.g. adding indexes, updating statistics) can cause a query to be recompiled, resulting in a new cache plan, thus making comparisons of a query over time difficult. In this case, you should keep a history for comparison purposes. Keeping a history is also useful because DMV data is transient, often being cleared due to server restarts or memory pressures.
Conclusion
The utility described in this article will help identify easily and quickly those queries that have taken longer to run than normal, and should prove valuable in the everyday work of the SQL Server DBA/developer.
Credits
Ian Stirk has been working in IT as a developer, designer, and architect since 1987. He holds the following qualifications: M.Sc., MCSD.NET, MCDBA, and SCJP. He is a freelance consultant working with Microsoft technologies in London England. He can be contacted at Ian_Stirk@yahoo.com.
Code
CREATE PROC [dbo].[dba_QueryTimeDelta]
AS
/*----------------------------------------------------------------------
Purpose: Identify queries that are running slower than normal
, when taking into account IO volumes.
------------------------------------------------------------------------
Parameters: None.
Revision History:
13/01/2008Ian_Stirk@yahoo.com Initial version
Example Usage:
1. exec YourServerName.master.dbo.dba_QueryTimeDelta
----------------------------------------------------------------------*/
BEGIN
-- Do not lock anything, and do not get held up by any locks.
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
-- Identify queries running slower than normal.
SELECT TOP 100
[Runs] = qs.execution_count
--, [Total time] = qs.total_worker_time - qs.last_worker_time
, [Avg time] = (qs.total_worker_time - qs.last_worker_time) / (qs.execution_count - 1)
, [Last time] = qs.last_worker_time
, [Time Deviation] = (qs.last_worker_time - ((qs.total_worker_time - qs.last_worker_time) / (qs.execution_count - 1)))
, [% Time Deviation] =
CASE WHEN qs.last_worker_time = 0
THEN 100
ELSE (qs.last_worker_time - ((qs.total_worker_time - qs.last_worker_time) / (qs.execution_count - 1))) * 100
END
/ (((qs.total_worker_time - qs.last_worker_time) / (qs.execution_count - 1)))
, [Last IO] = last_logical_reads + last_logical_writes + last_physical_reads
, [Avg IO] = ((total_logical_reads + total_logical_writes + total_physical_reads)
- (last_logical_reads + last_logical_writes + last_physical_reads))
/ (qs.execution_count - 1)
, [Individual Query] = SUBSTRING (qt.text,qs.statement_start_offset/2,
(CASE WHEN qs.statement_end_offset = -1
THEN LEN(CONVERT(NVARCHAR(MAX), qt.text)) * 2
ELSE qs.statement_end_offset END - qs.statement_start_offset)/2)
, [Parent Query] = qt.text
, [DatabaseName] = DB_NAME(qt.dbid)
INTO #SlowQueries
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.plan_handle) qt
WHERE qs.execution_count > 1
ORDER BY [% Time Deviation] DESC
-- Calculate the [IO Deviation] and [% IO Deviation].
-- Negative values means we did less I/O than average.
SELECT TOP 100 [Runs]
, [Avg time]
, [Last time]
, [Time Deviation]
, [% Time Deviation]
, [Last IO]
, [Avg IO]
, [IO Deviation] = [Last IO] - [Avg IO]
, [% IO Deviation] =
CASE WHEN [Avg IO] = 0
THEN 0
ELSE ([Last IO]- [Avg IO]) * 100 / [Avg IO]
END
, [Individual Query]
, [Parent Query]
, [DatabaseName]
INTO #SlowQueriesByIO
FROM #SlowQueries
ORDER BY [% Time Deviation] DESC
-- Extract items where [% Time deviation] less [% IO deviation] is 'large'
-- These queries are slow running, even when we take into account IO deviation.
SELECT TOP 100 [Runs]
, [Avg time]
, [Last time]
, [Time Deviation]
, [% Time Deviation]
, [Last IO]
, [Avg IO]
, [IO Deviation]
, [% IO Deviation]
, [Impedance] = [% Time Deviation] - [% IO Deviation]
, [Individual Query]
, [Parent Query]
, [DatabaseName]
FROM #SlowQueriesByIO
WHERE [% Time Deviation] - [% IO Deviation] > 20
ORDER BY [Impedance] DESC
-- Tidy up.
DROP TABLE #SlowQueries
DROP TABLE #SlowQueriesByIO
END


