

Mistakes in database design can spell long-term issues that jeopardize efficiency and effectiveness. For online transaction processing (OLTP), in which many transactions must be executed concurrently, throughput and speed are key. Good database design is essential to achieve these goals. If a database is not designed to deal with large amounts of data, queries can potentially take hours and cause websites to crash or fail to load, with disastrous effects in fields such as healthcare, finance, and government. Everything from data redundancy, lack of documentation, and failure to protect data integrity can fall through the cracks in the design planning phase. These design flaws happen all too often, and it’s up to IT to do a better job of correcting them to avoid disasters in day-to-day database operations.
Failures in database design often arise when developers lack foresight about the expansion of the data. In other words, they do not anticipate the extent and pace of data growth. Problems can also occur because designers do not have adequate domain knowledge. A key part of effective database design is making sure that database models and relationships mirror their real-world counterparts. For example, people have one-to-one, permanent, uniqueness-constrained relationships with their social security numbers, but could easily have multiple addresses, employers, or even names throughout their life. A database model should reflect these realities.
Centralized and distributed databases
Centralized and distributed databases each have their own advantages. Synchronizing data and correcting inconsistencies in a distributed database system takes time, however, if one database fails, users can still access data in the other databases. Which is more appropriate depends on the needs of the organization. Large businesses and governments are often best served by centralized databases. For example, the state of Virginia transitioned from using a distributed to a centralized database system to manage information about the recipients of its government benefits programs. Since many people receive benefits from multiple programs, consolidating these databases reduced redundancy and increased efficiency. Previously, when applicants wanted to be considered for multiple benefit programs, they had to apply separately in each department. Now that the system has been consolidated, they can simply apply once and be considered for all programs, creating a much smoother user experience.
Frequently overlooked database design best practices
Well-designed data models are the key to a powerful, smoothly functioning database. The following elements are essential to strong database design:
Strong, unique primary keys
It is a best practice to generate unique primary keys for each entry in a database, rather than relying on independently generated surrogate keys. Sometimes the data includes a column that naturally lends itself to the generation of unique primary keys. For example, in a table that stores information about Medicare recipients, social security numbers (SSN) can be used as primary keys (Figure 1).
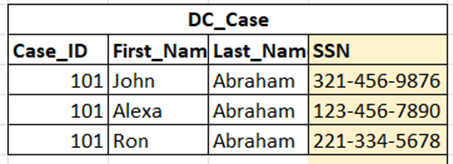
Figure 1: Social Security Number Data
In some situations, there is no column guaranteed to be unique for each entry, and developers might be tempted to rely on surrogate keys. It is better practice, however, to generate a surrogate key based on a composite of multiple columns that can uniquely identify each entry in the database. If independently generated surrogate keys are used, it is more likely that duplicate data will inadvertently be added to the database. Using primary keys or unique surrogate keys reduces data redundancy. In the example below, a combination of SSN and Claim_ID is used to generate a surrogate key ID (Figure 2).
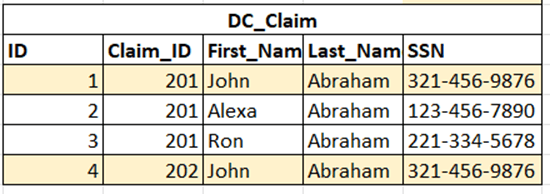
Figure 2: Social Security and Claim ID Data
Use of parent and child tables
Where appropriate, database developers should divide large tables into parent and child tables, connected with primary key/foreign key relationships. A child table has a foreign key that is the same as its parent table’s primary key. In the case of a table storing information on government benefit recipients, a recipient might have multiple doctors and a child table could be used to list the doctors. This is appropriate because doctors share information, like claim number and recipient details, with the claim. Separating data into tables contributes to data normalization, allows faster updates to information, and reduces data redundancy (Figure 3).
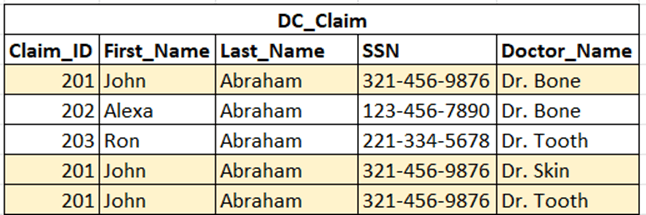
Figure 3: An example of a large table with redundant data.
Creating more tables increases the complexity of databases, which is not ideal in all situations. However, in a relational database model that uses SQL, and where updates and inserts are frequent, normalization is usually the best practice (Figure 4).
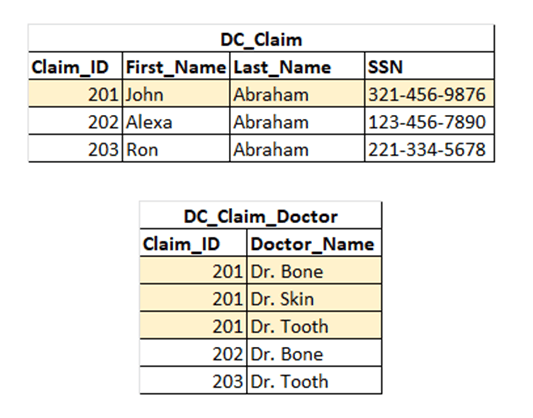
Figure 4: Table from Figure 3 divided into parent and child tables.
Indexing
Indexes provide a reference to where data is stored in a table, speeding up queries. By default, an index is created on primary key columns. It is important to keep the number of indexes relatively low since overuse of indexes can dilute their efficiency. In Figure 4, the claim_id column serves as the default index since it is the primary key in the dc_claim table. Additionally, creating an index on the same column in the dc_claim_doctor table would improve performance when SQL queries, which require joining the dc_claim and dc_claim_doctor tables, are run. Functional-based indexing, which refers to carrying out functions inside of SQL queries, can also improve performance. An example of functional-based indexing is changing all queries in a “name” field to all capital letters to conduct a non-case-sensitive search.
Partitioning of tables
Large data tables can be segmented into multiple smaller physical parts by criteria, for example, range, for quicker searching. Date fields or numerical values lend themselves well to partitioning. The table of government benefit cases should be partitioned by dates, potentially by year or month, depending on the size of the table. In Figure 5, an example of a partitioned table, when the application tries to retrieve data, the database will not scan the entire table. Instead, it will scan data from that particular monthly partition.
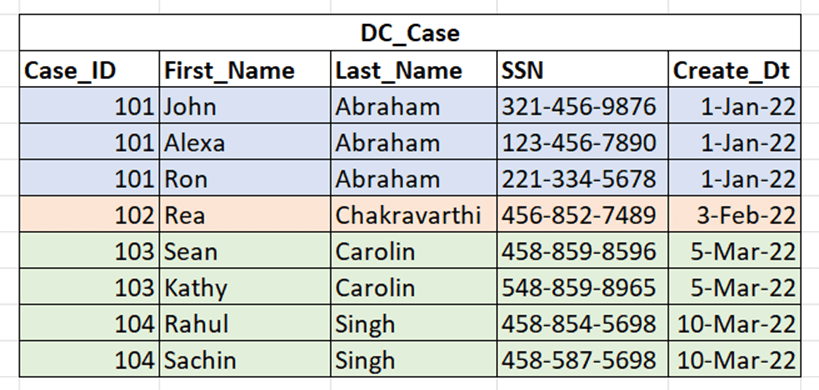
Figure 5: Data divided into three partitions based on the month and year of the create_dt field.
Improving Database Design
As the use of data across industries expands, proper database design and management become ever more crucial. Indexing, partitioning and strong keys all contribute to a high-functioning database. Data normalization is not without its drawbacks, but in an OLTP database with frequent updates to data, it has many advantages. The key to database design is not merely following a set list of best practices but planning for the current and future needs of the organization and the inevitable expansion of data ahead of time. By being proactive in providing this information to developers and prioritizing the importance of good database design, organizations will reap the full benefits of a powerful, well-functioning database.
About the Author
Vikram Bachu is a software engineer specializing in ETL development. He has 10 years of experience in the industry, and is highly skilled in Informatica, IICS, UNIX, and multiple databases. For more information, contact vikrambachu9@gmail.com.

