

When you work with ETL and the source file is JSON, many documents may get nested attributes in the JSON file. Your requirements will often dictate that you flatten those nested attributes. There are many ways you can flatten the JSON hierarchy, however; I am going to share my experiences with Azure Data Factory (ADF) to flatten JSON.
The ETL process involved taking a JSON source file, flattening it, and storing in an Azure SQL database. The attributes in the JSON files were nested, which required flattening them. The source JSON looks like this:
{
"id": "01",
"name": "Tom Hanks",
"age": 20.0,
"email": "th@hollywood.com",
"Cars":
{
"make": "Bentley",
"year": 1973.0,
"color": "White"
}
}
The above JSON document has a nested attribute, Cars. We would like to flatten these values that produce a final outcome look like below:
{
"id": "01",
"name": "Tom Hanks",
"age": 20.0,
"email": "th@hollywood.com",
"Cars_make": "Bentley",
"Cars_year": "1973.0",
"Cars_color": "White"
}How do we do flatten JSON in ADF?
Let's create a pipeline that includes the Copy activity, which has the capabilities to flatten the JSON attributes. Let's do that step by step.
First, create a new ADF Pipeline and add a copy activity.
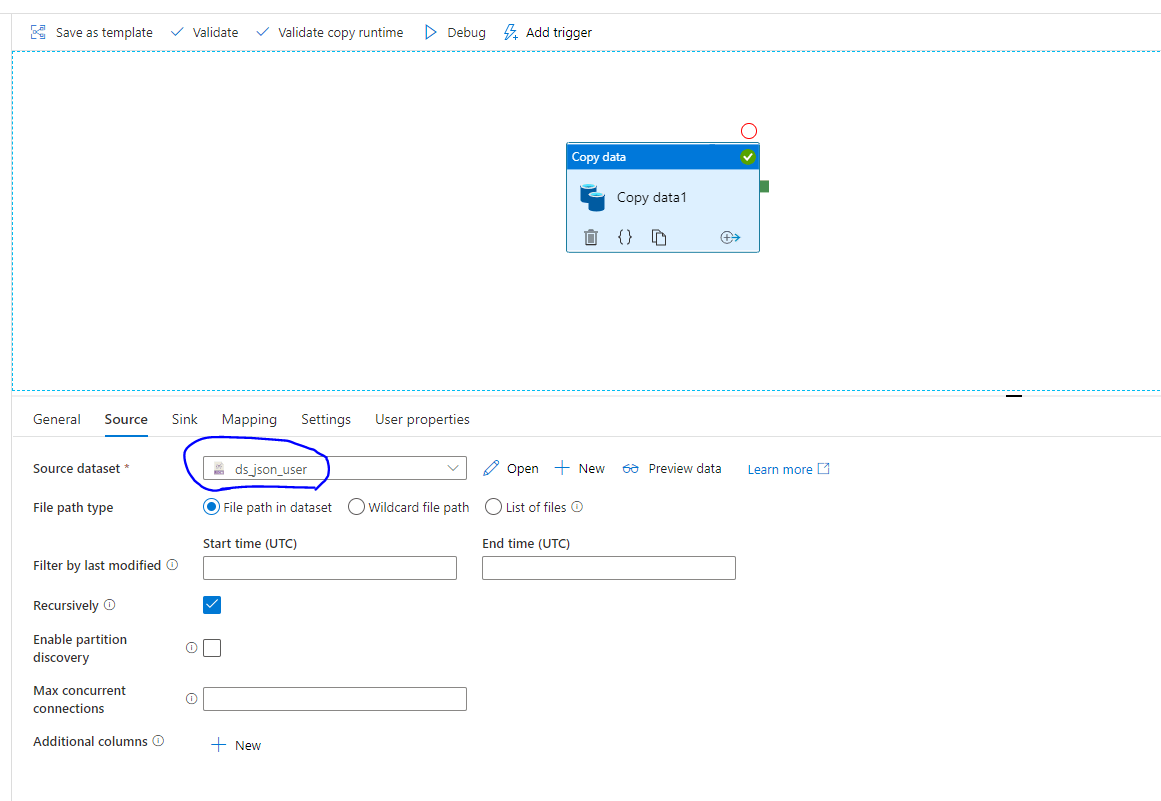
Next, we need datasets. You need to have both source and target datasets to move data from one place to another. In this case source is Azure Data Lake Storage (Gen 2). The target is Azure SQL database. The below figure shows the source dataset. We are using a JSON file in Azure Data Lake.
We will insert data into the target after flattening the JSON. the below figure shows the sink dataset, which is an Azure SQL Database.
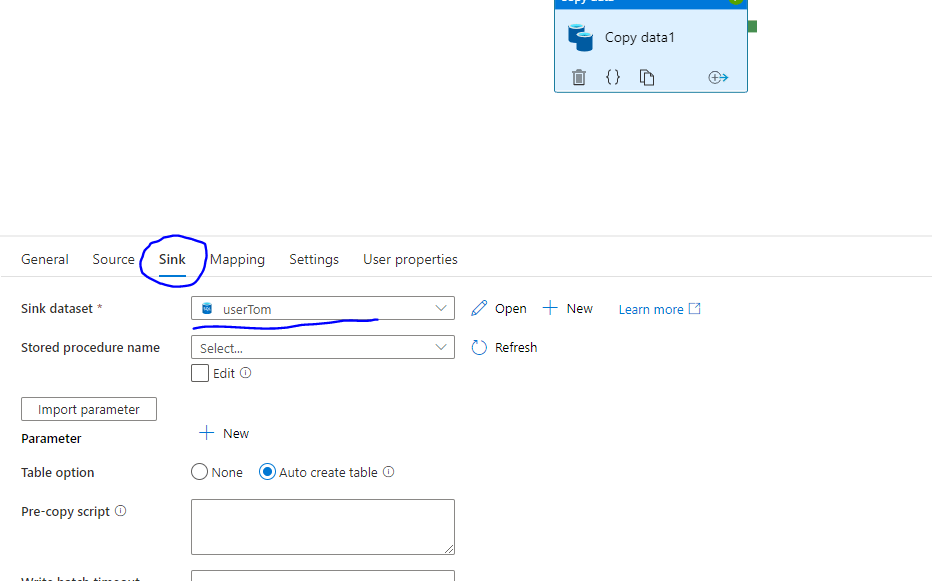
Please note that, you will need Linked Services to create both the datasets. This article will not go into details about Linked Services. If you need details, you can look at the Microsoft document.
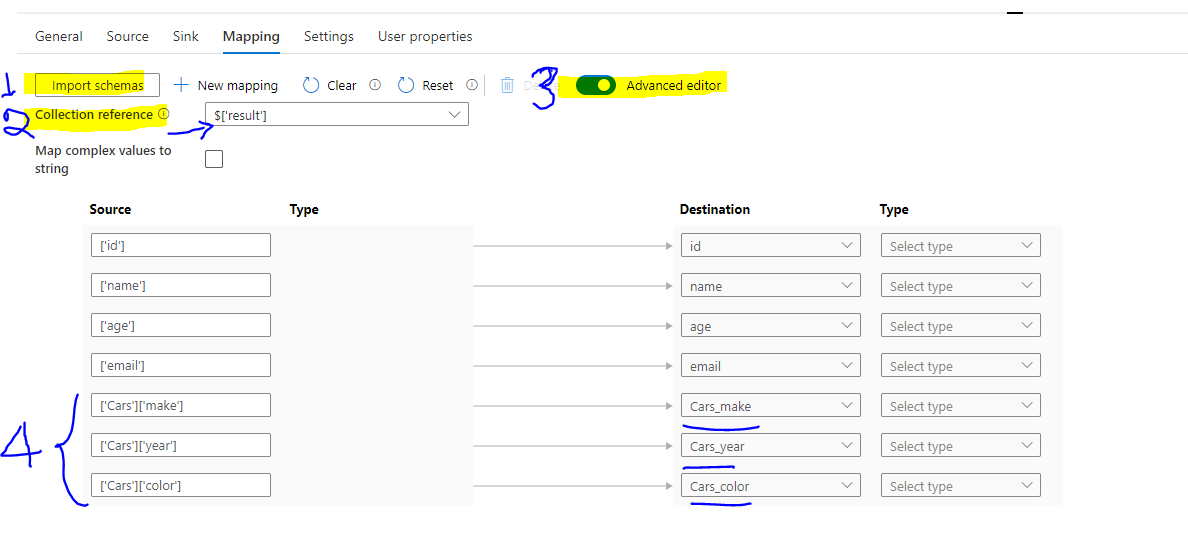
After you create source and target dataset, you need to click on the mapping, as shown below. Follow these steps:
- Click import schemas
- Make sure to choose value from Collection Reference
- Toggle the Advanced Editor
- Update the columns those you want to flatten (step 4 in the image)
After you have completed the above steps, then save the activity and execute the pipeline. You will find the flattened records have been inserted to the database, as shown below.

Be cautious
Make sure to choose "Collection Reference", as mentioned above. If you forget to choose that then the mapping will look like the image below.
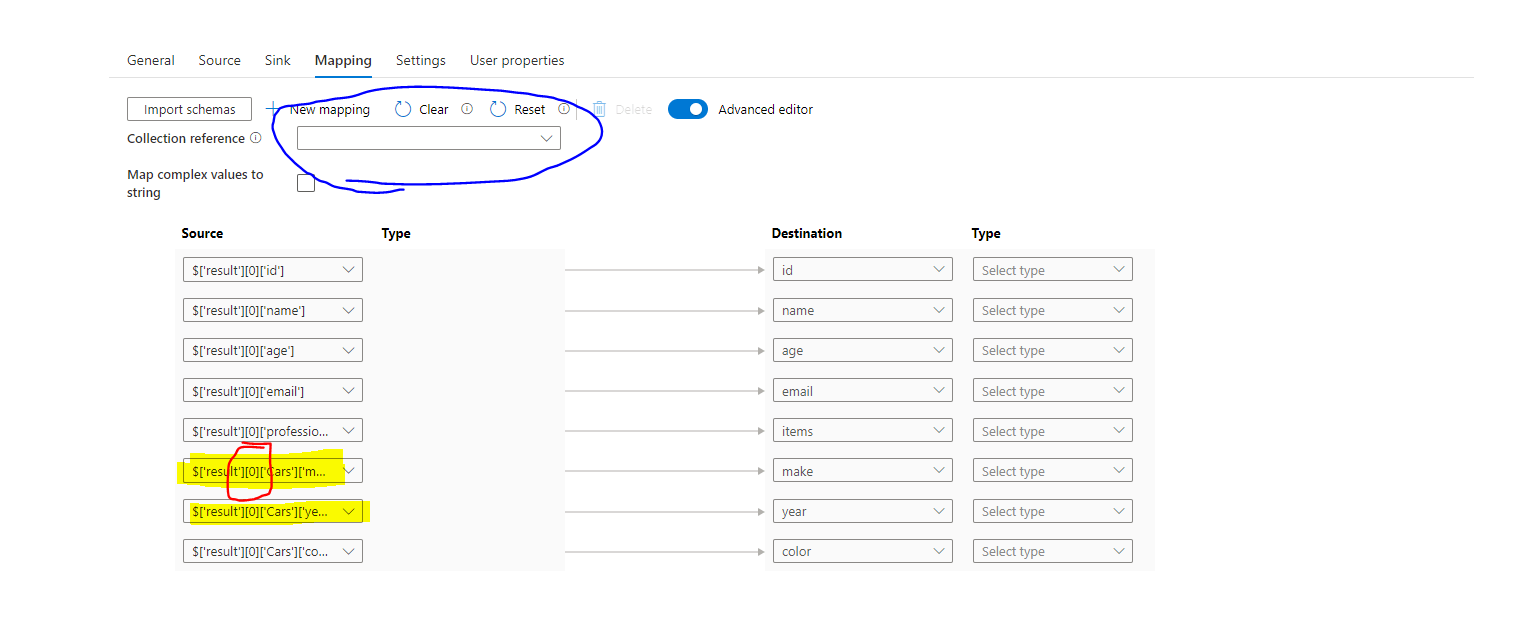
If you look at the mapping closely from the above figure, the nested item in the JSON from source side is: 'result'][0]['Cars']['make']. This means the copy activity will only take very first record from the JSON. If you execute the pipeline you will find only one record from the JSON file is inserted to the database. So, it's important to choose Collection Reference.