

SQL Server 2019 big data cluster is in preview and will include Apache spark and Hadoop Distributed File System (HDFS). This new architecture of SQL 2019 that combines structured and unstructured data processing engines is called a big data cluster. You can find more details at this link: https://docs.microsoft.com/en-us/sql/big-data-cluster/big-data-cluster-overview?view=sqlallproducts-allversions
Sign up for SQL 2019 Big Data Cluster
To gain access to the images that form the crux of the SQL 2019 big data cluster, the customer will need to sign up at https://sqlservervnexteap.azurewebsites.net/. Once the SQL team approves the request, you will receive a user name and password that will provide access to the containers.
Setting up a Client Machine in Azure
Go to the Azure Portal and create a VM with a Windows operating system. I used a Windows 10 Pro, version 1803 to build my client VM in Azure. You can find details about how to create a virtual machine in azure Here: https://docs.microsoft.com/en-us/azure/virtual-machines/windows/quick-create-portal. My portal configuration is shown here:
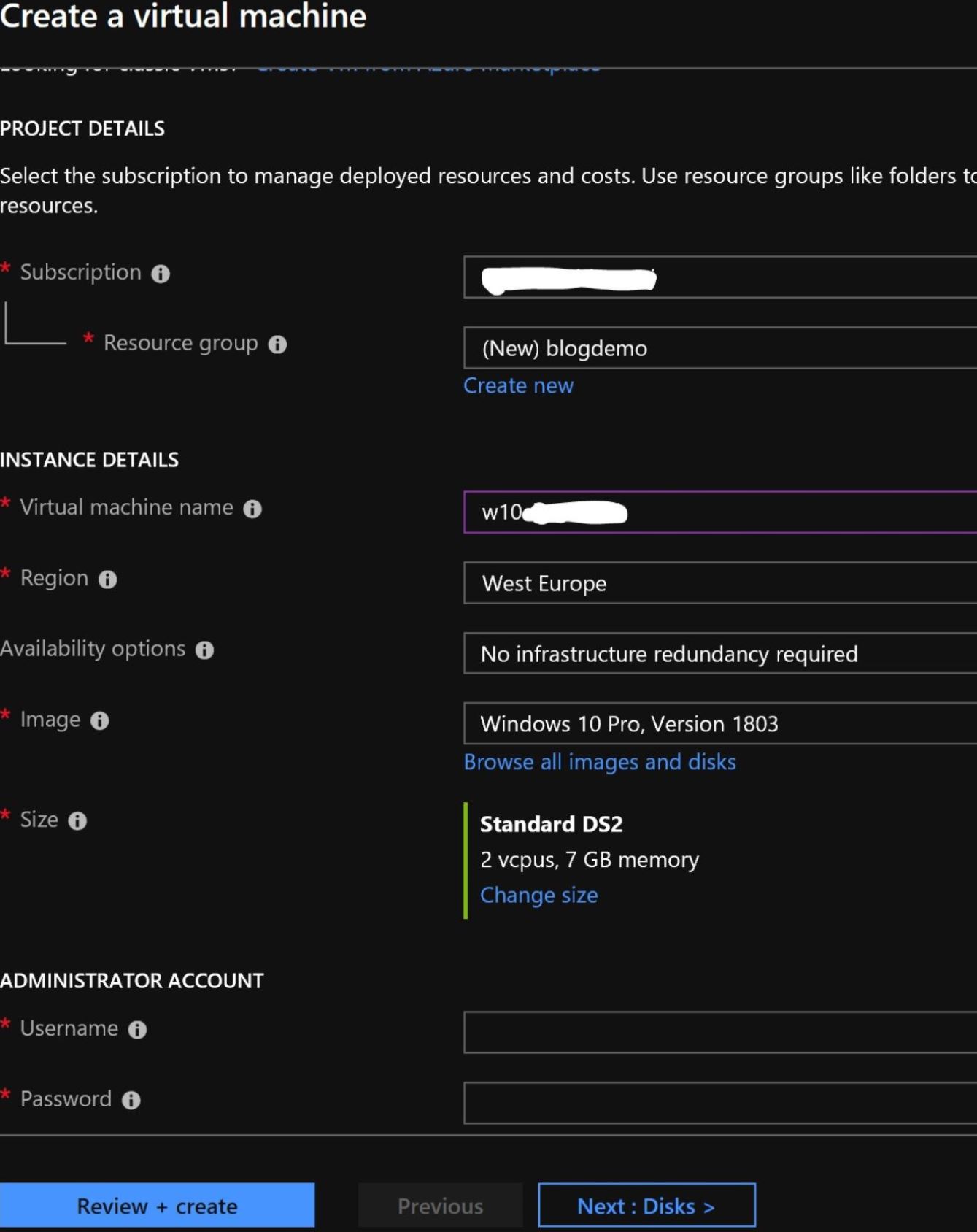
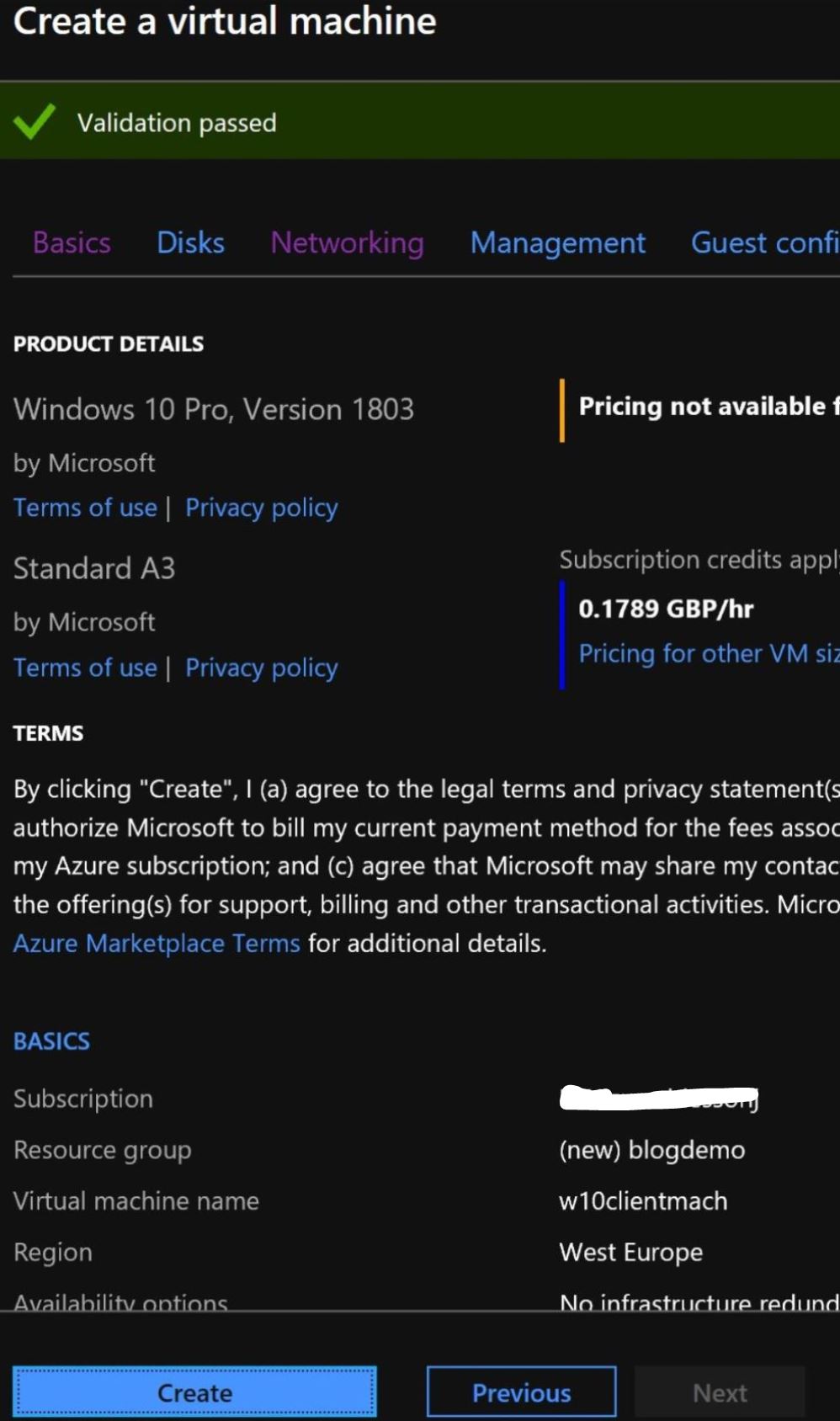
Once the validation is complete, click on the “Create” button to initiate the creation of your VM.
Install Pre-requisites on the Client
To use an AKS cluster, which is one of the many locations where a SQL 2019 big data cluster can be installed, we will need to install the kubectl and mssqlctl CLI tools to manage the SQL Server big data cluster. Python v3 (or greater) and pip3 need to be installed before installing mssqlctl.
In addition to this, it will be good to install Azure Data Studio and the SQL Server 2019 extension. If you intend to use Azure CLI to create AKS cluster in Azure, you will also need to be install Azure CLI on the client machine. We cover each of these below.
Installing kubectl
On the client machine, open PowerShell window and paste the command
Install-Script -Name install-kubectl -Scope CurrentUser -Force
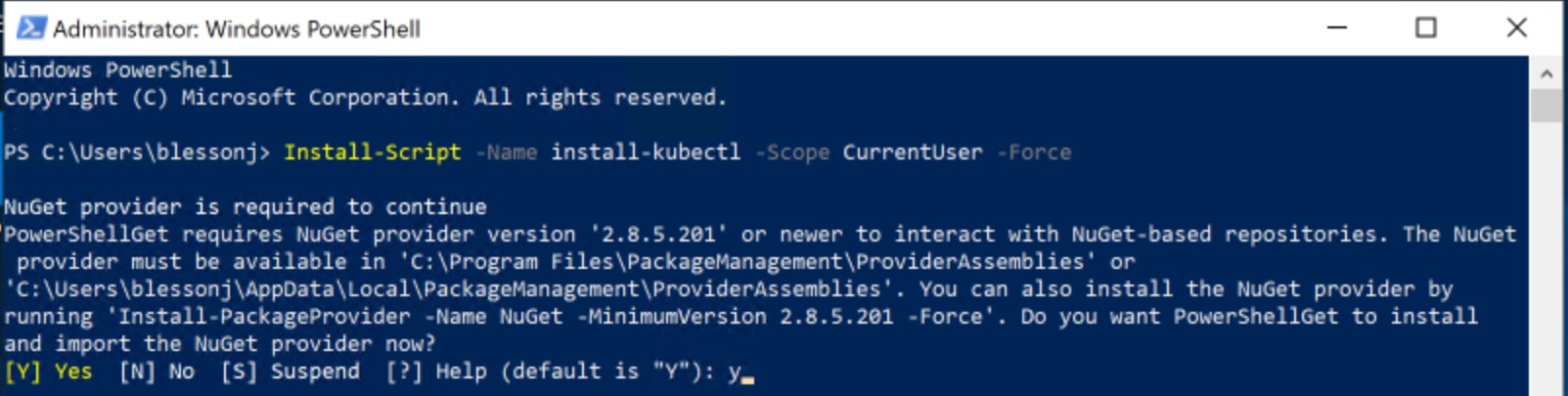
The script and associated artifacts are downloaded to the user’s documents folder.

You will need to make a small edit to the “install-kubectl.ps1” script to get it running. This is to add TLS 1.2. Add the following code just above the $uri statement.
[Net.ServicePointManager]::SecurityProtocol = [Net.SecurityProtocolType]::tls12
Your edited code will look like this

In the PowerShell window, go to the directory where Install-kubectl.ps1 is present and execute the command. A download directory needs to be provided for downloading components.
.\install-kubectl.ps1 -DownloadLocation "C:\PowerShell_Kubectl"

Also add the directory of kubectl to the user variable, path.
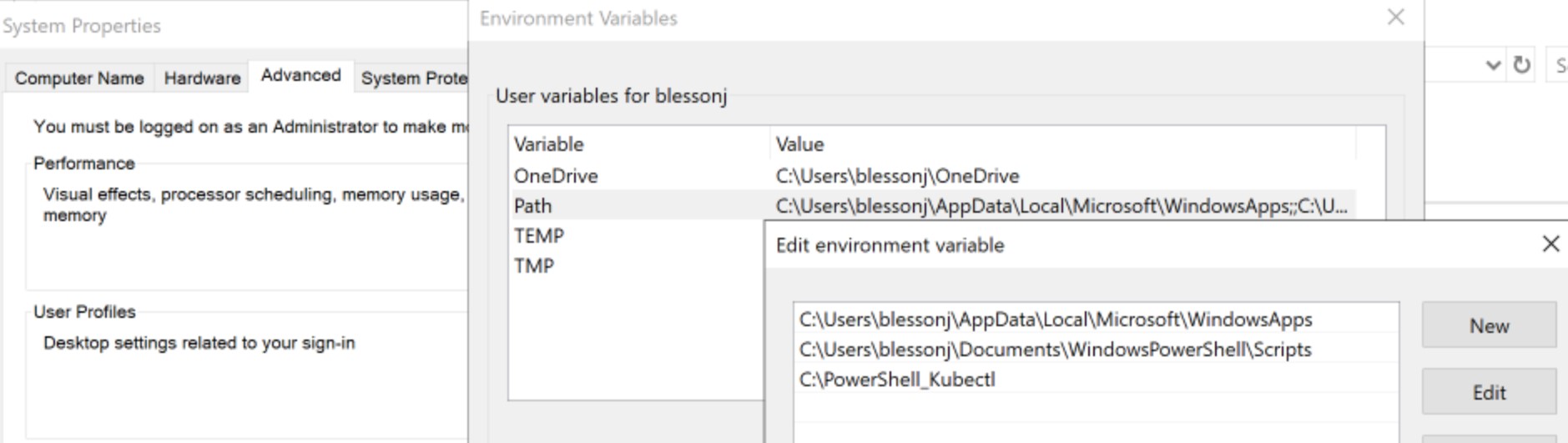
If you now open a new PowerShell window and execute the command "kubectl --help", the command will be recognized.
Installing mssqlctl
Install the pre-requisites for installing mssqlctl before installing mssqlctl. You will need to install python v3 or greater and pip3. Python can be downloaded here: https://www.python.org/downloads/. pip3 gets installed automatically if Python 2 >=2.7.9 or Python 3 >=3.4 is used.
Once installation is complete, issue the following command in a new PowerShell window.
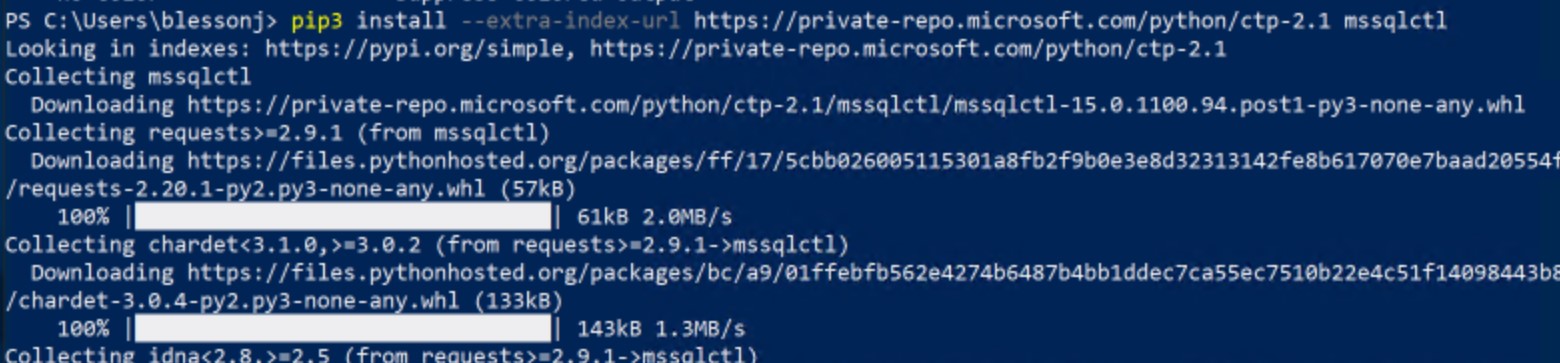
pip3 install --extra-index-url https://private-repo.microsoft.com/python/ctp-2.1 mssqlctl
Installing Azure Data Studio and SQL 2019 extension
Download Azure Data studio and use the GUI to install the tool. You can download this from https://docs.microsoft.com/en-us/sql/azure-data-studio/download?view=sqlallproducts-allversions.
The steps to download and install the SQL 2019 extension are located here: https://docs.microsoft.com/en-us/sql/azure-data-studio/sql-server-2019-extension?view=sqlallproducts-allversions
Installing Azure CLI 2.0
Optionally, if you are planning to use Azure CLI to create the AKS cluster in Azure, you will need to install Azure CLI 2.0. The steps and msi are located here: https://docs.microsoft.com/en-us/cli/azure/install-azure-cli-windows?view=azure-cli-latest.
Now, all the required components for the client machine have been installed.
Overview of AKS cluster and SQL 2019 big data cluster
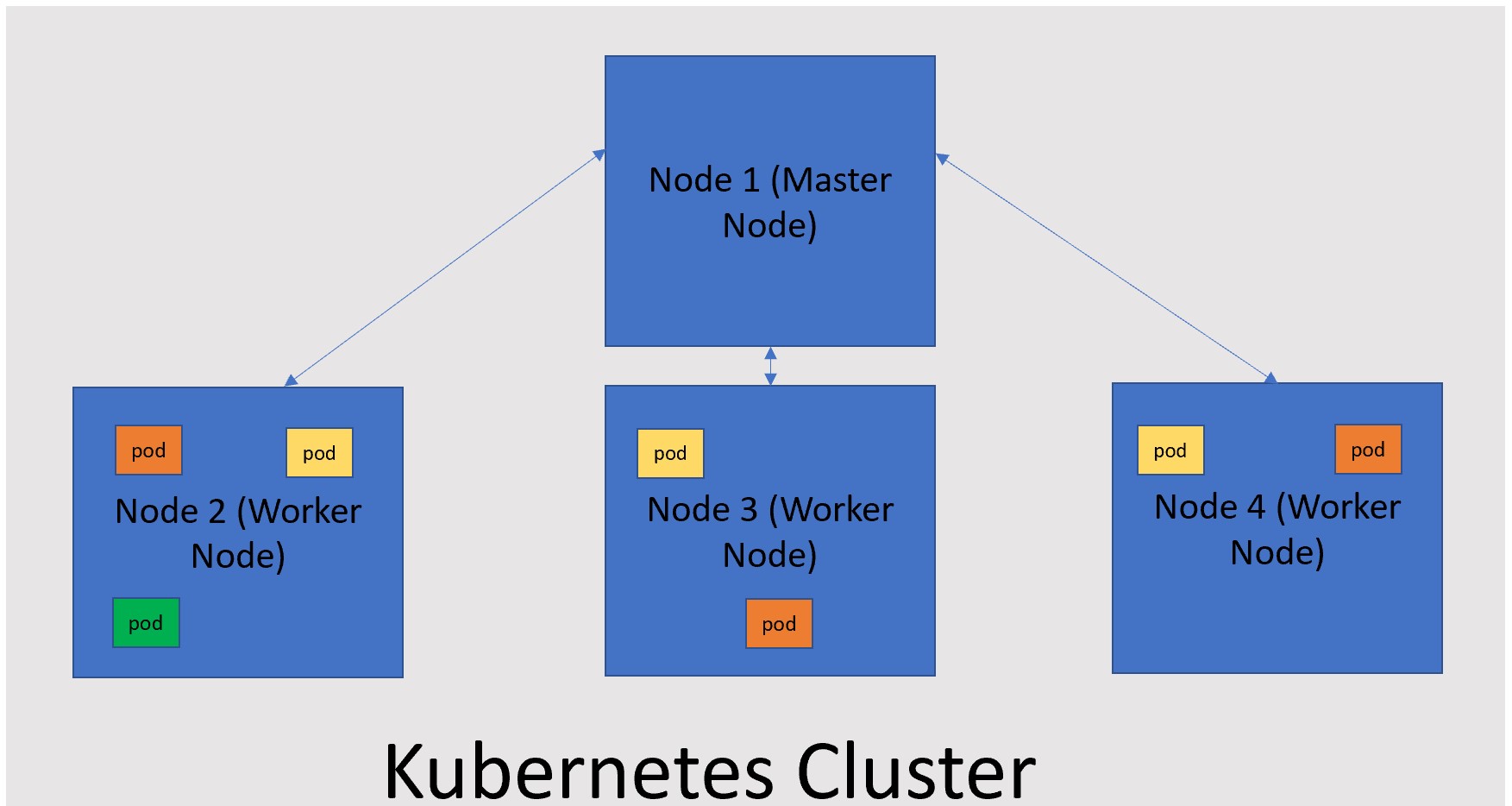
The SQL big data cluster is a cluster of Linux containers orchestrated by Kubernetes. Kubernetes is an open source container orchestrator and helps scale according to the workload requirements. There are three important terminologies to understand:
| Cluster | A combination of master node and worker nodes form the Kubernetes cluster. The master node distributes work to the worker nodes and monitors the health of worker nodes. A cluster can have a combination of physical or virtual machines. |
| Node | A node could be a physical or virtual machine. A node hosts the containerized application |
| Pod | A pod is a logical grouping of containerized applications and associated resources. A node can host more than one pod. |
Below is a pictorial representation of a Kubernetes cluster
When it comes to SQL 2019 big data cluster, Kubernetes is responsible for not only the health but also the build and configuration of the cluster nodes as well as assigning the pods to the nodes. These are three logical planes for a SQL 2019 big data cluster: the control plane, the compute plane and the data plane.
The control plane provides management and security. The master instance of SQL and master node of Kubernetes cluster are running in this plane. The Compute plane has the SQL Server in Linux pod. This layer is responsible for computation. Finally, the data plane is responsible for data persistence and caching. It contains the SQL data pool, and storage pool.
Installing an AKS cluster
You will be able to install the AKS cluster using either CLI or Azure portal. The steps to install AKS cluster using the CLI is provided here: https://docs.microsoft.com/en-us/sql/big-data-cluster/deploy-on-aks?view=sqlallproducts-allversions.
The pre-requisite steps can be skipped as they have been completed on the client machine. The cluster I created has 4 nodes and the command is as follows
az aks create --name kubcluster --resource-group sqlbigdatacluster --generate-ssh-keys --node-vm-size Standard_L4s --node-count 4 --kubernetes-version 1.10.8
Save the output in a json file. To configure kubectl to connect to the cluster issue the following commands
az aks get-credentials --resource-group sqlbigdatacluster --name kubcluster

You can verify the connectivity/status by issuing the command:
kubectl get nodes

Installing SQL 2019 big data cluster on AKS cluster
Now that the AKS cluster has been created and the client machine can connect to the cluster, we will be able to initiate the process of installing SQL 2019 big data cluster. The steps are located here: https://docs.microsoft.com/en-us/sql/big-data-cluster/quickstart-big-data-cluster-deploy?view=sqlallproducts-allversions.
You will be able to skip the pre-requisite steps as they have been completed. You can start by defining the environment variables. Since the client machine is using the Windows OS, it is imperative not to use double quotes around the values. For example, the first variable that needs to be set is SET ACCEPT_EULA=Y. Do not put double quotes around Y.

Once the environment variables are set, issue the command
mssqlctl create cluster sql2019bigdataclus

While the SQL 2019 big data cluster is being created, the status of the process can be checked by using the following commands
kubectl get all -n <your-cluster-name>
kubectl get pods -n <your-cluster-name>
kubectl get svc -n <your-cluster-name>
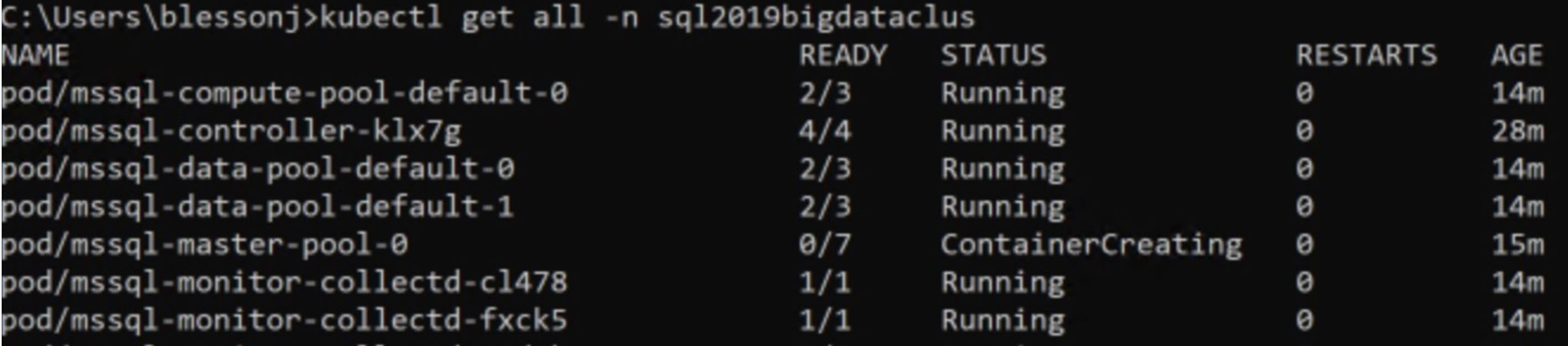
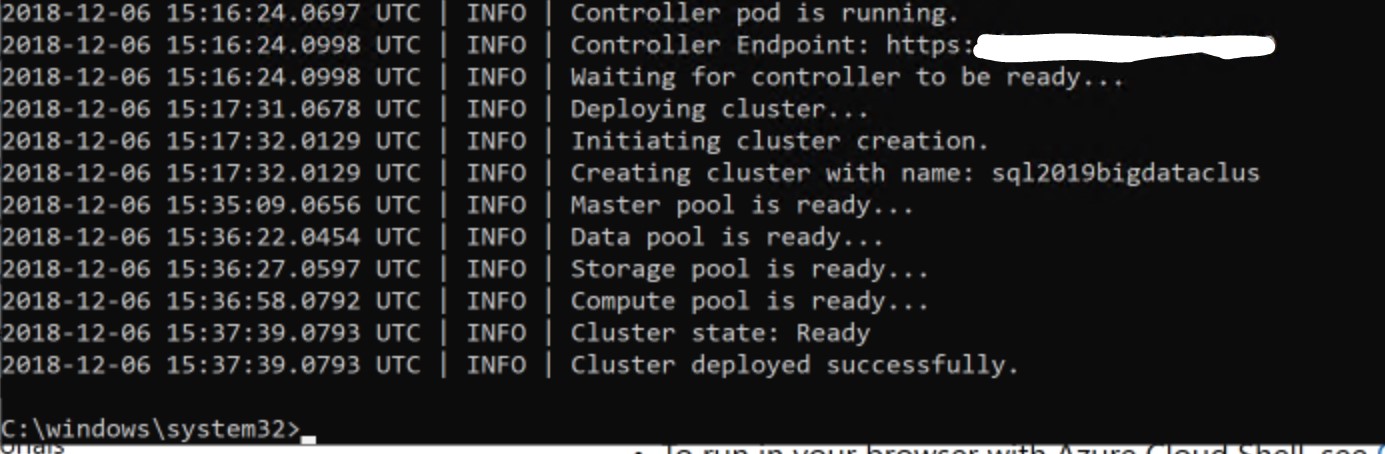
When the process completes, you will see the outcome as follows
Connecting to cluster admin portal and big data cluster
After the cluster has been created successfully, you can connect to the cluster admin portal using the external ipaddress of service-proxy-lb and port number 30777. Use the CONTROLLER username and password to login to the cluster admin portal.

The portal login page will look like the one below:
Once logged in, the cluster admin portal will look like the one below

For more details about cluster admin portal, see this link: https://docs.microsoft.com/en-us/sql/big-data-cluster/cluster-admin-portal?view=sqlallproducts-allversions.
You can obtain the ipaddress of the SQL master instance and the big data cluster by using the command
kubectl get svc service-master-pool-lb -n <your-cluster-name>
kubectl get svc service-security-lb -n <your-cluster-name>
You will need to use the external ipaddress for service-master-pool-lb to connect to the SQL master instance. The port number is 31433. To connect to the big data cluster, use the external ipaddress for service-security-lb. The port number is 30443.

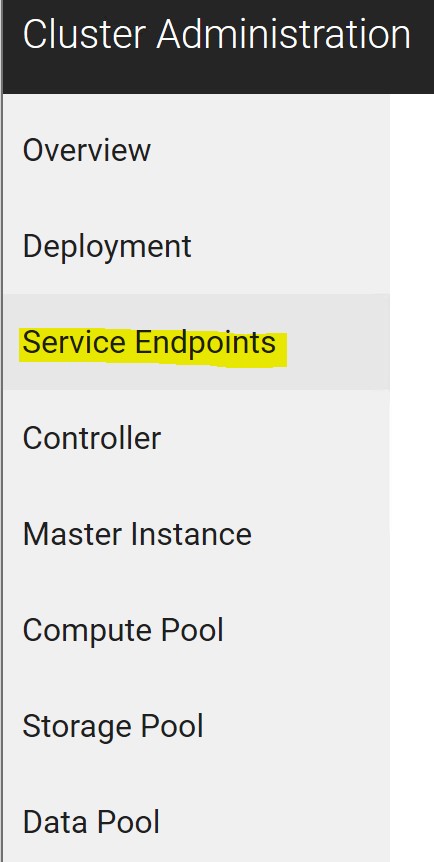
All the service endpoints can be found in the cluster admin portal. My portal is shown below.
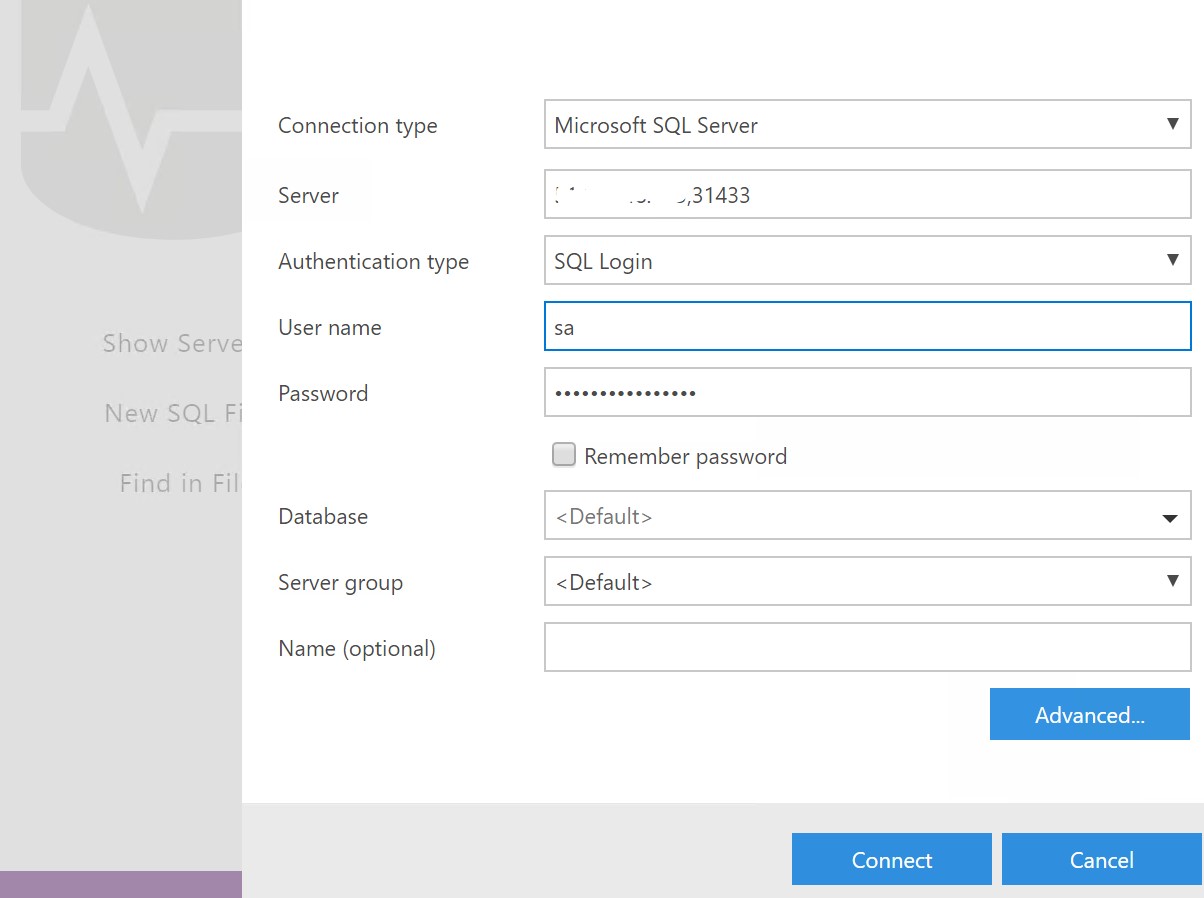
You can use Azure Data Studio to connect to both the master instance and big data cluster. Here I have entered my details in ADS.
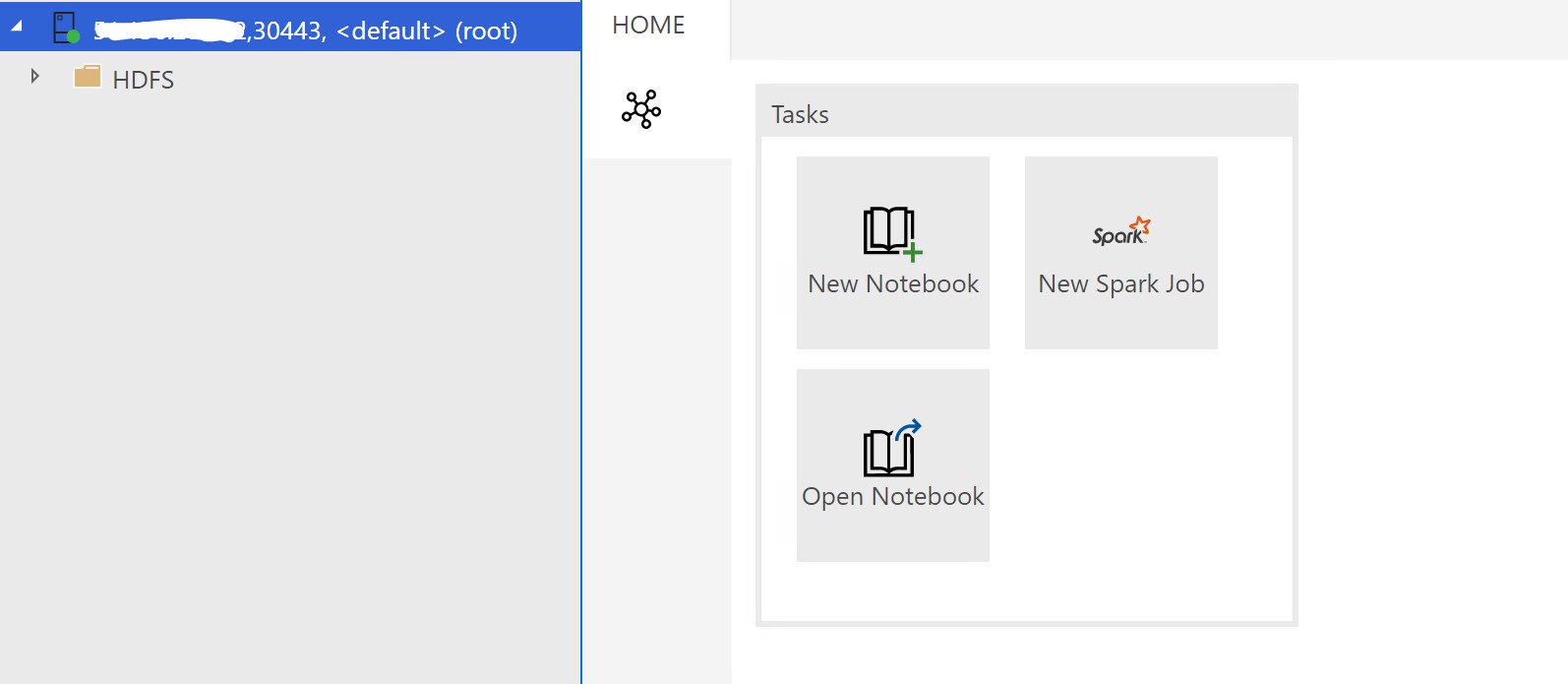
Once connected, I get a Server Dashboard with some information displayed.

When connecting to the big data cluster, pick “SQL Server big data cluster” as the type of connection.

You will get a different view after making this connection.
Conclusion
SQL Server 2019 big data cluster is a great addition to SQL Server family. This offering has the potential to cater to different personas. It does not matter whether you are a fan of SQL or non-relational data sources such as HDFS/spark.
Further Reading
You will be able to find more information here: https://docs.microsoft.com/en-us/sql/big-data-cluster/big-data-cluster-overview?view=sqlallproducts-allversions

