

A common business need is to return results randomly ordered, or at least
ordered without an easily discernable pattern. For example, I have a friend who
wrote some code that would return a x percent sample of problem records and he
wanted to get the best sampling possible rather than just order by entry date or
some other criteria. Another example might be the need to randomly select a
record from a group of records - perhaps those that bought a ticket in the
Katie Winn Raffle. The technique presented here is common, but that doesn't
mean it's the best, or that it qualifies as true 'randomness', but I think
you'll find in most situations it will work just fine.
The trick is easy, just order by newid(), like this:
select top 1 donationid, firstname, lastname from donations order by newid().
The NewID function is built in to SQL and generates a GUID, also known as a
uniqueidentifier. It's comprised of various bits of information that together
guarantee it to be unique in the world. A nice side affect is that they come out
in ugly unordered fashion. To give it a try, run the following code:
declare @Loop int set @Loop = 0 while @LoopYou won't get these results, but you should see something equally random:
927CC86E-9E58-4BD9-98DA-A18BFAF7C163 DB66E4C9-9D82-44B4-956A-3DB4AEADD3B7 2B30EA77-1AA3-4165-AF28-7D0235B3D1DF 362DD55F-64EE-49C5-8698-631298D3501D 3E698D0A-4A9E-45CB-8472-C978A75EED86 59CA37A1-EAB2-4833-9500-12A0591038C1 27F8F855-7233-4933-ABD5-4EAB21F824F6 61292F4D-74D6-4219-9FAE-9D4F7B7C8DA8 F33DC80B-606A-4498-A01C-1C60BB13A78F 7CBA26F5-8143-4688-A6D8-6BA27F4860BCAn easy enough trick to apply, but rule number of performance tuning
definitely applies here - measure the results! For a first test, let's run the
following query in Adventureworks:
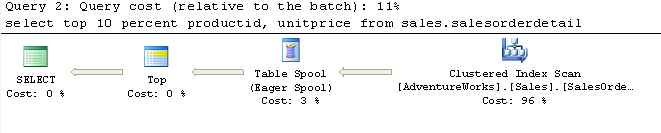
select top 10 percent productid, unitprice from sales.salesorderdetailThat gives us a query plan that looks like this:
And it costs about 248,000 reads on AW on my machine in it's current state,
but it still returns in under a second. Now if we just add the order by newid to
the query, we get this:
The reads jump up to about 278k. Yes, there is probably some room for tuning
there, but we can see that we ended up with a plan that was quite a bit
different when we used newid and it added about a 10 percent cost. I've seen a
query where removing the order by newid cut the query time in half, resulting in
savings of more than six minutes!
Please don't make the assumption that it's always a 10% decrease in
performance. I've seen instances where adding the order by actually made the
query run faster. If you use this technique and it does cause performance issues
you really have to work on it just like any other query that needs to be tuned,
but in general you should consider all of the following:

- Apply the newid order by as late in the process as you can. Have to be
careful that moving it doesn't negate the affect you were trying to achieve
- Consider adding a uniqueidentifier column to the table and indexing it,
or adding to one or more existing indexes. You could also just make the
uniqueidentifier a primary key, but that's a
different article
I hope you found this useful. Do you have other techniques for randomizing? I
look forward to your comments.